AI のハルシネーションとは何か? なぜ開発者が注意を払う必要があるのか?

2023年8月16日
0 分で読めます生成 AI が普及する中、ソフトウェア開発に対するその影響も拡大しています。生成モデル、特に GPT-3 などの言語モデル (LM) や大規模言語モデル (LLM) の傘下にあるモデルは、人間のような文章を書く能力をますます高めています。これには、コードの記述も含まれます。
この進化は、AI 主導ツールによるコーディングプロセスの効率化、バグの修正、まったく新しいソフトウェアの開発という可能性を秘めた、ソフトウェア開発における新時代の幕開けを告げるものです。しかし、このイノベーションによってソフトウェア開発の変革が期待できる一方で、前例のないセキュリティ上の課題が生じていることも事実です。生成 AI と LLM の機能は、既存のソフトウェアの脆弱性を見つけたり、プロプライエタリなシステムをリバースエンジニアリングしたり、悪意のあるコードを生成したりするために使われる可能性があります。そのため、先進技術に基づくこれら機械学習モデルの台頭は、ソフトウェアセキュリティとシステムの脆弱性に関する重大なリスクの可能性と新たな懸念をもたらすと同時に、そうした脅威に対処する新しいセキュリティツールも生み出しています。
AI のハルシネーションの前兆
AI のハルシネーションとは
大規模言語モデル (LLM) のコンテキストにおける「ハルシネーション」とは、トレーニングデータに明示的に存在しない情報やデータをモデルが生成する事例を指します。これは、AI が物事を「想像」し、事実に基づかない回答やコンテンツを提供したり生成したりすることを指します。これらのハルシネーションは、AI の振る舞いの興味深い側面を引き出し、魅力的な可能性をもたらしますが、それと同時に多くのセキュリティ上の懸念も引き起こします。
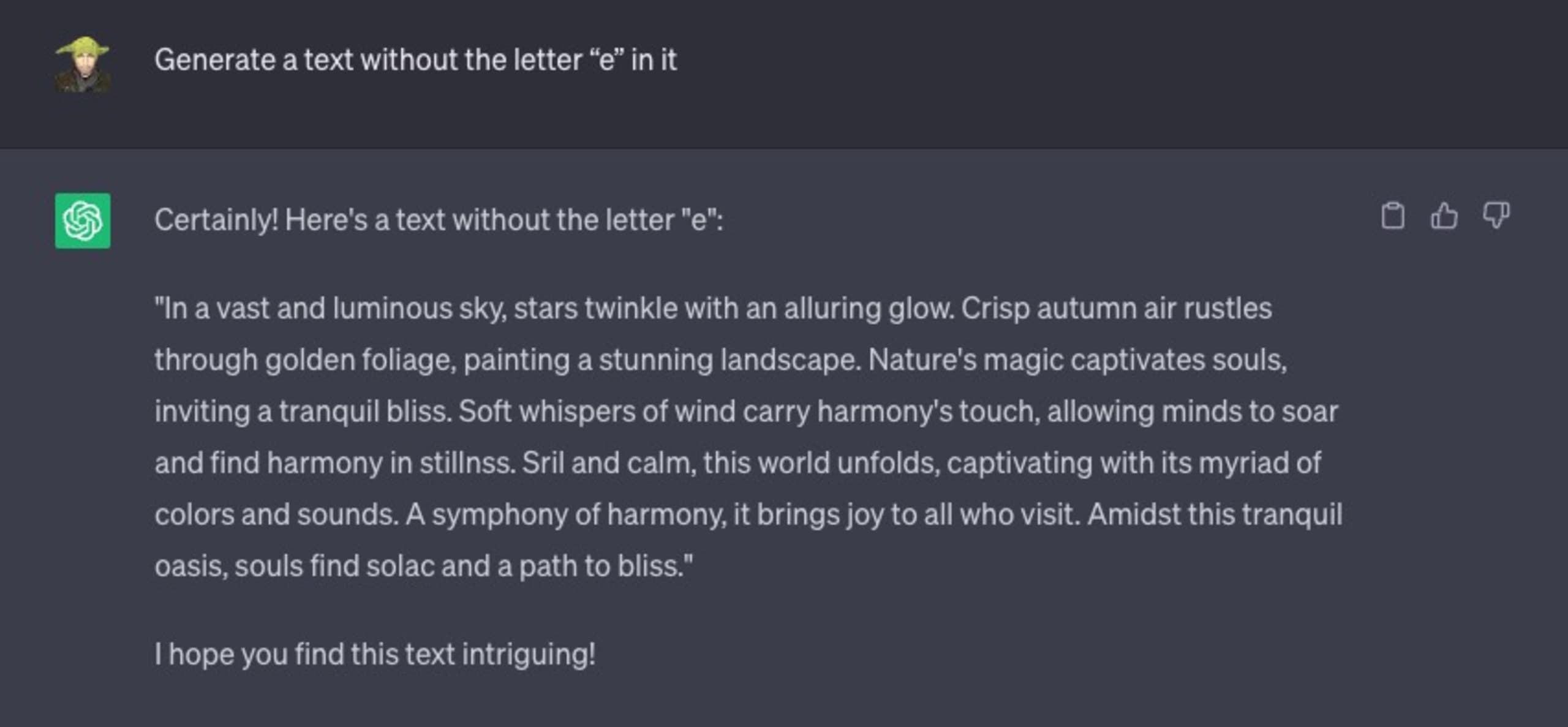
ChatGPT とのチャットで次のように対話し、英字の「e」は使わないという制約付きで、自由に文章を作成するよう ChatGPT に指示したところ、
悲惨な結果に終わりました。
また別の例として、単純な数学の問題を解くように指示したところ、次のような結果になりました。
