More accurate than GPT-4: How Snyk’s CodeReduce improved the performance of other LLMs

May 7, 2024
0 mins readSnyk has been a pioneer in AI-powered cybersecurity since the launch of Snyk Code in 2021, with the DeepCode AI engine bringing unmatched accuracy and speed to identifying security issues in the SAST space for the first time. Over the last 3 years, we have seen the rise of AI and LLMs, which Snyk has been at the forefront of with the introduction of new AI-based capabilities, such as Snyk Agent Fix, our vulnerability autofixing feature, or our third-party dependency reachability feature.
We recently announced big model improvements in Snyk Agent Fix, a beta feature that automatically fixes security issues identified by Snyk Code. Snyk Agent Fix combines the latest AI technology and expert in-house capabilities to generate reliable fixes. Fixing security issues is complex, so to learn more about how we do this, we will deep-dive into the research paper that explains the star ingredients behind Snyk Agent Fix - CodeReduce technology and our curated security fix dataset.
Automating security fixes – a complex problem
Developers often dedicate large amounts of time to finding and fixing security issues independently. Before DeepCode AI, Snyk Code helped developers with the initial step of identifying the issues, but even then, the next step of fixing security issues could be challenging and time-consuming because developers were, and still are, frequently untrained in security. Fixing security issues means developers have to review the code manually, figure out how it is supposed to work, understand the security issues within the context of the code, and then research how to remediate them before actually fixing the problem.
Automated security issue fixing, or “auto-fixing,” has been top-of-mind for many companies over the years, with the aim of reducing the bulk of remediation work. However, despite many attempts, creating a solution with accurate fixes proved difficult. As a result, most autofixing tools focused on addressing just a small set of issues, trivial changes involving just a few lines of code, or mere formatting issues.
With the advent of LLMs, we saw the potential of building a better auto-fixing capability with the new generation of AI. However, even LLMs have limitations on how they can remediate security issues if they are not set up sufficiently for the desired results. Most LLMs have been trained with a wide variety of data and code, but not specifically on security remediation. And this meant two key problems for us:
For something as specific as security auto-fixing, LLMs require a specialized dataset of security and semantic code fixes to learn from to produce relevant and accurate code fixes.
Hallucinations and LLMs’ ability to process limited context each time that they generate an output means that adding more code to prompts to guide a “general-purpose” LLM (versus one specifically trained for security) towards more accurate outputs does not always offer better results.
Addressing LLMs’ limitations to produce better fixes
We decided that the benefit of using LLMs outweighed the work it would take to address the identified issues, so we took it upon ourselves to solve them.
Fix dataset
We built a comprehensive dataset of open source security fixes to ensure we get the best possible results. First, we performed extensive labeling of open source commits and constructed a clean dataset of issues and fixes for JavaScript (since then, we have done the same with other languages such as Java, Python, C/C++, C#, Go, and APEX). Second, instead of manually adding more labeled data, we used Snyk Code’s program analysis features from our DeepCode AI Engine to efficiently produce the same quantitative effect as labeling data to construct clean datasets.
