URL confusion vulnerabilities in the wild: Exploring parser inconsistencies
Snyk Security Research Team
Claroty Team82
2022年1月10日
0 分で読めますURLs have forever changed the way we interact with computers. Conceptualized in 1992 and defined in 1994, the Uniform Resource Locator (URL) continues to be a critical component of the internet, allowing people to navigate the web via descriptive, human-understandable addresses. But with the need for human readability came the need for breaking them into machine-usable components; this is handled with URL parsers.
Given the ubiquity of URLs for decades, one would think that the URL parsers we use today would have reached a consensus regarding how to parse similar (or even identical) URLs. Although ideal, that is far from the truth. This lack of consensus has helped a class of vulnerability called URL confusion that we are going to explore in this post.
Note: The development process for internet protocols (HTTP, HTML, URL, etc.) uses documents known as Requests for Comment, or RFCs. We will frequently refer to these documents in this post.
In our joint research, we examined many URL parsing libraries across a variety of programming languages and noticed some inconsistencies with how each chose to split given URLs into their basic components. We categorized the types of inconsistencies into four categories and searched for problematic code flows in both web applications and open source libraries. These efforts exposed numerous vulnerabilities, most of which had one of these root causes:
There are multiple URL parsers in use
There were multiple URL-related RFCs over time, and different parsers implemented different RFCs
In this post, we will take a look at the history of URLs, explore possible sources of URL parser confusion, run through an exploit POC, and then provide recommendations for keeping yourself safe from URL confusion based attacks. Use the below table of contents to jump ahead:
The research done by the security research teams at Claroty and Snyk is inspired by the previous works of Orange Tsai titled “A New Era of SSRF” and a comparison of WHATWG vs. RFC 3986 by cURL creator, Daniel Stenberg. We would like to thank them for their innovative research.
What are URLs and how did we get here?
When we think of a URL, we think of something like https://snyk.io. At its most basic, it’s where to go (my-site.com) and how to get there (over HTTPS). On top of those components, we’ll also see additional things like paths (https://my-site.com/about), hash symbols followed by a string (fragments, ex: https://my-site.com#contact), or question marks followed by parameters (queries, ex: https://my-site.com?source=li&device=mobile).
Generalizing and combining the above, we can break down a URL string into the following core components:
scheme://authority/path?query#fragment
For example, a URL can look like: https://example.com:8042/over/there?name=ferret#nose
During our research, we looked into how various parsers implemented various RFCs. While the above URL form seems relatively simple, the RFCs that defined it have changed a lot since 1994. These additions and overhauls have culminated in the URL that we're familiar with today taking shape.

