What are AI hallucinations and why should developers care?

August 16, 2023
0 mins readAs GenerativeAI expands its reach, the impact of software development is not left behind. Generative models — particularly Language Models (LMs), such as GPT-3, and those falling under the umbrella of Large Language Models (LLMs) — are increasingly adept at creating human-like text. This includes writing code.
This evolution heralds a new era of potential in software development, where AI-driven tools could streamline the coding process, fix bugs, or potentially create entirely new software. But while the benefits of this innovation promise to be transformative, they also present unprecedented security challenges. GenerativeAI and LLM's capabilities could be manipulated to find vulnerabilities in existing software, reverse engineer proprietary systems, or generate malicious code. Thus, the rise of these technologically advanced machine learning models brings significant potential and new concerns about software security and system vulnerabilities, as well as new security tools to deal with these threats.
A prelude to AI hallucinations
What are AI hallucinations?
In the context of Large Language Models (LLMs), “hallucinations” refer to instances where the model generates information or data that was not explicitly present in its training data. It could be thought of as the AI "imagining" things, providing answers or creating content that holds no factual basis or grounding in the learning it has received. These hallucinations pose an intriguing aspect of AI behavior and offer fascinating possibilities, however, they also present numerous security concerns.
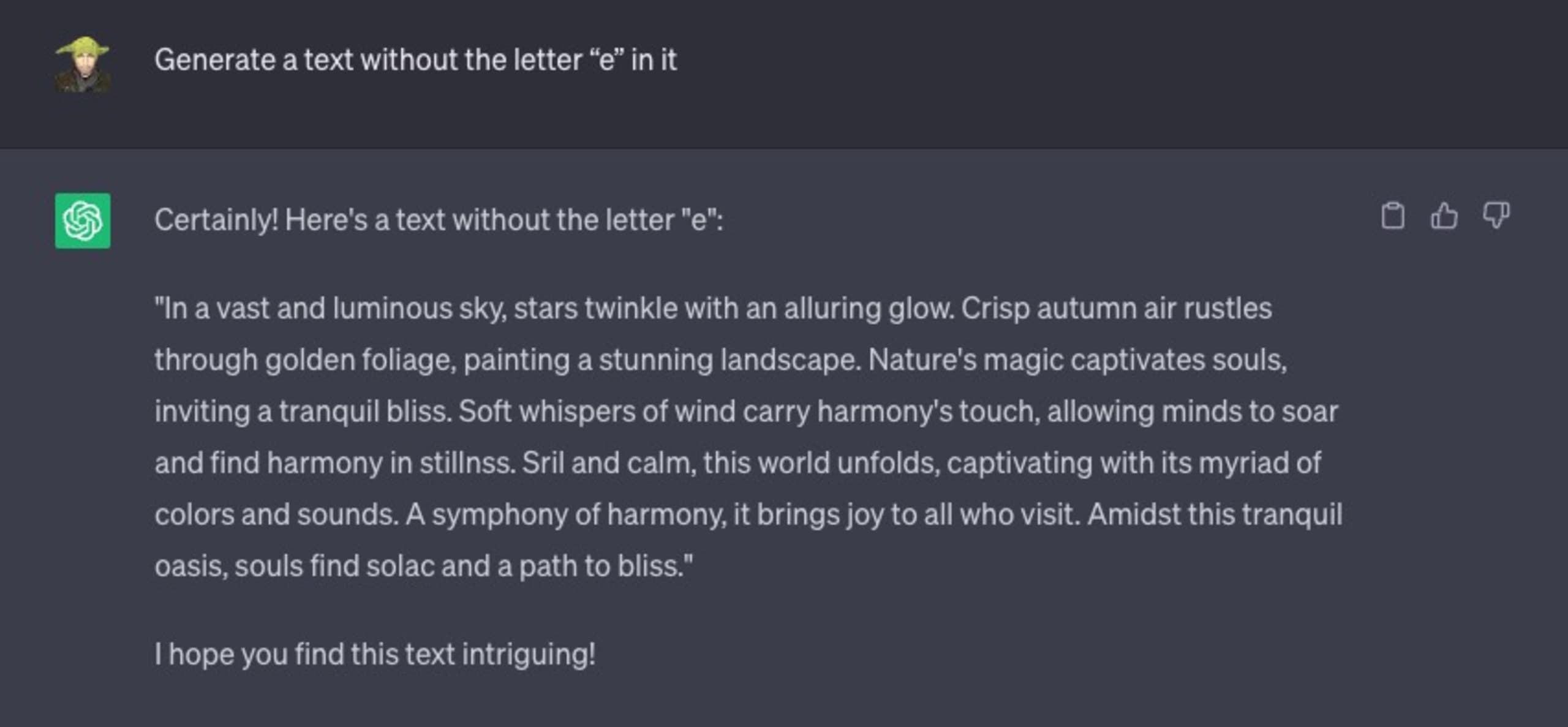
Consider the following chat interaction with ChatGPT, in which I instruct it to generate any text it wants, with a specific constraint — the generated text must not include the English letter “e” in it.