CodeReduce technology (patent-pending)
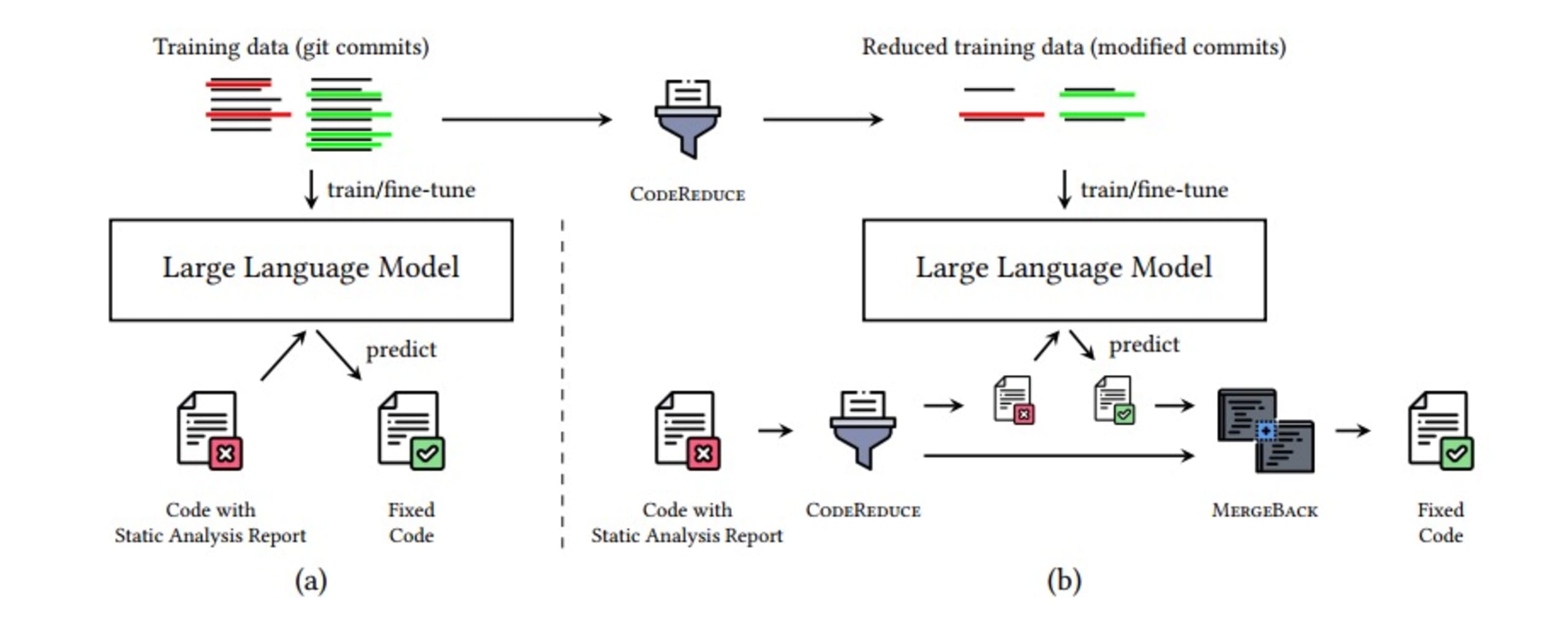
CodeReduce leverages program analysis to limit the LLM’s attention mechanism to only the portions of code needed to perform the fix by focusing the LLM on a shorter snippet of code that contains the reported defect and the necessary context. This drastically reduces the amount of code that the LLM needs to process, which in turn helps to improve the fix generation quality across all tested AI models and reduces hallucinations. Moreover, passing less information through the model speeds up its processing. It enables real-time fix generation, so you will not only get more accurate and relevant fixes, but you will also get faster fixes.
The process for CodeReduce includes the following steps:
Identify the security issue
CodeReduce it to the minimum required code with context
Add CodeReduced code to the LLM prompt and generate a fix
Apply the fix
Use Snyk Code’s scanning capabilities to re-check that Snyk Agent Fix has fixed the vulnerability and that no new vulnerabilities have been introduced by the fix(es)
MergeBack the fix to the original code
Putting it all together, the image below sets out what the pipeline for automatic security issue fixing looks like — all of which happens in a matter of seconds, thanks to additional optimizations you can read about in the research paper on CodeReduce.
What are the results?
With these problems solved, we needed to test how well our automatic security fixes worked, so we created a benchmark that could be used across different LLMs.
We carried out our evaluations using “Pass@𝑘” and “ExactMatch@𝑘” metrics for models that use CodeReduce (as indicated by the ‡ symbol in the table below) against baselines of TFix, a window-based model, and various large-context models, like GPT-3.5 and GPT-4.
The “k” variable in “Pass@k” measures how many (ranging from at least one fix to all 5 fixes) of the 5 fixes generated each time address the relevant security issue and do not introduce any new security issues.