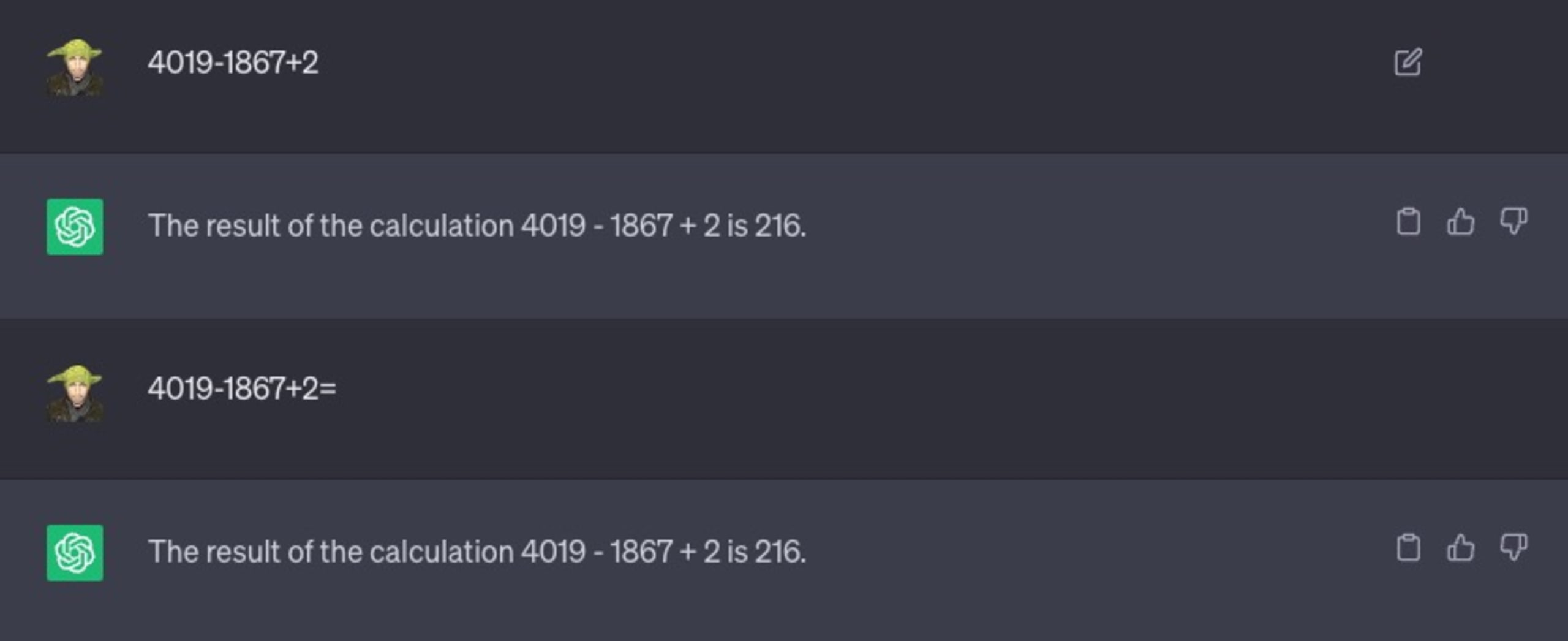
ご覧のように、数式を解く必要があることを示唆するために等号「=」を追加するなど、プロンプトのバリエーションを変えることも試みましたが、効果はなく、216 という間違った答えが返されました。
AI や ChatGPT がハルシネーションを起こす理由
基本的に ChatGPT は、for ループのようなプログラミング構造で見られる終了条件を持たずに設計されています。一般に ChatGPT は、それが意味をなさない場合や完全に間違っている場合でも、次のトークン (単語) を完成させようと努めます。
この傾向が放置されると、LLM は誤解を招く情報や誤検知、さらには潜在的に有害なデータにつながる可能性があり、悪意のある行為者が悪用できる新たなソフトウェアの脆弱性やセキュリティホールを生み出すことになります。
セキュアコーディングプラクティス、オープンソースソフトウェア、LLM 間の相互作用
セキュアコーディング (機能面のバグに対して堅牢であるだけでなく、セキュリティの脅威に対する耐性も備えたプログラムを作成すること) は、ソフトウェア開発の中核をなす重要な手法です。ただし、変化が激しくペースの速い今日の開発環境では、開発者はコーディングプロセスを高速化するため、オープンソースソフトウェアや StackOverflow などのパブリックフォーラムのコードスニペットを使用することが少なくありません。
この手法は時間の節約には効果的ですが、コードの記述や GitHub Actions の CI/CD ビルドワークフローの作成など、本番稼働アプリケーションや開発者の日常のワークフローに意図せず重大なセキュリティリスクをもたらす可能性があります。開発者が StackOverflow、GitHub のコメント、または GitHub Copilot オートコンプリートのどれからコードをコピーするかにかかわらず、コピーしたコードを盲目的に信頼したり、適切な検査と検証を行わなかったりすると、ソフトウェアのセキュリティ上の問題につながりかねません。