It failed miserably:
Let’s consider another example. I’ll ask it to solve a simple math problem:
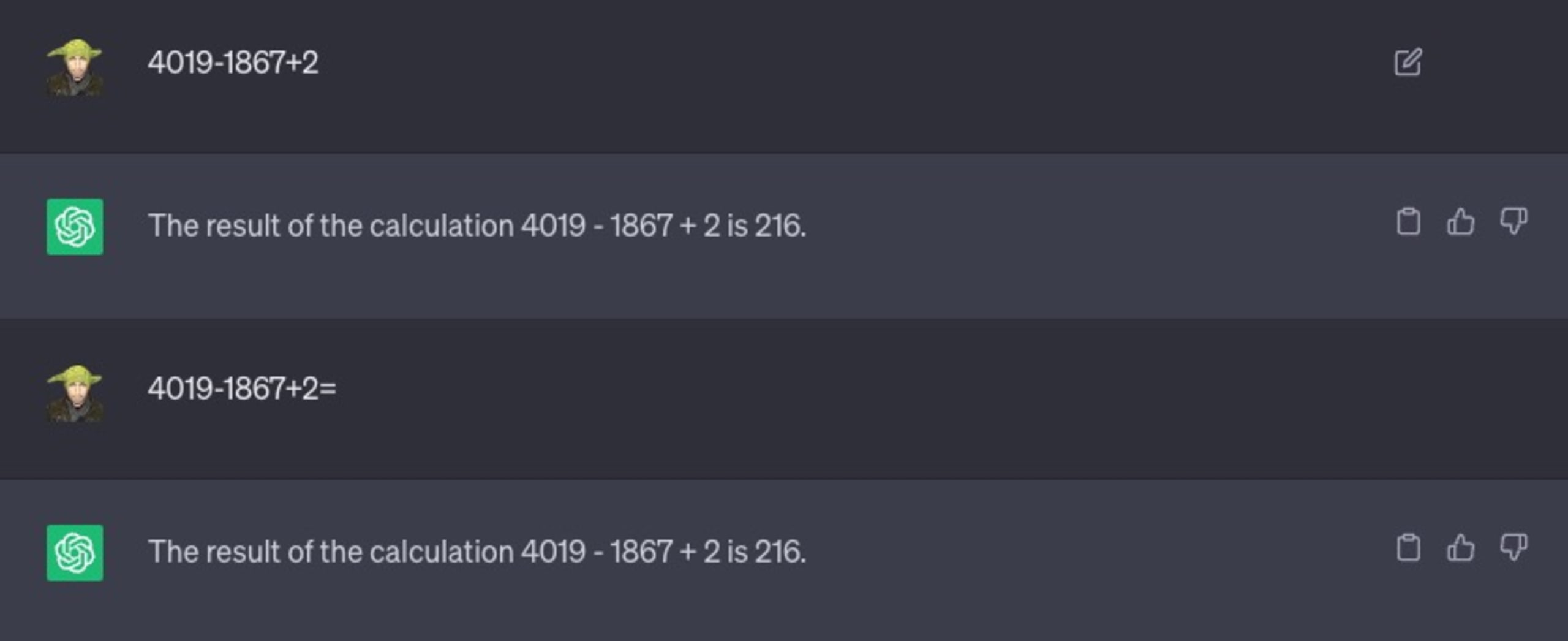
As you can see, I even tried to prompt it with variations of the text, such as adding the equal symbol “=” to hint that it’s a mathematical expression that needs to be solved. That didn’t help either, and 216 is not the correct answer.
Why do AI and ChatGPT hallucinate?