We also defined 5 categories of security issues to test against:
AST: Vulnerabilities that require an abstract syntax tree but not dedicated data flow
Local: Incorrect values flowing into methods that would not accept them
FileWide: Signatures or implementation issues
SecurityLocal: API usage, tracking of method calls
SecurityFlow: Complex taint analysis requiring complex data flow
We also chose various LLMs – StarCoder, Mixtral, T5, GPT-3.5 and GPT-4 – for comparison. The results were the following:
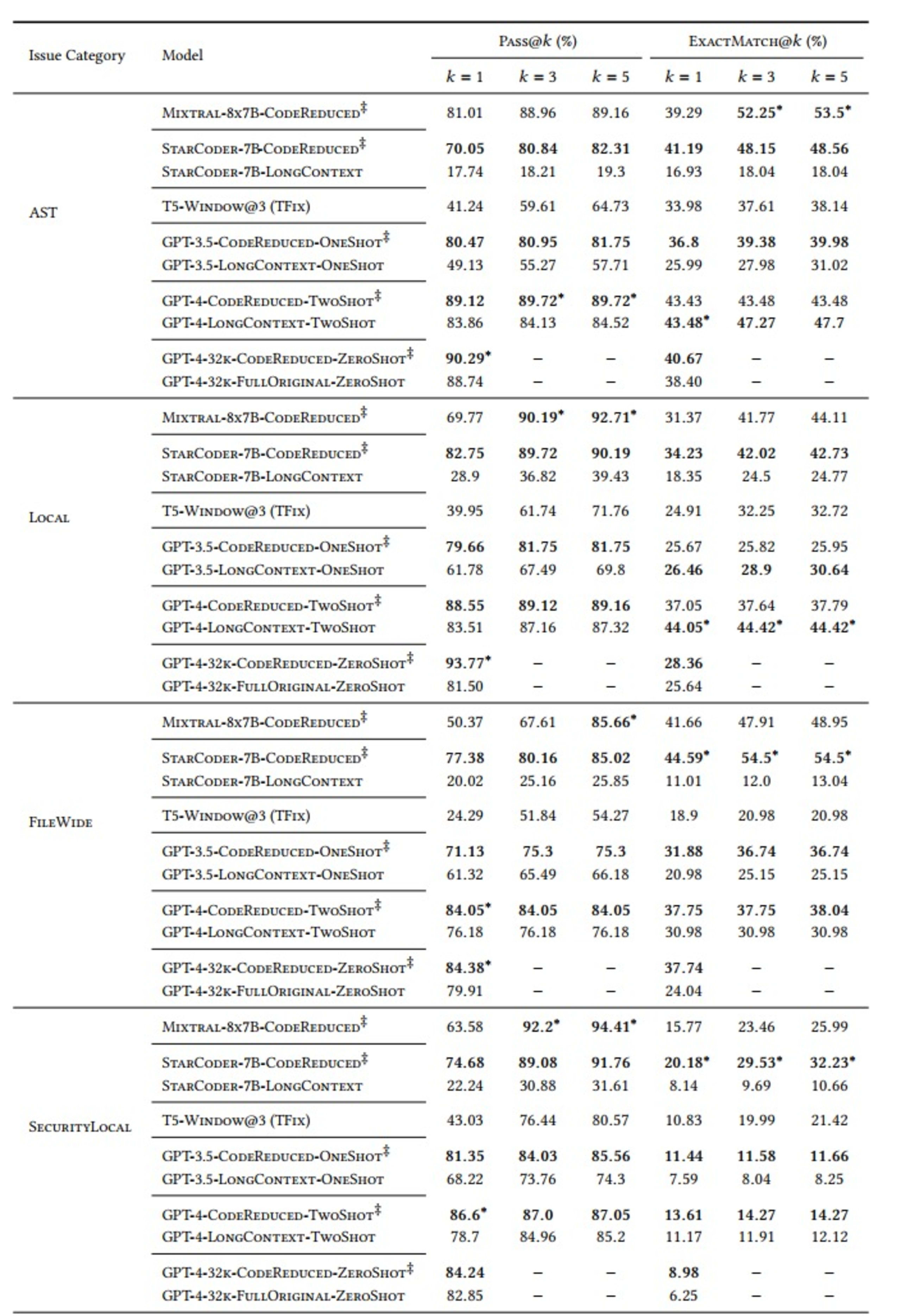
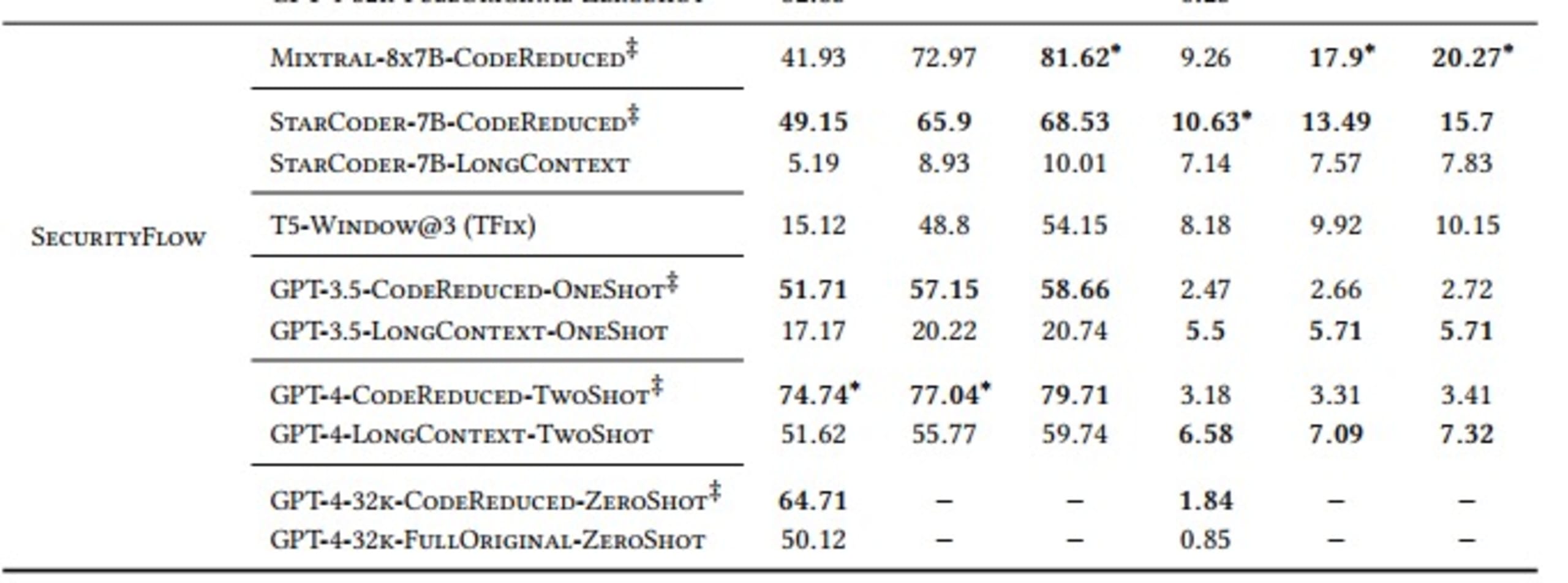
As demonstrated in the table, models that would ordinarily learn the complex long-range dependencies needed to produce a correct fix perform significantly better when using the code context extracted by CodeReduce than when producing fixes without the help of CodeReduce. A good example is the vast improvement in the Pass@5 result for fixing AST issues when using the StarCoder model, going from a 19.3% success rate (without CodeReduce) to 82.31% (using CodeReduce).
Key takeaways
Overall, Snyk Agent Fix outperformed the previous state-of-the-art baseline set by TFix and helped multiple popular AI models in different setups perform better. This is because Snyk Agent Fix utilizes program analysis through Snyk’s proprietary CodeReduce technology to deal with long-range dependencies and data flows. In this way, Snyk Agent Fix greatly simplifies its task of learning about the relevant security issues by narrowing the focus of its attention, resulting in more precise, relevant fixes.
You can now experience Snyk Agent Fix’s powerful functionality in the IDE by registering for Snyk Code and turning on “Snyk Code Fix Suggestions” in the Snyk Preview settings. More information is available in our documentation, and you can help shape the future of Snyk Agent Fix by providing user feedback on our fixes within Snyk Code.
Get started in capture the flag
Learn how to solve capture the flag challenges by watching our virtual 101 workshop on demand.