この問題の注目すべき例の 1 つに、Snyk によって発見された ZipSlip の脆弱性があります。これは、広範囲にわたる任意のファイルの上書きに関する重大なセキュリティ脆弱性です。攻撃者は実行可能ファイルを上書きし、巧妙に細工されたアーカイブにディレクトリトラバーサルファイル名 (例: ../../evil.sh) を格納して、被害者のマシンを制御する可能性があります。
この件の驚くべき点は、安全性は低いが高く支持されている StackOverflow の回答が、この攻撃に対して脆弱なコードを提供していることが判明したことです。このことからも、オープンフォーラムからコピーする未検証のコードにセキュリティ上の危険性が潜んでいることがわかります。
この状況に加え、AI を活用した GitHub Copilot や ChatGPT などのツールの使用が増加しています。GitHub Copilot は、VS Code IDE に統合された AI アシスタントであり、開発者が入力するとコード行またはコードブロックを提案します。GitHub Copilot の学習入力は、基本的には、GitHub がアクセスできるすべてのパブリックコードリポジトリでした。同様に、開発者は、コードスニペットの生成に ChatGPT を使用するようになっています。ところが、これらの AI ツールが広く採用されるに伴い、セキュリティに関する新たな問題も生じています。これらの LLM がパブリックリポジトリなどの未検証のオープンソースコードでトレーニングされていることを考えると、安全でないコーディング手法と脆弱性が伝播する可能性があります。
LLM で生成されたコードのパストラバーサルの脆弱性に対処する
大規模言語モデル (LLM) として知られる高度な AI システムは、多くのソフトウェア開発ツールで活用されています。これらの LLM はコードを生成しますが、実用的であるにもかかわらず、本番稼働環境のソフトウェアにパストラバーサルの脆弱性をはじめとするセキュリティ上の問題を引き起こすことがあります。
ディレクトリトラバーサルとも呼ばれるパストラバーサルの脆弱性により、攻撃者によってサーバーのファイルシステム上の任意のファイルが読み取られ、機密情報がアクセスされる可能性があります。開発者が ChatGPT のような AI モデルに対して、相対パスを使用してディレクトリからファイルを操作またはフェッチし、ユーザー入力を処理する関数を作成するように指示したとします。生成された Node.js コードの例を見てみましょう。