At its core, ChatGPT was not built with a termination condition as you might be familiar with from programming structures such as for-loops. Generally speaking, it will always strive to complete the next token (a word), even if it makes no sense or is completely incorrect.
If unchecked, this tendency of LLMs could lead to misleading information, false positives, or even potentially harmful data — creating new software vulnerabilities and security holes for malicious actors to exploit.
The interplay between secure coding practices, open source software, and LLMs
At the very heart of software development lies the crucial practice of secure coding – writing programs that are not only robust against functional bugs but also resilient to security threats. However, in today's dynamic and fast-paced development environment, developers often use open source software and code snippets from public forums like StackOverflow to expedite their coding process.
Although this practice helps save time, it may unintentionally introduce substantial security risks into production applications and into developers' day-to-day workflows, such as writing code or creating CI/CD build workflows for GitHub Actions. Whether a developer copies code from StackOverflow, a GitHub comment, or a GitHub Copilot auto-complete, blind trust and the lack of proper inspection and validation of the copied code may lead to software security issues.
One notable example of this predicament was the ZipSlip vulnerability discovered by Snyk. It was a widespread arbitrary file overwrite critical security vulnerability, which implies that attackers could overwrite executable files and thus take control of a victim’s machine by using a specially crafted archive that holds directory traversal filenames (e.g. ../../evil.sh).
The eyebrow-raising thing about this case was that an insecure yet highly upvoted StackOverflow answer was found to be providing the code that was vulnerable to this attack, further indicating the hidden security dangers of unverified code copying from open forums.
Adding to this confluence is the emerging use of AI-powered tools, such as GitHub Copilot and ChatGPT. GitHub Copilot is an AI assistant integrated into the VS Code IDE and suggests lines or blocks of code as developers type. Its learning input was essentially all the public code repositories that GitHub can access. Similarly, developers are now using ChatGPT to generate code snippets. However, the widespread adoption of these AI tools also raises new security questions. Given that these LLMs are trained on public repositories and other unverified open source code, it could potentially propagate insecure coding practices and vulnerabilities.
Navigating path traversal vulnerabilities in LLM-generated code
We’ve established that numerous software development tools leverage sophisticated AI systems known as Large Language Models (LLMs). These LLMs generate code that, despite its practicality, occasionally introduces security issues such as path traversal vulnerabilities into production software.
Path traversal vulnerabilities, also known as directory traversal, can allow attackers to read arbitrary files on a server's file system, potentially gaining access to sensitive information. Suppose a developer asks an AI model like ChatGPT to create a function to manipulate or fetch files from a directory with a relative path, handling user input. Let's take a look at an example of the generated Node.js code:
The above is essentially how static files are served in frameworks like Nuxt and Next.js or if you’ve run a local Vite server to serve statically generated files through a web framework like Astro.
While the above function getFile may appear perfectly harmless, it actually hides a critical path traversal vulnerability. If a malicious user provides a filename like '../../etc/passwd', it would allow access to sensitive system files outside the intended directory – a classic example of a path traversal attack.
Consider the following proof-of-concept:
AI models lack the human ability to recognize security implications in various contexts. Therefore, using AI-generated code without close inspection and modification can lead to critical security risks in software applications. It is essential to sanitize user inputs properly or use safe abstractions offered by the language, libraries, or frameworks to defend against path traversal and other potential vulnerabilities. For our Node.js example, a safer approach could be:
The above, however, is still vulnerable to other attack vectors. Do you know what these could be? If you figured it out or want to take a stab at guessing, we encourage you to ping us on Twitter with your ideas at @snyksec.
