10 Serverless security best practices

May 31, 2019
0 mins readIn this instalment of our cheat sheet series, we cover best practices for securing your serverless deployments.
So, let’s get started with our list of 10 Serverless security best practices.
If you haven’t done so yet, make sure you download this cheat sheet now and pin it up, so your future decisions are secure decisions!
Many of the examples and use cases refer to AWS Lambdas but very much apply to other Cloud and Serverless vendors, refer to the CNCF Landscape for a reference list.
So, let’s get started with our list of 10 Serverless security best practices.
1. Patch function dependencies
Function as a Service (FaaS) platforms take on the responsibility for patching your operating system dependencies for you, but do nothing to secure your application dependencies, such as those pulled from npm, PyPI, Maven and the likes. These libraries are just as prevalent and just as vulnerable as operating system dependencies, and you - the application owner - are responsible for upgrading or patching them when a vulnerability in them is disclosed.
Use a solution like Snyk to scan serverless projects for known vulnerabilities in open source dependencies. Snyk goes a step beyond vulnerability report generation, also providing remediation advice and automatically applying fixes through version upgrades and security patches.
With Snyk tools, you can protect functions throughout your development lifecycle, starting with the integrated development environment (IDE) with the help of our plugin for VSCode or IntelliJ, moving on to GitHub app integration that enables Snyk to issue automatic pull requests to fix security vulnerabilities as they are discovered, or to break continuous integration (CI) builds in order to avoid deployments when security vulnerabilities are newly introduced.
Enforce secure deployments for functions
In addition to CI and source code repository monitoring and proactive patching for security vulnerabilities, the deployment workflow for a function should also be subject to security review and deployments should be ceased when vulnerabilities are found in functions as they are deployed.
The Serverless framework is a common toolkit used to develop and deploy serverless functions. Its plugin architecture enables integrating custom workflows as part of the function lifecycle. Snyk offers an open source Serverless plugin that seamlessly integrates with the framework.
Following is a picture that demonstrates the plugin actively protecting a function from being deployed because security vulnerabilities are detected in the open source dependencies:
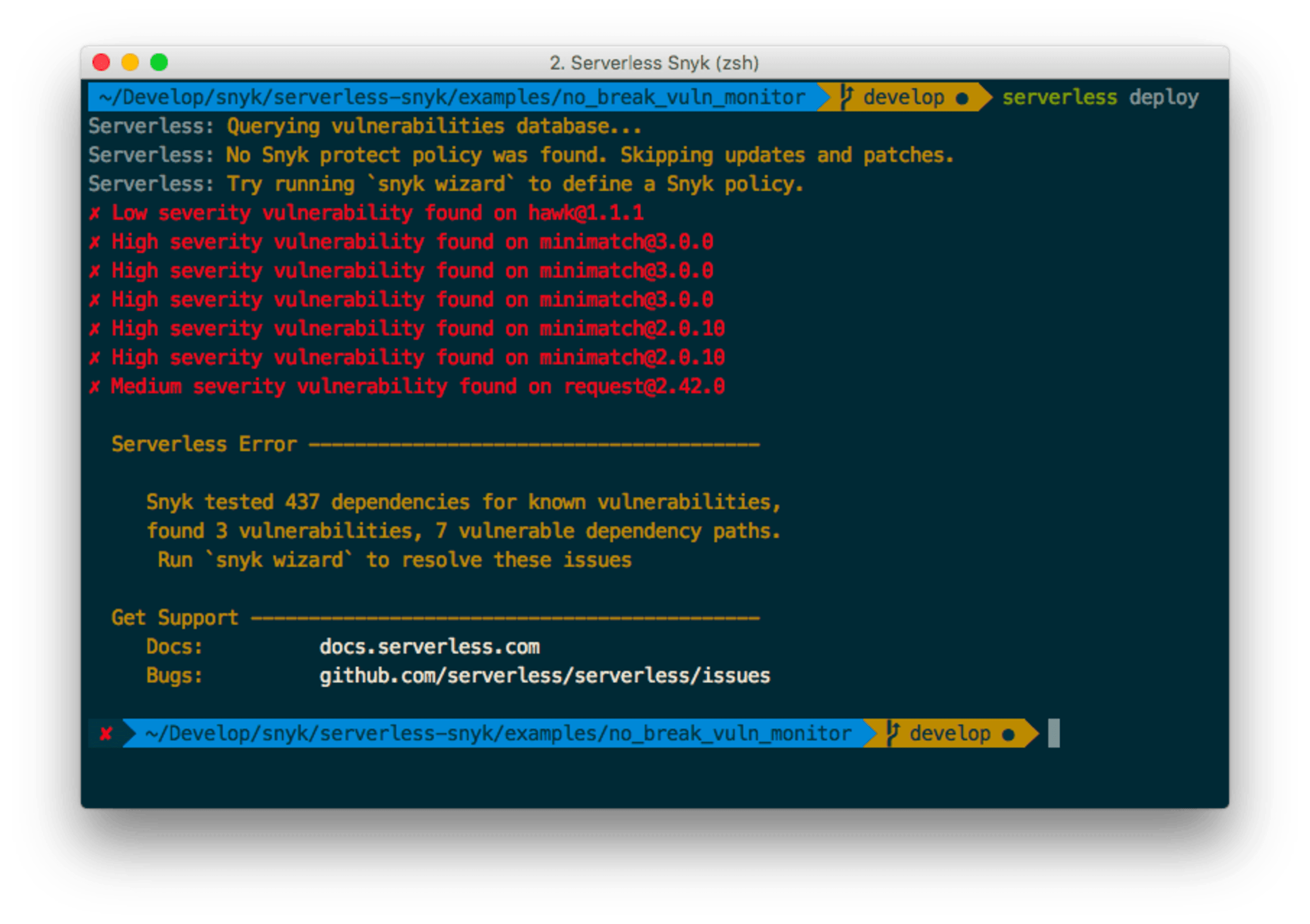
For more information about setting up the Serverless Snyk plugin or creating project snapshots for CI/CD workflows and monitoring your projects, setup the Serverless framework plugin check out this post
2. Adopt the principle of least privilege
Functions are small, allowing us to reduce each permission sets to the bare minimum—only enabling access based on what is individually required by each function in order to operate well. This results in dramatically reducing the damage a successful attack might cause and minimizing the surface of exposure for the overall integration of several functions. For instance, most functions probably don't need access to the database, or permissions to connect to external servers—both of which are common actions executed by attackers and malicious users after successful exploitation.