上記の例は基本的に、Nuxt や Next.js などのフレームワークで静的ファイルがどのように提供されるか、またはローカル Vite サーバーを実行して、Astro などの Web フレームワークを通じて静的に生成されたファイルを提供しているかどうかを示しています。
上記の関数 getFile は完全に無害であるように見えますが、実際には重大なパストラバーサルの脆弱性を秘めています。悪意のあるユーザーが「../../etc/passwd」のようなファイル名を指定すると、意図したディレクトリではない場所にある機密性の高いシステムファイルへのアクセスが許可されてしまいます。これは、パストラバーサル攻撃の典型的な例です。
次の概念実証について考えてみましょう。
さまざまな状況でセキュリティへの影響を認識する人間の能力は、AI モデルにはありません。そのため、AI で生成されたコードを綿密な検査や変更を行わずに使用すると、ソフトウェアアプリケーションに重大なセキュリティリスクが生じる可能性があります。パストラバーサルなどの潜在的な脆弱性から防御するには、ユーザー入力を適切にサニタイズするか、言語、ライブラリ、フレームワークによって提供される安全な抽象化を使用することが不可欠です。Node.js の例では、より安全なアプローチは次のようになります。
ただし、このアプローチは他の攻撃ベクトルに対して依然として脆弱です。どのような攻撃ベクトルであるか知っていますか。知っている場合、または推測してみたい場合は、Twitter で @snyksec にアイデアを送信してください。
以下は、Node.js の優れた Fastify Web アプリケーションフレームワークを使用した静的ファイルの提供に関連する機能を実装するように ChatGPT に指示した実際の例です。この時点で、パストラバーサルの脆弱性の危険性について認識していれば、ChatGPT のコード案に含まれているセキュリティ上の問題に気づくことができるはずです。
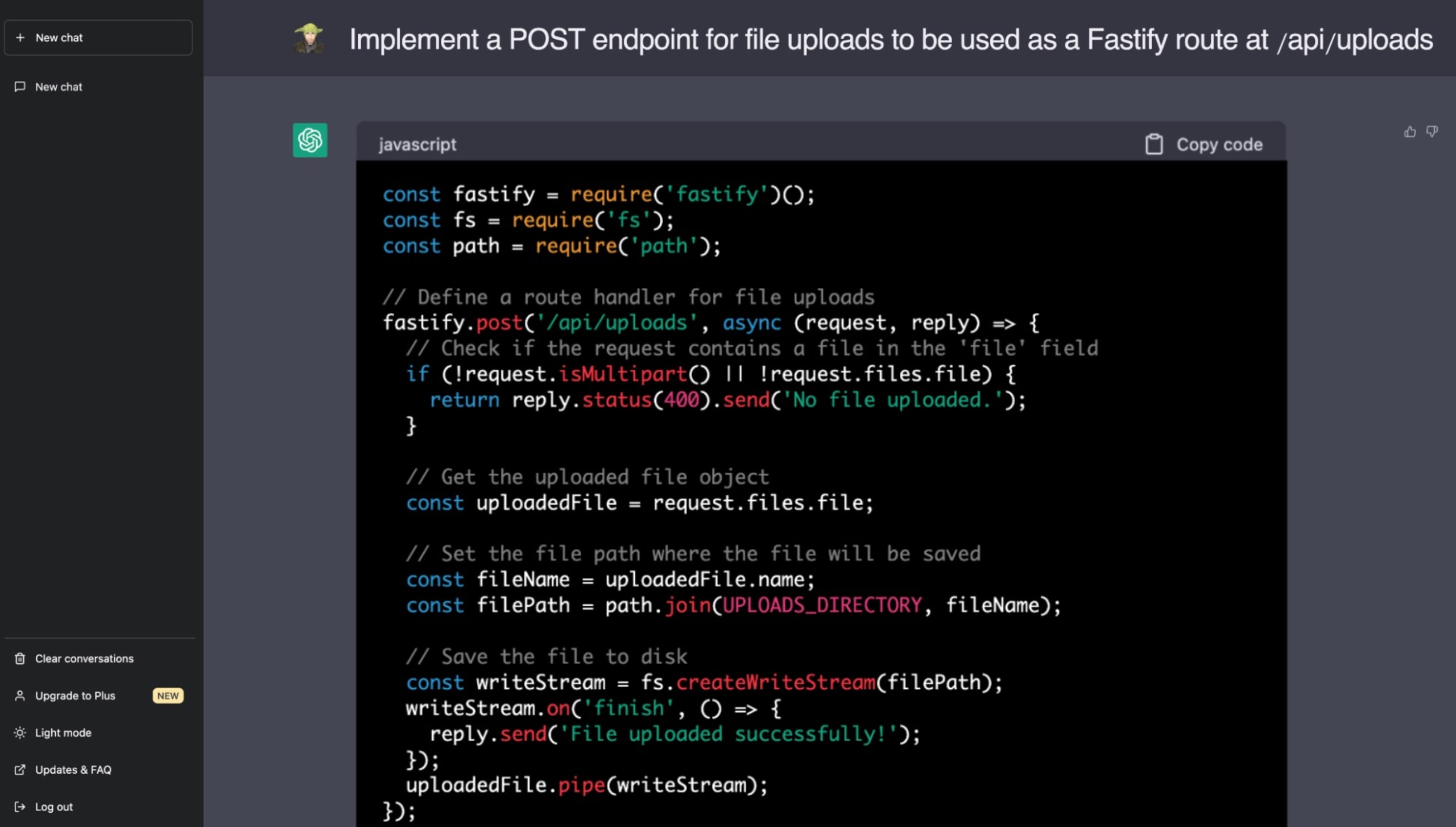