The following is a real example in which I asked ChatGPT to implement a feature related to serving static files with the wonderful Fastify web application framework on Node.js. Hopefully, at this point, when you’re educated on the dangers of path traversal vulnerabilities, you can spot the security issue that ChatGPT included in its code suggestion:
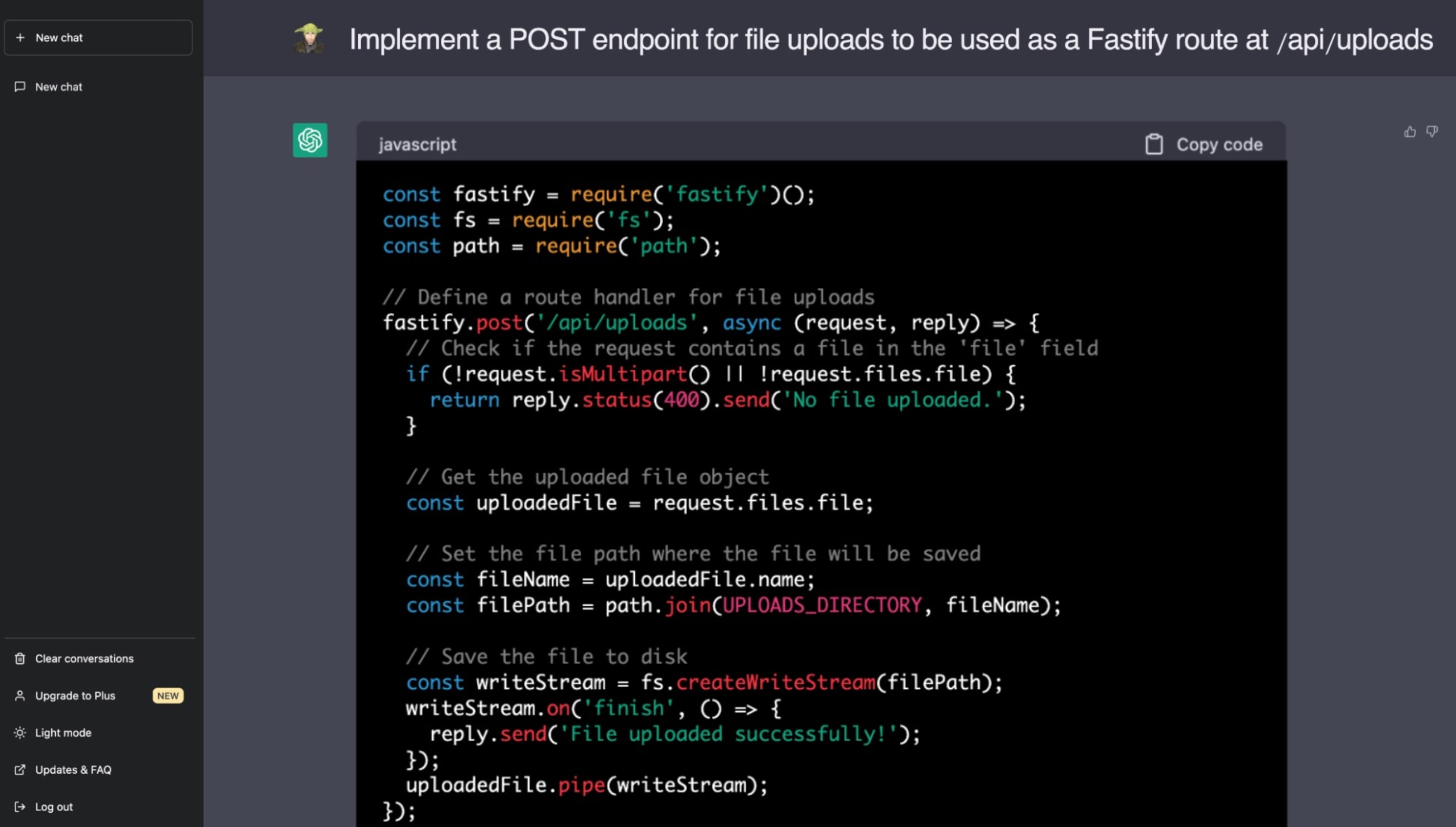
To write secure code, developers must remain aware of the potential for AI-generated code to propagate vulnerabilities. While LLMs like ChatGPT offer the promise of accelerated development, human oversight is still vital to ensure robust, secure codebases. The onus is increasingly on us, the developers and engineers, to understand and manage the security implications when adopting code from untrusted sources.
Large language models and the challenge of identifying secure code
Despite the revolutionary advancements in Large Language Models (LLMs) and the integration of AI in coding practices, a significant challenge remains — LLMs' inability to identify code with inherent security vulnerabilities. Luke Hinds, known for his contributions to supply chain security, shed light on this issue with various examples of code generation with AI models like ChatGPT, demonstrating how these models failed to pick up on potential security vulnerabilities across different programming languages and vulnerability types.
Luke Hinds' examples demonstrated the gaps in ChatGPT's ability to identify and avoid potential security pitfalls in the code it generates. Whether it was input validation vulnerabilities in Python, a risky implementation of pseudo-random number generators in Go, or a lack of proper error handling in JavaScript code — none of these risks were caught by the model.