Maintain the principle of least privilege. Make sure you deploy your functions with the absolute minimum permissions set that they require in order to keep a secure setup by minimizing the attack surface.
Mistakenly providing more permissions than necessary
Consider the following serverless.yml configuration that defines a single permissions role for all functions deployed with this project:
A mistake that stands out in the above configuration is that the IAM role deployed with the function gives access to all DynamoDB read and write actions that integrate with these functions, while in reality, some functions only need to read, while others need to delete. This type of naive serverless project default translates into a broader attack surface where granular function deployments would be preferable in order to break down the permissions set by need as well.
Correctly creating role and permission access per function
The serverless framework promotes configuration of roles per function, as we can see in the following example snippet of a serverless.yml file:
From line 7, two functions are declared as follows: func0, func1.Each of these functions is assigned its own specific role, determined by the role directive on lines 9 and 12.
Different role definitions can provide much more granular access by providing no more than just what each function requires, such as AWS-related log capabilities for a function rather than access for another function to an Amazon S3 bucket for example.
3. Maintain isolated function perimeters
While multiple functions may be deployed to create a complete aggregative workflow, each function should be treated as its own perimeter to ensure that a vulnerability in one function doesn’t escalate and compromise others as well.
Let’s look at this scenario as an example:
The subscribeToEmailNotification function sanitizes input and then the sendNotification function is triggered to process and deliver that input. You may be inclined to skip sanitization of any input event for the second function after having already sanitized the latter “subscribe” function. If at a later point in time, a new subscribeToSMSNotification function is created which does not sanitize input, that again leads to allowing the sendNotification function to process event data without sanitizing the data as well.
Follow these guidelines to ensure functions are isolated within their perimeters:
Do not rely on function access and invocation ordering: don't rely on the fact that one function is only called through another function, or is not accessible through an API gateway; function ordering and access changes over time.
Each function is its own security perimeter: each function should treat any event input as an untrusted source of data and should always sanitize its input.
Use security libraries: invest time in creating or adopting standardized security libraries, and mandate their use across functions
4. Sanitize event input to avoid injection
Serverless architecture often requires different types of data ingestion for cloud functions: synchronous, asynchronous or streaming data, all of which may include user-controlled data that flows across different data stores and functions.
Even when guarded behind API gateways, firewalls and other proxies along the way, functions used in the context of API services handle user input just as if they were a traditional API server. Moreover, functions that handle event data from message queues and other non-public communication may still indirectly handle user input, but the context and source of data becomes a blur and harder to predict.