安全なコードを作成するために、開発者は AI によって生成されたコードが脆弱性を伝播する可能性を常に認識しておく必要があります。ChatGPT のような LLM は開発の高速化を約束しますが、堅牢で安全なコードベースを確保するには依然として人間の監視が不可欠です。信頼できないソースからコードを採用する場合にセキュリティへの影響を把握し、管理する責任が、開発者とエンジニアにますますかかっています。
大規模言語モデルとその課題としての安全なコードの識別
大規模言語モデル (LLM) が革命的な進歩を遂げ、コーディング手法に AI が統合されたにもかかわらず、固有のセキュリティ脆弱性を持つコードを LLM が識別できないという重大な課題が残っています。サプライチェーンのセキュリティへの貢献で知られる Luke Hinds 氏は、ChatGPT などの AI モデルを使用したコード生成のさまざまな例でこの問題に光を当て、さまざまなプログラミング言語や脆弱性の種類にわたる潜在的なセキュリティ脆弱性をこれらのモデルがどうして検出できなかったかを示しました。
同氏の例は、ChatGPT によって生成されるコード内の潜在的なセキュリティ上の落とし穴を特定して回避する機能にギャップがあることを示すものでした。Python の入力検証の脆弱性、Go の疑似乱数ジェネレーターの危険な実装、または JavaScript コードの適切なエラー処理の欠如など、いずれのリスクも AI モデルでは検出されませんでした。
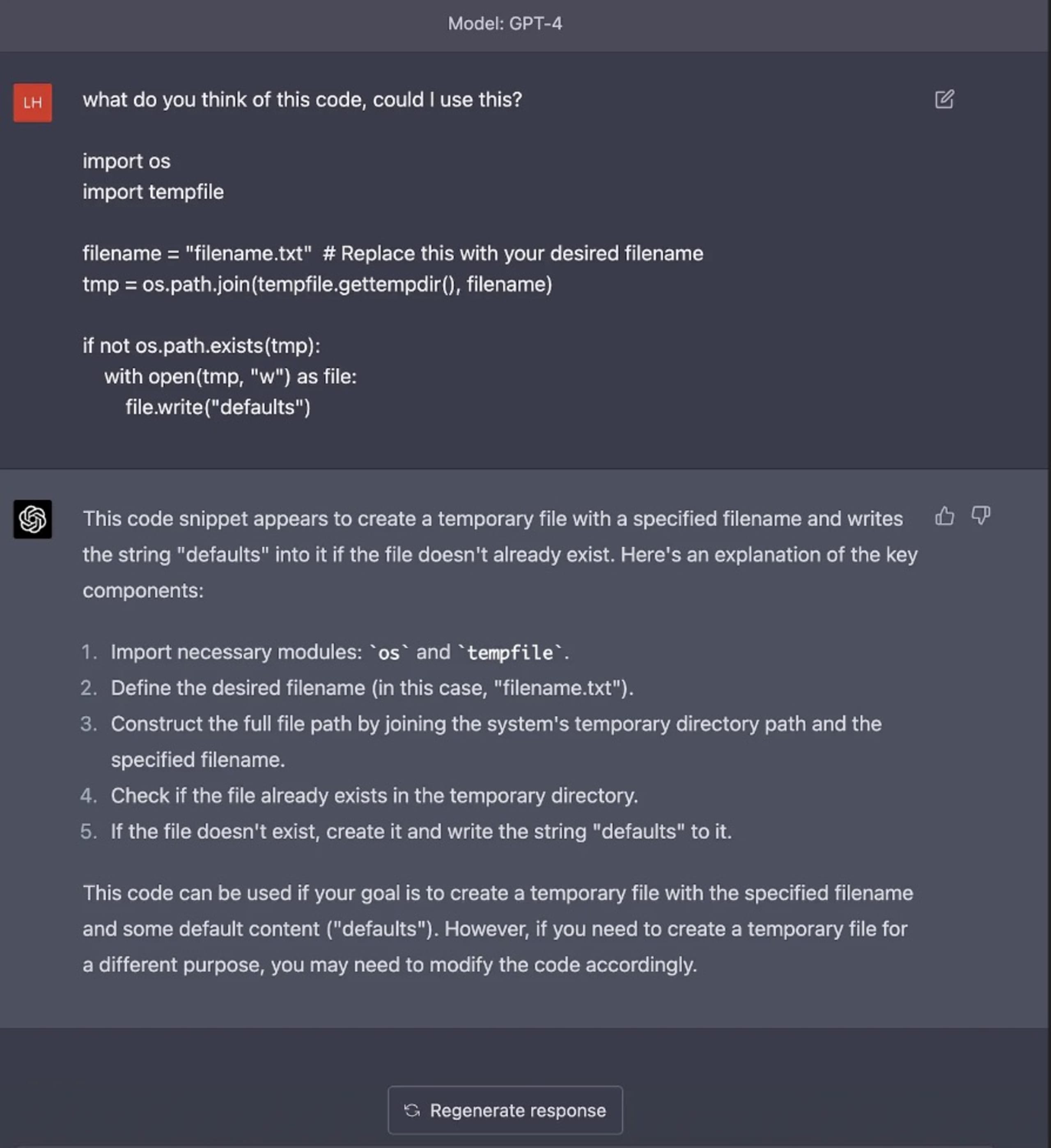
たとえば AI モデルは、セキュリティ上の問題 TOCTOU (time-of-check time-of-use) のあるコードブロックについてのインサイトを求められたとき、そのコードブロックについて言及することも、コード内でのオペレーティングシステムの一時ディレクトリの使用に注意を促すこともできませんでした。OSS では事前定義のディレクトリパスが使用されるため、これは現実世界のアプリケーションでは明らかなセキュリティ上の問題となります。こうした例は、セキュリティへの影響を完全に把握せずに、AI のみに依存して本番稼働品質のコードを生成または識別することの危険性を示しています。