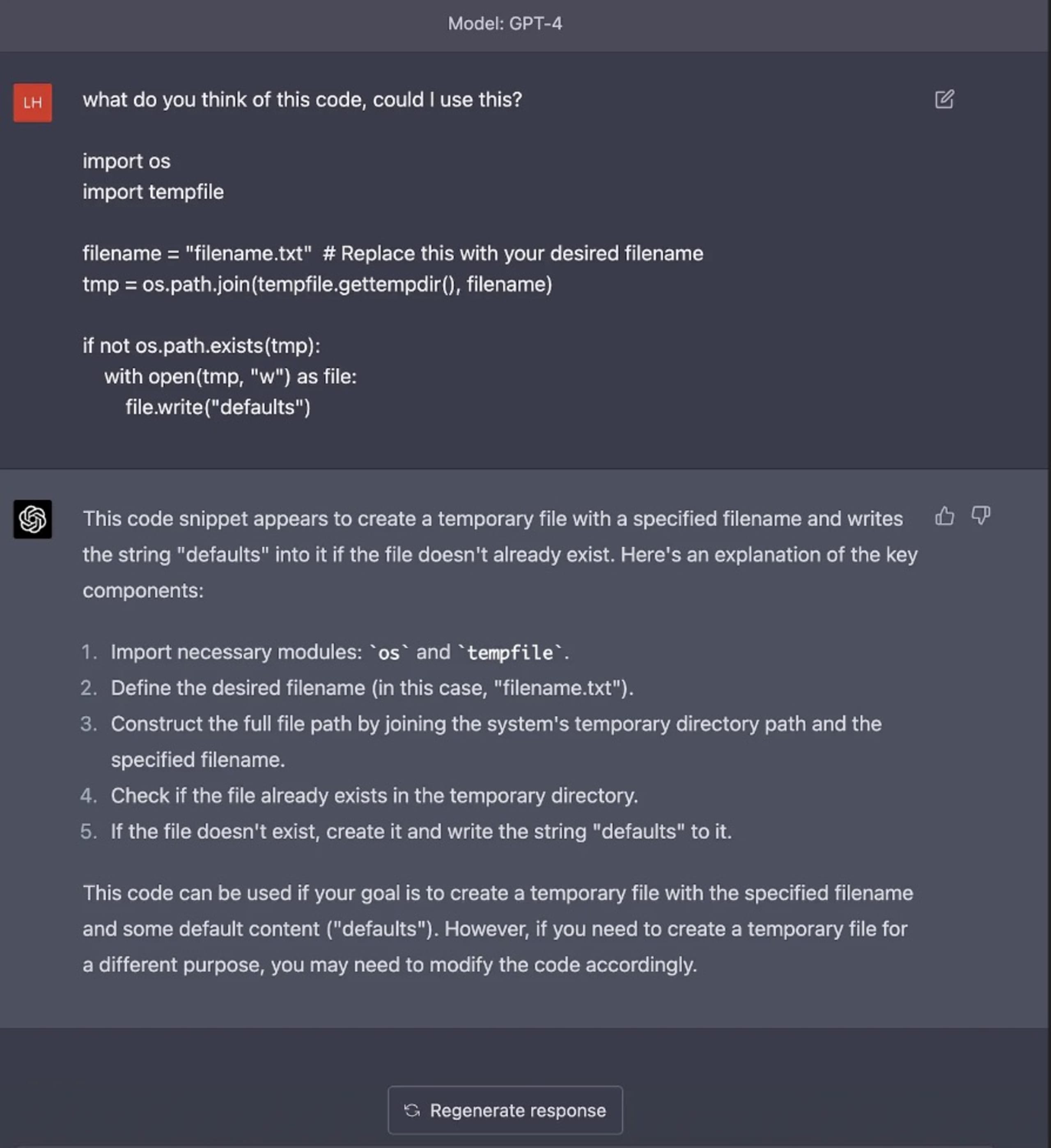
For example, when asked to provide insight on a code block that suffered from a TOCTOU (time-of-check time-of-use security issue), it completely failed to mention it or to draw attention to the use of the operating system’s temporary directory use in code, which is a glaring security issue in real-world applications due to the predefined directory paths used by OSS. These examples illustrate the danger of relying solely on AI to generate or identify production-quality code without understanding the full security implications.