Serverless architecture is mostly event-driven, in which an event injection becomes a prominent attack vector and relies on the fact that a function is purposely created to handle small tasks such as processing data from an event queue. However if malicious data managed to bypass a data sanitization function and reach the event payload, then when not handling data validation correctly the processing function may end up being susceptible to injection attacks.
Following are examples of less traditional data sources that are common triggers for functions, and therefore shouldn’t be trusted by functions:
Storage—filenames or directories in cloud storage such as S3 buckets may be controlled by users and result in malicious input for interpreters
Messaging—event data payloads for asynchronous messages over services such as SNS and SQS should be sanitized and not be trusted
Database streams—updates to a database, such as an addition to or deletion from a record may be used to trigger functions. Any such event is subject to potential user input as a source and so should be sanitized
Employ the following best practices for any user input handled by the function in order to mitigate against event injection attacks:
Validate data based on schemas and data transfer objects, checking expected type, length and data range instead of blindly serializing and deserializaing data objects and passing them on as-is.
Always use an ORM and apply proper escaping when SQL and non-SQL databases are involved in order to avoid these injection types.
Avoid spawning system processes or evaluating dynamic code in runtime with data sourced from events for either of these as it may potentially have originated from user input. Furthermore, be mindful of the 3rd party services you are integrating within your functions as you have minimal control or visibility into the data source and the scope of user-controlled input. When handling process spawning and dynamic code, apply proper countermeasures such as encoding and sandboxing respectively.
5. Employ API gateways as a security buffer
Deployed cloud functions are commonly exposed, and therefore, accessible over a randomly-generated HTTP endpoint that can send event, data and correct context to process the payload. A good practice for exposing functions is through API gateways, which act as reverse proxies and provide a separation layer between users and functions.
Acting as the front-facing API interface for consumers, API gateways can be leveraged, with a little configuration, to provide several security mechanisms that aid in lowering the attack surface through functions.
API Gateway as a filter
Use an API gateway before exposing your functions as a filter to limit input to your function based on a gateway policy. The stricter the policy, the less risk is likely to enter through your functions. AWS API Gateway encourages declaring request and response mapping that complies with schemas. This is a similar pattern to Data Transfer Objects; in the case of functions and gateways mapping can serve as a strict incoming request rule.
Following is an example schema defined at the API gateway level for an incoming JSON request:
API Gateway as an authentication edge
Gating HTTP requests before your cloud functions receive them is a crucial part of user access to applications such as authentication and authorization. Configure an API gateway and leave concerns brought by functions to the cloud provider and their infrastructure.
Once users are authenticated at the API gateway, countermeasures can be applied against users, such as throttling and applying quotas at the Gateway, all this without triggering function invocations.
API Gateway as a DDOS mitigation
An API gateway adds protection against Denial of Service (DOS) attacks at the cloud provider level, enabling you to throttle all requests directed at your functions. The concern of rate limiting is removed from your functions and business logic (as it should be), and is now handled entirely by the cloud infrastructure. Employing an API Gateway will help you avoid financial resource exhaustion.
6. Monitor and log functions
Functions are extremely short-lived and with many functions deployed and a growing amount of function invocations as you scale, it is easy to lose track of the flow of events in order to pin-point the cause for errors. As serverless adoption grows for an organization, it becomes more complicated to monitor for insecure flows and malicious attempts by attackers attempting to force a function into an unsafe code path.
AWS has recently introduced the ability to tag lambda functions so that they are easy to track and group together. Using the serverless framework, we can tag functions in their yaml files at either globally (for all functions in the serverless.yml file) or for individual functions.
Monitoring functions for security vulnerabilities
Snyk integrates with your FaaS provider in order to monitor the deployed functions so these are kept in check. This allows you to address known security vulnerabilities across the software development lifecycle as it relates to functions and their use of open source dependencies.
In the following picture we see the GitHub project lirantal/bazz-serverless after being scanned and including several high, medium and low vulnerabilities. This is the source code for my serverless project which deploys several functions. Below the GitHub project repository we can see all six of the AWS Lambda functions that I deployed, and these are the actual functions as they are deployed and executed by AWS.
