Introducing Snyk’s new Risk Score for risk-based prioritization

August 17, 2023
0 mins readWe’re happy to announce the open beta availability of Snyk’s new Risk Score! Replacing the existing Priority Score, the new Risk Score was designed to help you prioritize more effectively by providing you with an accurate and holistic understanding of the risk posed by a given security issue.
The Risk Score is powered by a new risk assessment model that leverages multiple objective and contextual risk factors to measure both the likelihood of a vulnerability being exploited and the impact it may have if exploited. The new Risk Score accounts for more risk factors than before — including reachability, exploit maturity, EPSS, social trends, CVSS, transitive depth, business criticality, and more — giving you more comprehensive and accurate security intelligence.
Once enabled, the new Risk Score will be displayed on Snyk issue cards, where a full explanation of how the score, as calculated, can be used to understand the risk posed by the issue. The score is also available within Snyk’s reports and via our API.
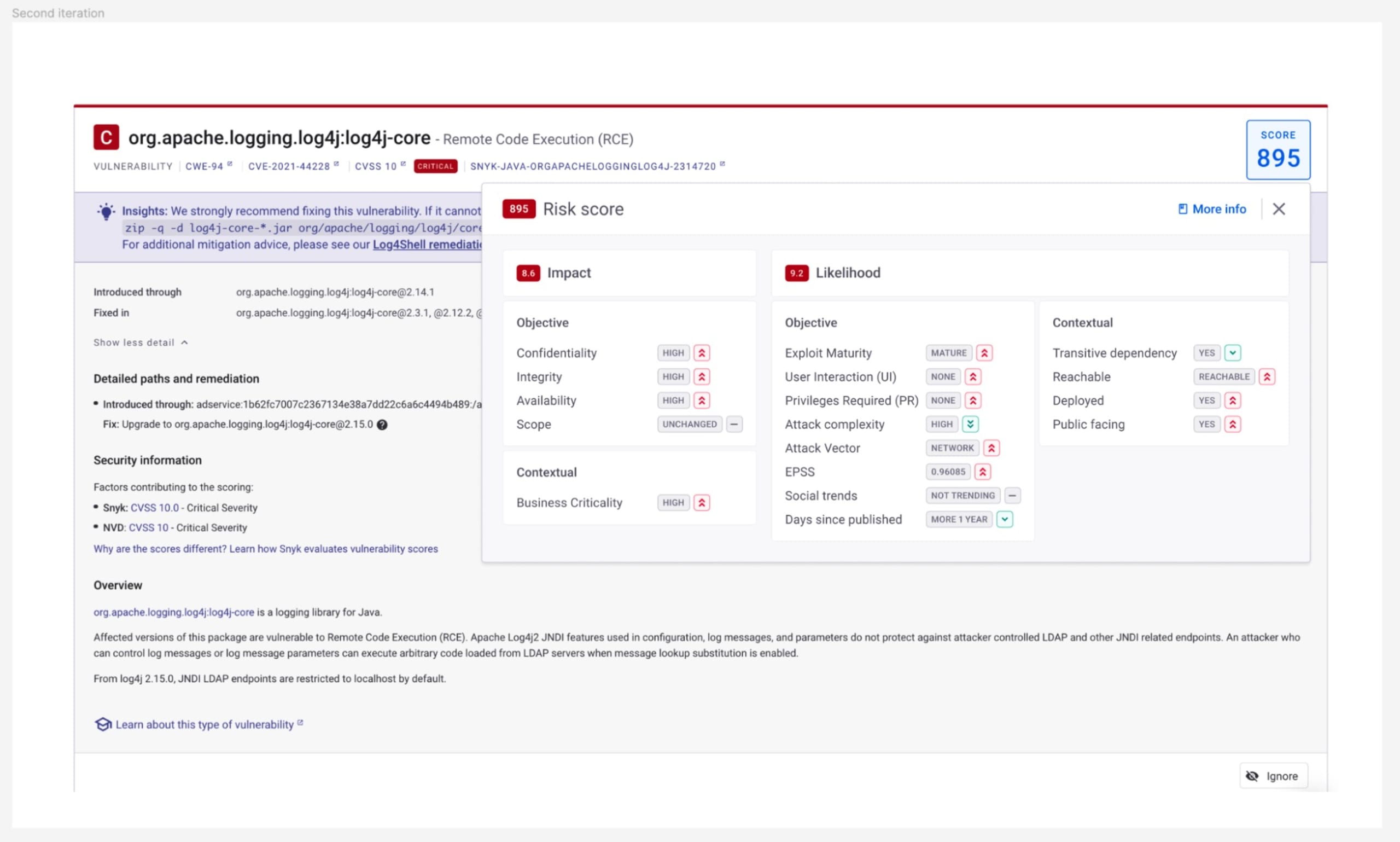
Risk Score can be enabled via Snyk Preview, and is available, in open beta, for Snyk Open Source and Snyk Container issues across all Snyk plans — including Free. To find out more about Risk Score and how to use it, please refer to our online documentation.