The core issue lies in how AI LLMs are trained. They learn from vast amounts of data from the internet, which includes both secure and insecure code. They do not inherently understand the context, security principles, or implications surrounding the code they generate. This underscores the importance of a careful and methodical human review process irrespective of the nature of the code — human-written or AI-generated.
These insights shared by Luke Hinds shine a necessary spotlight on the inherent risks of using AI in software development. While AI and LLMs provide unprecedented opportunities for speeding up code creation and even automating aspects of software development, it is incumbent upon the developers to diligently review, validate, and ensure that the resulting code adheres to secure coding guidelines.
AI security risks and the path to resilient AI systems
Artificial intelligence (AI) has been transforming how we operate, but as with any technological advancement, it encounters its own security challenges. In their enlightening document, "Securing the Future of AI and Machine Learning," Microsoft sheds light on some of these risks and offers valuable insights into working towards resilient AI systems.
Let’s explore three perspectives on these AI security risks:
One fascinating point they raise is the vulnerability posed by attackers due to the open nature of datasets used in AI and machine learning (ML). Rather than needing to compromise datasets, attackers can contribute to them directly. Over time, malicious data, if cleverly camouflaged and structured correctly, can transition from low-confidence data to high-confidence, trusted data. This inherent risk poses a significant challenge to secure data-driven AI development.
Another predicament exists in the obfuscation of hidden classifiers within deep learning models. With ML models being notorious "black boxes," their inability to explain their reasoning process hinders the ability to provably defend AI/ML findings when scrutinized. This characteristic of AI systems, often known as the lack of explainability, raises issues of trust and acceptance, especially in high-stakes domains.
Additionally, the lack of proper forensics reporting capabilities in current AI/ML frameworks exacerbates this issue. Findings from AI/ML models that carry great value can be hard to defend in both legal situations and the court of public opinion without strong verifiable evidence supporting them. This highlights the need for robust auditing and reporting mechanisms within AI systems.
Microsoft suggests that to tackle these inherent security risks associated with AI, ML, and GenerativeAI, it's crucial to incorporate "resiliency" as a trait in AI systems. These systems should be designed to resist inputs that conflict with local laws, ethics, and values the community and creators hold, bolstering their security and trustworthiness.
Mitigating the security risks in the AI-augmented development landscape
As we delve into a future where AI, LLM, and GenerativeAI tools become integral to our coding practices and software development process, we must ensure that our zeal for innovation does not overshadow the importance of maintaining robust security practices.
To minimize the security risks associated with secure coding and GenerativeAI tools, one strong recommendation would be implementing stringent code reviews. Whether the code is auto-generated by an AI or written by a human, it should undergo rigorous quality checks and critical assessment by skilled developers or code reviewers. This can help not only catch traditional coding errors but also identify security vulnerabilities that might go undetected by AI models.
Moreover, integrating tools for static application security testing (SAST) can greatly assist in mitigating potential security threats introduced through LLMs. SAST can scrutinize code from within without needing to execute it and identify potential vulnerabilities in the early stages of the development cycle. Automating such testing tools in the code pipeline can further enhance the identification and mitigation of security vulnerabilities.
DeepCode AI was built to utilize multiple AI models, is trained on security-specific data, and is all curated by top security researchers to provide developers with real-time secure coding fixes and insecure code detection while they code in their IDE.
The following is a real-world example of a Node.js express web application that uses a database backend with insecure SQL code that's vulnerable to SQL injection attacks. The Snyk IDE extension in VS Code detects insecure code as a JavaScript linter red underlines, prompts the developer for awareness, and, better yet, suggests ways to fix the issue.