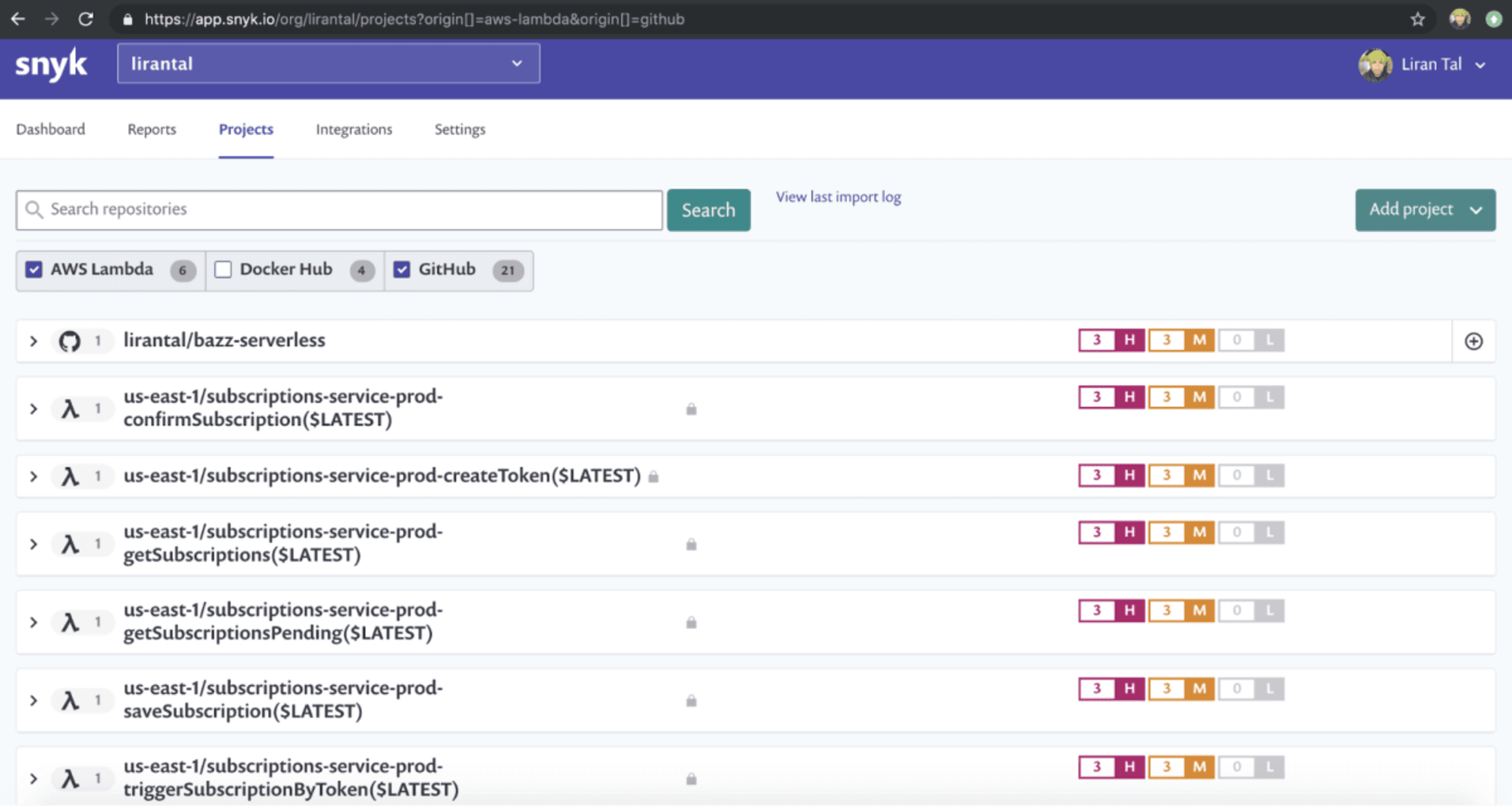
Snyk scanned all these individual functions for known security vulnerabilities and as each of them uses the same dependency tree we can see that they are all deployed with versions of vulnerable libraries.
Cloud providers often have built-in monitoring for application and function resources to provide this insight. Microsoft has Azure Monitoring, and Amazon has AWS X-Ray. AWS’s X-Ray console, for example, provides insights into the flow of data through functions and other cloud resources and metrics such as their execution time.
7. Follow secure coding conventions for application code
A great value of serverless infrastructure is in transferring the concern for the underlying operating system from the application owner to the cloud provider which has the responsibility of maintaining it and keeping it up to date with security patches. This however means that attackers will shift their attention to the areas that remain exposed – and first amongst those would be the application code itself.
Application code is still vulnerable and developers should follow secure coding conventions, and ensure these guidelines are followed-through during activities such as code review sessions in order to catch application code security issues early in the process of software development. Mandating the use of shared security libraries across developer teams further help ensure that secure coding guidelines are met and also prevents developers from re-inventing the wheel with possible mistakes for security concerns that already have standardized solutions.