The problem: Noisy security backlogs
One of the biggest issues faced today by most security and development teams trying to secure their software throughout the software supply chain, is that of signal-to-noise ratio.
On the one hand, the number of vulnerabilities uncovered in their code seems endless:
Security tooling has developed to become almost ubiquitous along the software supply chain, greatly expanding the threat surface that needs to be protected and creating more issues than ever before.
New vulnerabilities are discovered on a daily basis in popular open source libraries and vendored software, ever-increasing the number of threats that need to be triaged, prioritized, and fixed.
Software complexity is only growing, and it’s not always possible to automate upgrades or fixes without introducing breaking changes to our code, making it harder to triage and fix issues.
On the other hand, users are finding that not all threats are born equal, and the vast majority of issues identified pose far less risk to them than they initially anticipated. One example of this can be seen in the EPSS threat modeling system from FIRST, which looks to predict the threat of a specific CVE identified being exploited in the wild:

We can see that over 95% of vulnerabilities are highly unlikely to ever be exploited, with the truly dangerous threats being clustered around the 99% percentile.
Compare this to a break down of vulnerabilities by CVSS 3.1 Severity, the most commonly used yard stick used by security professionals to measure risk, where a far higher percentage of vulnerabilities are clustered in the High-Critical range:
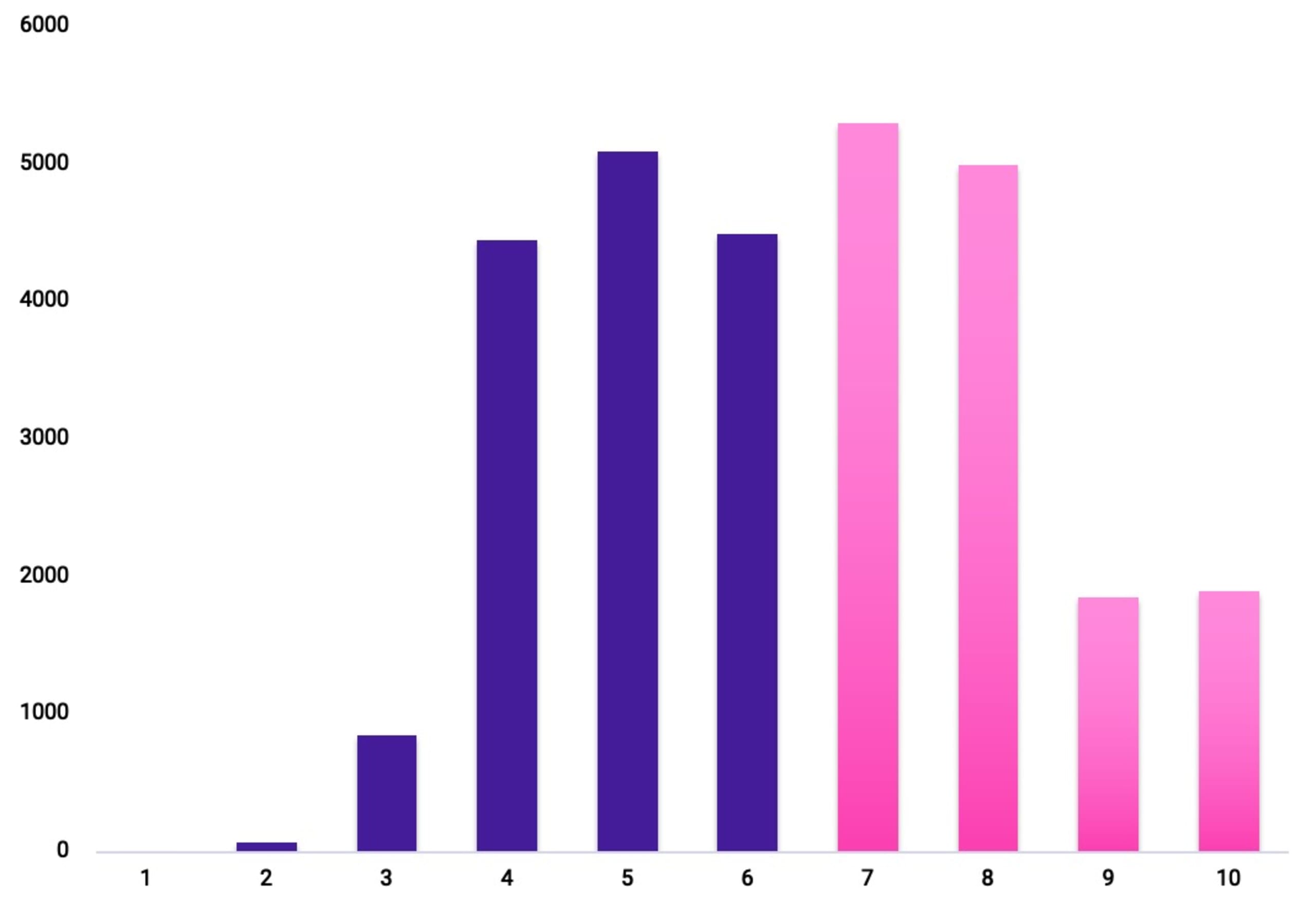
Looking forward to CVSS v4.0 doesn’t help either. By definition, the CVSS framework still requires you to analyze the issues in the context of your environment manually, leaving you with too much work.