Learn more: RFC 1738, RFC 1808, RFC 2141, RFC 2396, RFC 2732, RFC 3986
In order to be able to understand where the parsers get confused, we first need to take a (quick) dive into what each component in the complete URL means and how it is defined.
Scheme
The scheme section is where we define the protocol (i.e. HTTP, HTTPS, FTP, Gopher, etc.). The RFCs define which characters are allowed to appear in this component and that the current scheme must fit the pattern of ALPHA *( ALPHA / DIGIT / "+" / "-" / "." ). Let's take a look at how that works:
First character:
a–ZNon-first character(s):
a–Z,0–9,+,-,.
This means that 1http isn't a valid scheme (since it starts with a number), but h2ttp is (since the first character must be a letter). Also, unlike the other components of a URL, scheme is the only one that is required.
Authority (previously Netloc)
This component was called “Netloc” (network-location) in the past and was renamed to Authority. It is composed of three internal sub-components: userinfo, host, and port. Together, a generalized example of an authority looks something like this : authority = [ userinfo "@" ] host [ ":" port ]. The userinfo subcomponent may be also reduced to its primary components as follows: username[:password]. This handles URLs of the form scheme://user:password@domain:port/. Note that as of RFC-2396, the usage of plaintext user:password was discouraged and it was deprecated in RFC-3986.
Path
This component indicates which resources the requester would like to access on the server. It is allowed to present any sequence of characters (except /,;,=,?) that are split into segments (delimited by /).
While this seems like the most straightforward component, it is also the one that had the most changes over the years. RFC-1738 and RFC-1808 tied the path component structure and rules to the scheme component. That being done, RFC-2396 stated that each path segment may use the semicolon character (;) in order to define parameters. However, not long after RFC-2396 came RFC-3986 and the semicolon parameter syntax was deprecated.
Confused? Well, so are the parsers!
Query
Queries are key-value pairs that are passed via the URL to the requested resource. The query parameters are found after the first question mark (?), and terminated by a number/hash sign (#).
Within a query component, semicolon (;), slash (/), question mark (?), colon (:), at-symbol (@), ampersand (&), equal sign (=), plus sign (+), comma (,), and the dollar sign ($) are all reserved characters and will be URL encoded when used.
Here's an example of special characters URL encoding:
Fragment
The fragment is used to identify and access a second resource within the first fetched resource specified by the path component. A fragment component is indicated by the presence of a hash (#) and is terminated by the end of the URI
... and that's it for the components!
Relative URLs
The last thing we will talk about in this section is the relative reference aspect of URLs. Since URLs are hierarchical by nature, one URL may be relative to another. For example, given a "base" URL of https://example.com/ and a path-first URL string segment, such as /foo/bar, the parser will resolve these into https://example.com/foo/bar, however, it must be supplied with the "base" URL first.
That being said, this means that the parsers need to know how to parse relative references. RFC-3986 defines three types of relative references:
Network-path reference - begins with
//e.g.//example.comAbsolute-path reference - begins with
/e.g./etc/passwdRelative-path reference - doesn't begin with
/, e.g.foo/bar
Reference Type | Example |
|---|---|
Network-path | //snyk.io |
Absolute-path | /etc/passwd |
Relative-path | app/login.js |
While the last two require a base URL in order to resolve, the network-path reference only requires the scheme to be present. So if a parser defaults the scheme to HTTPS, //example.com will become https://example.com.
Where do URL parsers get confused?
Following our review of all the moving parts within a URL string and a review of all the RFC changes throughout the years, we've decided to target URL parsers and find edge-cases that will make them yield incorrect or unexpected parsing results.
During our research, we reviewed 15 libraries (written in various programming languages), URL fetchers (i.e. curl, wget), and browsers.
We found many inconsistencies among the parsers and categorized them into four main categories. With the categories outlined below, we can trick most parsers and create a variety of unpredictable behaviours, enabling a wide range of vulnerabilities.
The categories we created are:
Without further-ado, let’s review them!
Scheme confusion
Almost every URL parser out there is confused when the scheme component is not present. The confusion arises due to the fact that RFC 3986 states that the scheme component is the only mandatory part of the URL, whereas RFC 2396 and earlier do not. Implementing parsers while attempting to be backward compatible with respect to these nuances is not trivial, thus — confusion.
In order to demonstrate this, here are four different Python libraries that were given the URL google.com/abc

As depicted above, most parsers state that the host component is empty when given the string google.com/abc. Urllib3, however, states that the host is google.com and the path is /abc. Conversely, httptools claims that this URL is invalid to begin with. The bottom line is that almost all parsers do not parse this URL properly as it does not follow the RFC specifications.
That being said, some parsers will “fallback” to the default scheme, like curl in this case:

In this case, the parser difference may be abused by attackers in order to bypass validation. If a URL parser is attempting validation on specific hosts but can not parse the URL correctly to extract the host but, at the same time, the underlying library will parse the URL properly (or will fallback) — then a bypass occurs. For example:

In the above, urllib (namely the urlsplit function) will parse the URL as not having netloc so the check will pass but urllib3 will fallback and append the default http protocol, fetching the forbidden resource.
Slash confusion
The next confusion method involves a non-standard number of slashes in the URL. RFC 3986 indicates that the authority component in the URL should come after a colon with two slashes, ://, and it continues until the end of line (EOL) or a delimiter is read. A delimiter in this case can be a slash (indicating a path component) a question mark (query component) or a hash (fragment component).
During the research, we’ve seen various behaviors by the parsers when attempting to parse a URL that doesn’t follow the above syntax. Given the following URL http:///google.com, the parsers behaved interestingly:

As you can see, most parsers claimed that this URL has no host, but instead parsed the /google.com as a path on a hostless URL — which according to RFC 3986 is desired. We were able to reproduce this with any number of slashes after the scheme part. However, we’ve encountered a group of parsers that tried to “fix” the URL and ignored extra or missing slashes (to some degree). For example, the native Javascript fetch function will treat such URLs as if they were correct:

And this is also true for curl:

Having such differences in parsing results creates a wide attack surface. Like the previous attack idea (for scheme confusion), what if we can bypass checks due to the first parser parsing the URL differently than the fetcher? Consider this example:

Again, we can see a netloc assertion to a blocked domain, and again the netloc will be empty due to the parsing and the check will pass. Later in code, curl will treat the URL differently and will attempt to fetch the resource unexpectedly. This may lead to SSRFs and access to other disallowed hosts.
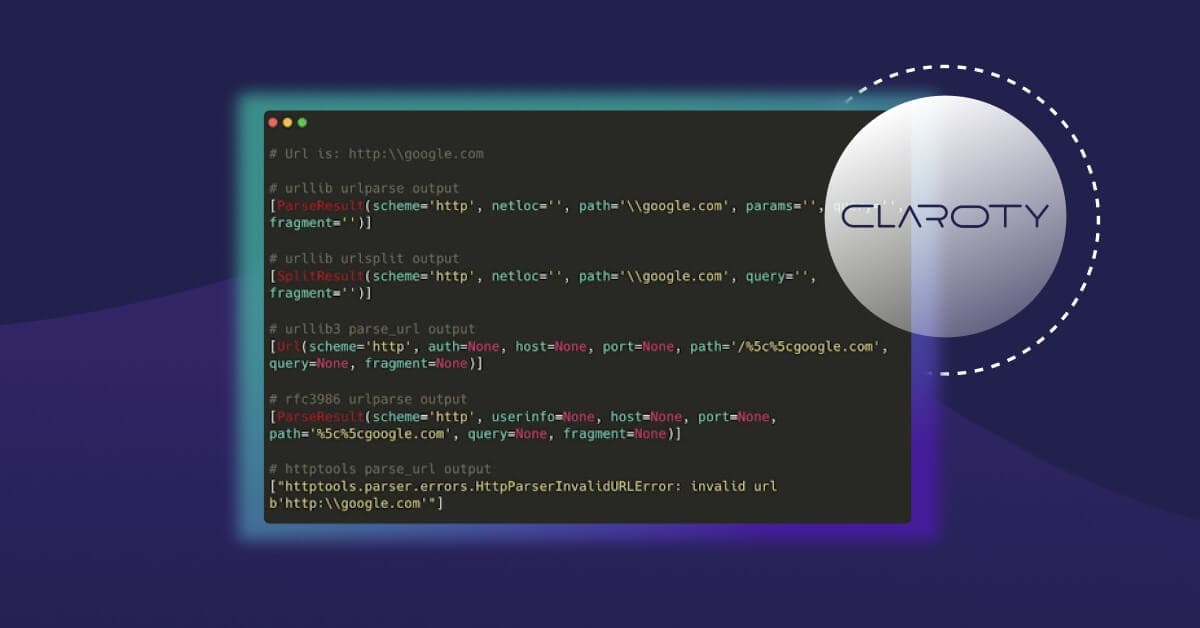
Backslash confusion
A variation to the slash confusion is the backslash confusion. This confusion may occur when a URL is using a backslash (\) instead of a slash (/), and thus creating a malformed URL. According to RFC 396, a backslash is different from a slash and should be interpreted differently, making http://google.com different from http:\\google.com. Staying true to the RFC, most programmatic URL parsers indeed treat the above two URLs different:

Chrome, however, chooses to interpret the backslash as it were a slash:

It will browse to the URL as if it is valid. To take things to the extreme, this behaviour will occur also for https:/\google.com and Chrome will serve the resource as (un)expected.
URL-encoded confusion
The last confusion category is URL-encoded confusion. This confusion occurs when a URL contains a URL-encoded substring where it is not expected.
URL encoding, generically, is a way in which non-printable characters are allowed into the URL strings. It is done using the characters’ hexadecimal value prefixed by a % symbol, so a g is %67 when it’s URL-encoded. This method allows the URL strings to remain completely textual and visible regardless of the characters put into it. While this method is aimed at non-printable characters, printable characters can be URL-encoded too and this is where the confusion occurs.
RFC 3986 states that all URL components, but the scheme, can be URL encoded. In the wild though, many parsers don’t parse the netloc component.
These are the parsing results when we gave the parsers the URL http://google.com in its URL-encoded version:

While the above results seem expected, an interesting behaviour was demonstrated by both urllib and requests of Python when they were given a URL-encoded URL:

In both cases above, a request was dispatched to 127.0.0.1 unexpectedly.
Given the above, this discrepancy creates yet another attack surface as simple Regex patterns won’t capture such strings and we may be able to bypass checks again.
Exploitation proof of concept (and issued CVEs)
Now that we understand where the confusion is, let's look into exploiting these problems and the issues we've found. We'll elaborate on one CVE, but the full CVEs list can be found below.
Clearance (Ruby): CVE-2021-23435: Open Redirect Vulnerability
Open redirect vulnerabilities occurs when a web application accepts a user-controlled input that specifies a URL that the user will be redirected to after a certain action (like login). To make the attack more visual, here's a diagram demonstrating it:
As you can see, the attacker supplies the victim with a URL to be used by the victim, that given the correct setup will make the server redirect the user to an attacker-controlled site.
Clearance is a Ruby gem aimed at enriching the Rails framework authentication mechanism by adding an email-and-password authentication. After a login/logout, it redirects the user using a URL it acquires from a previous user request (i.e. the resource the requester asked for prior to the login page).
The vulnerable code is inside the return_to function (the post login/logout callback):
While having open-redirects in mind, return_to doesn't allow users to supply a return_to URL at will. However, if a user requests an auth-required resource without being logged in, the system will call store_location and redirect the browser to the login page. Given this, if an attacker is able to persuade a victim to click on a link like http://target.com/////evil.com, we will trigger the vulnerability.
Why would an open-redirect happen? Because of multiple parsers!
As we saw, store_location stores the full path of the URL (this is also due to the fact that Ruby ignores multiple slashes in URLs). This means it stores /////evil.com in its cache. When URI.parse is called, it trims off two extra slashes, so we now have ///evil.com. When a browser (i.e. Chrome) receives this URL, it treats it as a network-path reference and will redirect the client to http://evil.com.
The reason that browsers today tend to "forgive" such URL mistakes (and attempt fixing them) is due to the fact that over the years, browsers have had to deal with many imperfect/non RFC-compliant URLs. Since browsers wanted to be robust to client/developer errors, over time they’ve decided to omit/add slashes in common mistakes.
This is a snippet from the Chromium project source code:
Other vulnerabilities
Here are some other vulnerabilities that have been yielded by differences between parsers:
Flask-security (Python, CVE-2021-23385)
Flask-security-too (Python, CVE-2021-32618)
Flask-User (Python, CVE-2021-23401)
Flask-unchained (Python, CVE-2021-23393)
Belledonne’s SIP Stack (C, CVE-2021-33056)
Video.js (JavaScript, CVE-2021-23414)
Nagios XI (PHP, CVE-2021-37352)
Clearance (Ruby, CVE-2021-23435)
Recommendations for avoiding URL confusion
Since the core of the issues discussed in this post are a result of multiple parsers and their approach, it is important to be aware of which parsers are present within your application when constructing such. This gets more complex with current architectures (i.e. microservices and meshes) and may require some time to fully understand which parsing actors present in your application and what is the journey of a request in your application.
Once the parser list is curated, it is critical for the developers to fully understand the differences in the parsing logic between each parser, such that the developer can remain productive without compromising the application.
Generically speaking, we recommend the following:
Use as few different parsers as possible. By doing so, you'll minimize the "confusion" surface and reduce the amount of feasible parsing issues.
Single parsing point for decentralized systems. If your request is being passed over and over between various components in your system, there's a good chance different parsers will be called (i.e. due to different services in different languages). In order to mitigate this you may parse the URL once at your system's request entry point and pass the parsed request. This way there's only one parser in use throughout the request's journey.
Understand the differences in parsers used by your business logic. As we sometimes need to parse URLs as a part of our code/business, it is important for the developers working on the feature to understand the variations between the parsers (as stated above).
Read the URL Confusion white paper
Dig deeper into the types of URL confusion by reading the white paper.