OWASP Top 10 is a good reference for some areas of application code that should require further attention to security detail. Some of these topics are:
Injection attacks, where by data isn’t filtered or encoded with the correct context and will result in being interpreted as part of a trusted execution. This applies to areas such as SQL injections, system commands execution, CSS and JavaScript code execution. To avoid malicious injection in any context completely prevent user input if possible, resort to a safe whitelist, and encode all user provided data to the correct context.
Sensitive data exposure in which attackers may exploit insecure medium of communication to exfiltrate sensitive information, or use of insecure cryptographic algorithms in security contexts. Mitigations that can be applied are the use of TLS as a secure means of communication, passwords and other credentials always encrypted or hashed with proper cryptographically secure algorithms.
Broken access control which allows attackers to access resources that they shouldn’t have. To mitigate the problem, implement proper access control mechanisms such as defaulting to denying access and following a non-permissive authorization model. Apply rate limiting where relevant to minimize brute force attempts and abuse of service.
Note: For a complete list refer to the OWASP Top 10 2017 guide.
8. Secure and verify data in transit
As can be learned from the httparchive about the state of HTTPS usage, using a secure medium for web communication is becoming more prominent as best practices are employed, reporting 77% of all traffic monitored by the service. Functions and the services they integrate with, whether 3rd party or within the cloud perimeters, should be no exception and should all use a secure medium for communication.
Follow these guidelines to ensure you communicate securely for data in transit:
Leverage HTTPS for a secure communication medium both within your internal perimeter of other functions or services being called, as well as cloud provided services and 3rd-party services residing beyond the cloud vendor.
Verify SSL certificates to ensure the identity you’re communicating with and ensure all communication halts when the identity and authenticity of the server doesn’t match the certificate.
Enable signed requests for cloud vendors that support it
Treat responses from 3rd party services as untrusted user input and sanitising it
Secure medium for in-cloud services
Services and resource access local to the cloud provider infrastructure should utilize a secure medium for communication whenever possible. As an example, when an AWS Lambda function integrates with SNS it should opt-in to communicate over SSL:
Signed requests
When using cloud vendor tools like the AWS SDK and the AWS CLI in order to create HTTP requests, these automatically include a signature in the HTTP header or query parameters that convey the identity for the HTTP request being called, thus further protecting data in transit and mitigating against HTTP replay attacks.
For example for AWS signed request when the signature is added to the HTTP message as an Authorization header:
9. Manage secrets in secure storage
Use a secure storage for your secrets and sensitive credentials; one that is supported by the big cloud and FaaS vendors. As an alternative, users can deploy their own solutions such as Hashicorp’s Vault. Storing keys in a secret storage mitigates the risks of sensitive information stored in static files in a source code repository, or environment variables, and greatly reduces the chance of sensitive information exposure.
The following example makes use of the AWS Simple Systems Manager, designed to fetch secrets that were securely encrypted with the AWS Parameter Store. In our example, the SSM variable is used to access a specific value that was created beforehand, making it available for a function through an environment variable:
We need to take note that ${ssm:/github/api-key} will return the encrypted value of that key and if we wanted to decrypt and return the actual value we need to specify ${ssm:/github/api-key~true}.
More information about the Parameter Store and KMS is found on Amazon’s documentation website: https://docs.aws.amazon.com/kms/latest/developerguide/services-parameter-store.html
For even more improved security and flexibility in managing secrets in applications, consider accessing the secrets and other configuration information in run-time instead of environment variables that will require a process restart to re-apply new configuration.
While using a secrets storage reduces the chance of a key leaking, it doesn't completely eliminate it. Fortunately, if you're using secrets storage in your function, it means nobody cares what the key actually is... and so you can rotate the key regularly! This way, if the key leaks or is stolen, it will only be useful for a short period of time.
10. Deploy functions in minimal granularity
Functions are expected to be small by principle, and so the code deployed with them is small too, reducing the attack surface and the information that can be leaked if the function is compromised. Deploying functions in bulk, needlessly deploying more code and functions than necessary, is not advisable.
Functions that are part of the same serverless project share the same dependencies by default. For example, Node.js serverless projects share a single package.json file with dependencies that are deployed with each and every function but may not all be explicitly required by all of the other functions.
As you may find yourself reusing a lot of boilerplate code, you may find it useful to use templates to scaffold projects, such as:
Download the Serverless Security Best Practices cheat sheet for easy reference. And sign up for a free account with Snyk to start securing you code today!
Get started in capture the flag
Learn how to solve capture the flag challenges by watching our virtual 101 workshop on demand.