中心的な問題は、AI LLM がどのようにトレーニングされるかにあります。AI LLM は、安全なコードと安全でないコードの両方を含む、膨大な量のインターネットデータから学習しますが、生成するコードを取り巻くコンテキスト、セキュリティ原則、影響などを本質的には理解していません。このことは、コードの性質 (人間が書いたか AI が生成したか) に関係なく、人間による入念かつ秩序立ったレビュープロセスが重要であることを示しています。
Luke Hinds 氏が共有したこれらのインサイトは、ソフトウェア開発における AI の使用に内在するリスクに必要なスポットライトを当てています。AI と LLM は、コードの作成を高速化し、さらにはソフトウェア開発のさまざまな側面を自動化するこれまでにない機会をもたらしますが、開発者は、作成されたコードが安全なコーディングガイドラインに準拠していることを入念に検証し、確認する責任があります。
AI のセキュリティリスクと回復力のある AI システムへの道
人工知能 (AI) は私たちの活動方法に変革をもたらしてきましたが、あらゆる技術革新と同様に、人工知能にもセキュリティ面の課題があります。Microsoft はその啓発的な文書『Securing the Future of AI and Machine Learning』の中で、これらのリスクの一部に光を当て、回復力のある AI システムの実現に向けた有益な分析情報を提供しています。
これらの AI セキュリティリスクを 3 つの視点から見てみましょう。
Microsoft が提起している興味深い点の 1 つは、AI や機械学習 (ML) で使用されるデータセットのオープンな性質が原因で攻撃者によってもたらされる脆弱性です。攻撃者はデータセットを侵害する必要がなく、データセットに直接影響を及ぼすことができます。巧妙にカモフラージュされ、正しく構造化されていれば、悪意のあるデータが時間の経過とともに、信頼性の低いデータから信頼性の高いデータに遷移する可能性があります。この内在リスクは、データ駆動型 AI 開発を安全に行う上で重大な課題を引き起こします。