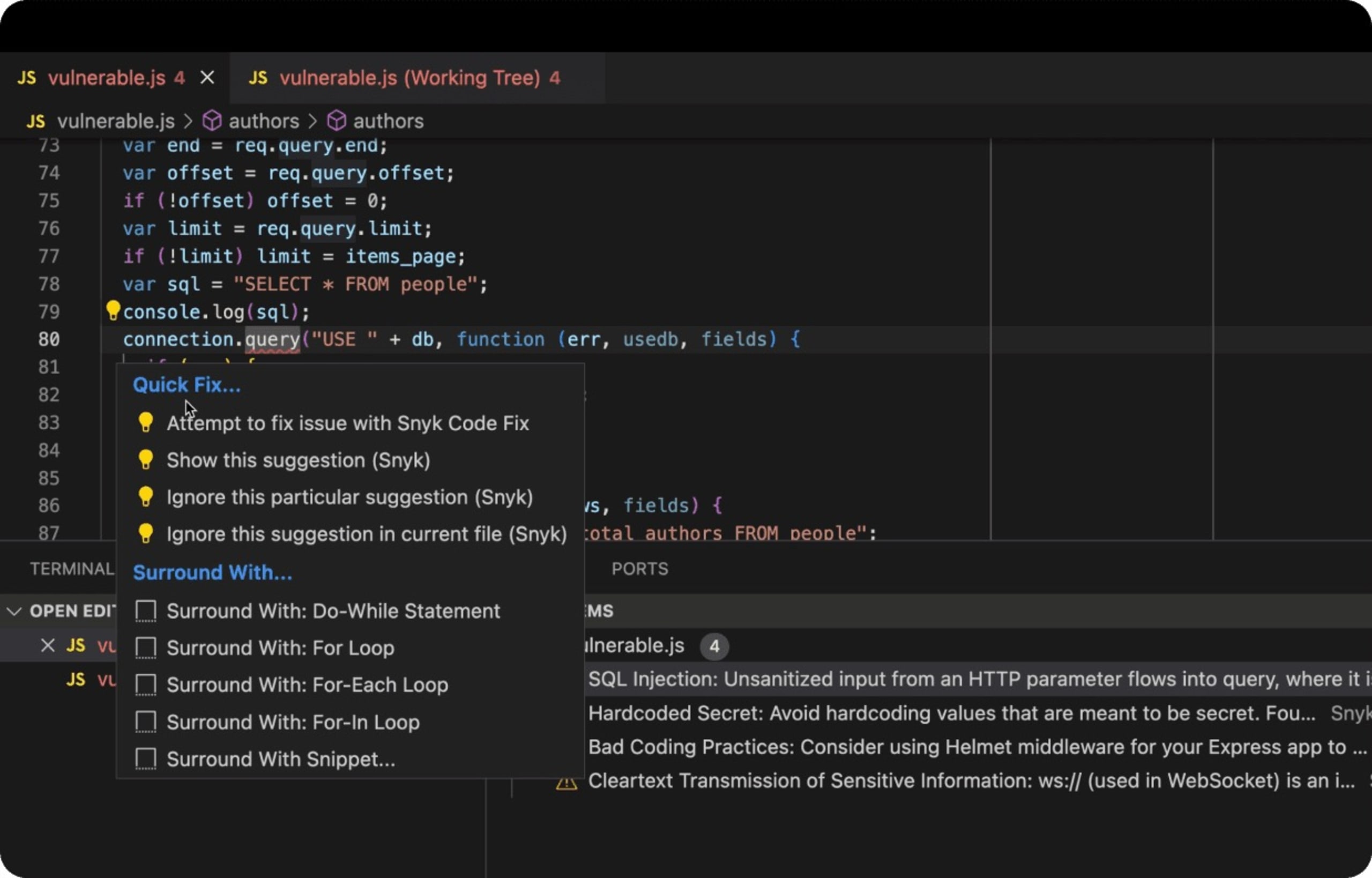
Lastly, perhaps one of the most vital measures is fostering an environment of continuous learning and adaptation within the development teams. Creating a culture that encourages knowledge sharing about the latest trends in secure coding practices, potential vulnerabilities, and their countermeasures can go a long way in maintaining secure applications.
Closing thoughts on AI security
The agile incorporation of AI tools like LLM and GenerativeAI models promises a future of rapid, optimized software development.
Ultimately, the responsibility of producing secure, reliable, and robust software still lies significantly with human developers. AI code generation tools like ChatGPT should be seen as supportive instruments that need human guidance for generating truly secure, production-quality code.
The crux is clear — as we advance further into an AI-assisted era, it's paramount that we balance our enthusiasm for such innovations with caution and vigilance. Secure coding must remain a non-negotiable standard, irrespective of whether code comes directly from a human or is suggested by an AI.
As we ride this wave of AI innovation, let's strive to maintain impeccable security standards, protecting our software, systems, and ultimately the users who rely on us.
Own AI security with Snyk
Explore how Snyk’s helps secure your development teams’ AI-generated code while giving security teams complete visibility and controls.