Risk prioritization: The search for a silver bullet
The obvious question is how do we move from a world where we are attempting to triage and deal with thousands of highly improbable risks to one where we can concentrate most of our time on the most risky issues. Various silver bullets have been suggested in this area — a single risk factor that could be used to immediately discount all risk of certain vulnerabilities, for example:
Exploit Maturity or EPSS - Tries to objectively predict whether an attack will be attempted and succeed, it’s predictive in nature and doesn’t take your environment into account.
Static Code Reachability - Tries to put a line between used and unused components, it’s helpful with highlighting those that are used but cannot be used to ignore the rest. Relying solely on this risk factor also misses the mark as additional contexts, such as network reachability and other exploitable conditions, are not considered.
Transitivity - There is a school of thought proposing that issues in transitive dependencies do not need to be considered. Log4shell (and countless other vulnerabilities) proved this premise wrong.
There’s an obvious draw to the simple binary risk model, it’s simple to grasp — and if it were to actually work, it would greatly reduce our work. Unfortunately, security and code are not binarily simple. And these simplistic models leave us dangerously vulnerable to risks that they discount while still leaving us concentrating on a subset of vulnerabilities, many of which are not actual threats. Using one or a combination of these exclusively requires full confidence in the info given - as well as in the info not given.
Developing a new risk assessment model for Risk Score
Understanding the challenge of prioritization facing our customers, we set about creating a new risk assessment model with three main goals in mind:
To build a true probabilistic risk model rather than a binary one.
Build a model that took into consideration and reflected the inherent complexities in assessing risk while still allowing humans to understand and verify its findings.
To have contextual input of individual users set up and to enable ourselves to expand that contextual factor further.
The assessment model made available in Snyk’s new Risk Score takes into account two risk vectors:
Likelihood - How likely is a certain risk to materialize, or in other words, how likely is it for a vulnerability to be exploited in a user's code.
Impact - Given exploitation, what impact would occur to our users?
Each of these vectors is broken down into two categories of risk factors:
Objective - The risk factors objectively defined for the issue at hand, relevant for any vulnerable environment.
Contextual - The risk factors defined within the context of the vulnerable application’s environment.

These risk factors are then calculated together by the algorithms in our risk assessment model to produce a risk score for any given issue.
How to be objective about exploitability?
For each risk factor we introduced into our model, we conducted two experiments to verify its use in our algorithm as well as its relative predictive weight. Firstly, we created a baseline of how likely a random vulnerability was to be exploited by using Snyk’s own vulnerability database cross-referenced with the known exploited-in-the-wild vulnerabilities published by CISA. We then checked the relative correlation of each risk factor we hypothesized could impact the likelihood of exploitability against this baseline.
However, correlation does not equal causation, and at this point, we began tinkering with various ML models to help us properly identify which risk factors were truly helpful in predicting exploitability. After several rounds of experimentation, we used a regression model to identify which risk factors had a statistically significant impact on exploitability — and used the results of this model as input into our algorithm.
Finally, we took the output of our models and tested hundreds of anonymized projects to see if the breakdown in exploitability of our model aligned with what we would expect from real-world breach data, as mentioned above.
It’s all about the context
While we are delighted to seemingly be predicting an accurate picture around exploitability in the global sense, the contextual risks involved in an individual user’s setup are still critical. Here we dug into our internal proprietary security research and attempted to exploit specific vulnerabilities under multiple sets of conditions. In this way, we were able to incorporate seemingly “binary” conditions, such as Reachability or Transitivity, and rather than needing to make bold (and inaccurate) claims, we could use them as probabilistic input into our algorithm.
Finally, at Snyk, we put transparency and trust at the heart of our work, which is why we expose all the factors and reasoning leading to the score, both as part of issues experienced and in our public documentation.
The future of risk scoring at Snyk
At Snyk, we believe AppSec and development teams should be empowered to determine their prioritization methodologies. We’ve seen different companies approaching this from different angles:
Risk-focused - Filter and sort issues by a score based on a risk analysis model, like Snyk Risk Score.
Compliance-focused - If you are compliance heavy, you must attend to each High/Critical issue as CVSS defines it. As mentioned, this will yield a lot of issues to attend to, so risk scoring can be used to sort and filter what is most important
Actionability focused - Break issues down by how much effort it would take to fix them. Risk scores shouldn’t incorporate it, but apply another dimension to why pulling in the effort needed to fix the issue is important.
You also might have your own risk appetite and input. And so, in the future, Snyk’s Risk Score will allow users to customize the score and feed it with their knowledge of your environment, leveraging the predictive model to prioritize rather than eliminate issues.
To get started with Risk Score, enable it today via Snyk Preview!