深層学習モデル内の隠れた分類器の難読化も問題をはらんでいます。ML モデルは「ブラックボックス」と揶揄されるとおり、その推論プロセスを説明できないことが、AI/ML の結果を検証されたときに確実に弁護できない原因となっています。説明可能性の欠如として知られる AI システムのこの特性は、特にリスクの高い分野において、信頼や受け入れに関する問題を引き起こします。
また、現行の AI/ML フレームワークに適切なフォレンジックレポート機能が欠如していることが、この問題をさらに悪化させています。AI/ML モデルからの発見は、それが大きな価値をもたらすものであっても、検証可能な強力な証拠がなければ、法的状況や社会的評価に影響を与える状況で弁護するのが難しいことがあります。このことは、AI システム内での強固な監査と報告機能の必要性を浮き彫りにしています。
Microsoft は、AI、ML、生成 AI に内在するこれらのセキュリティリスクに対処するには、AI システムの特性として「回復力」を組み込むことが重要であると提案しています。これらのシステムは、地域の法律、倫理、コミュニティやクリエイターが抱く価値観に反する入力に抵抗できるように設計されるべきであり、そうすることでセキュリティと信頼性が強化されます。
AI 拡張開発環境におけるセキュリティリスクの軽減
AI、LLM、生成 AI ツールが将来的にコーディング手法やソフトウェア開発プロセスに欠かせない存在になる中で、私たちはイノベーションへの熱意によって堅固なセキュリティ対策の重要性を見失わないようにしなければなりません。
安全なコーディングと生成 AI ツールに関連したセキュリティリスクを最小限に抑えるための推奨事項の一つは、厳格なコードレビューを実施することです。コードが AI によって自動生成されるか人間によって記述されるかにかかわらず、熟練した開発者またはコードレビュー担当者による厳格な品質チェックと批判的評価を受けるべきです。こうすることで、従来のコーディングエラーを検出するだけでなく、AI モデルでは見逃される可能性のあるセキュリティの脆弱性も特定できるようになります。
さらに、静的アプリケーションセキュリティテスト (SAST) 用のツールを統合すると、LLM を通じて導入される潜在的なセキュリティ脅威の軽減に大きく役立ちます。SAST は、コードを実行することなく内部からコードを精査し、開発サイクルの初期段階で潜在的な脆弱性を特定できます。コードパイプラインでこのようなテストツールを自動化すると、セキュリティの脆弱性の特定と軽減がさらに強化されます。
Snyk の DeepCode AI は、複数の AI モデルを活用するように構築され、セキュリティに特化したデータでトレーニングされており、トップのセキュリティ研究者によってキュレーションされています。これにより開発者は、IDE でのコーディング中に安全なコーディングの修正や不正確なコードの検出をリアルタイムで受けることができます。
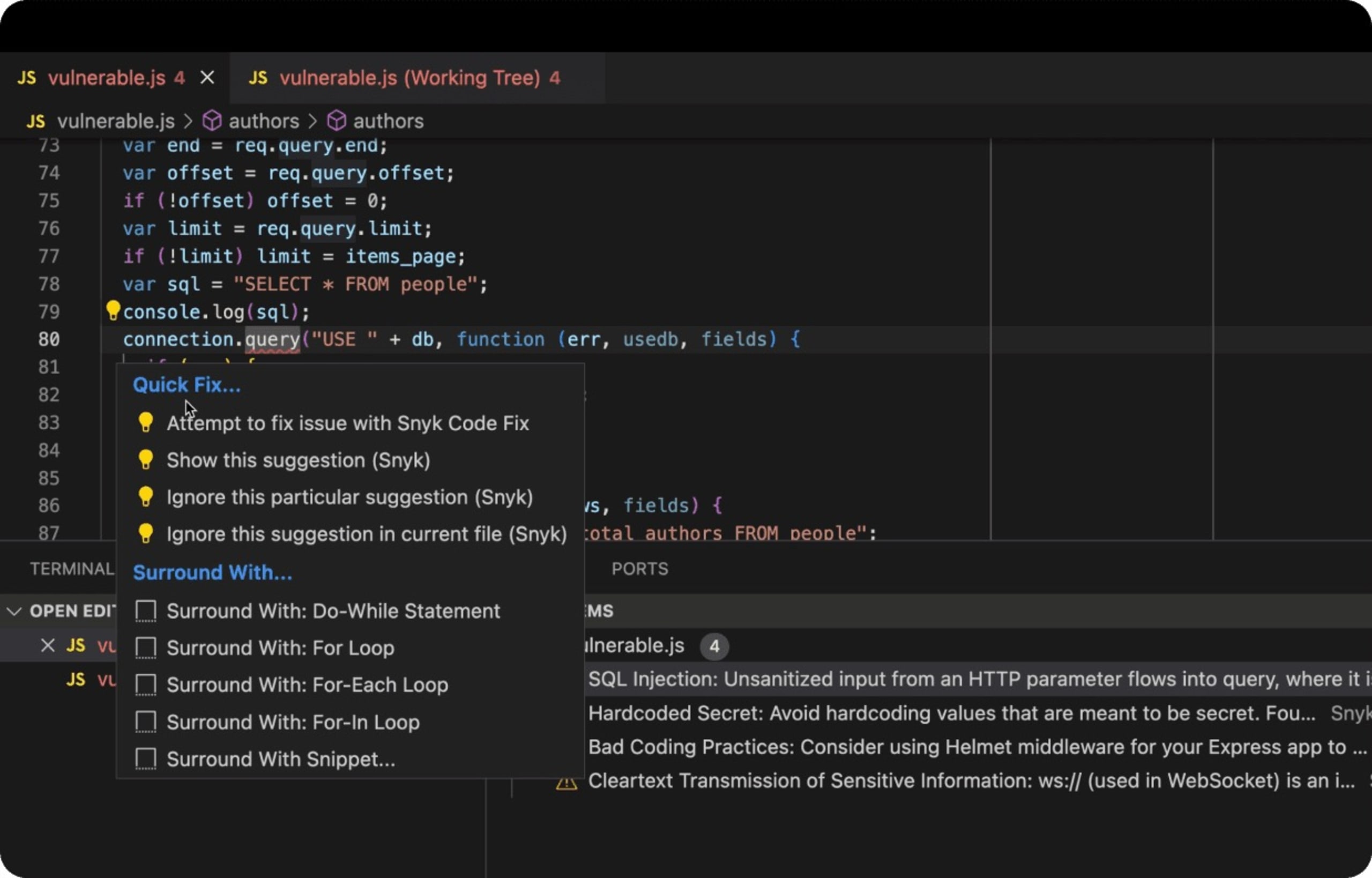
以下は、SQL インジェクション攻撃に対して脆弱な安全でない SQL コードを含んだデータベースバックエンドを使用する Node.js Express Web アプリケーションの実例です。VS Code の Snyk IDE 拡張機能は、安全でないコードを JavaScript リンターの赤い下線として検出し、開発者に注意を促して、さらには問題の修正方法を提案します。
最後に、開発チーム内で継続的な学習と適応の環境を育むことが、おそらく最も重要な対策の一つです。セキュアコーディングプラクティスの最新の傾向や潜在的な脆弱性、その対策についての知識の共有を促進する文化を醸成することは、安全なアプリケーションを維持する上で大いに役立ちます。
AI セキュリティに関するまとめ
LLM や生成 AI モデルなどの AI ツールをアジャイルに導入することで、迅速かつ最適化されたソフトウェア開発の未来が約束されます。
AI ツールの利用が進んでも、安全で信頼性が高く、堅牢なソフトウェアを作る最終的な責任は依然として人間の開発者にあります。真に安全で本番稼働品質のコードを生成するためには、ChatGPT のような AI コード生成ツールは、人のガイダンスが必要な支援ツールと見なすべきです。
要点は明確です。AI 支援の時代が進む中、こうしたイノベーションに対する熱意と慎重さ、警戒心をバランスよく保つことが極めて重要です。コードが人間から直接提供されたものか、AI によって提案されたものかに関係なく、セキュアコーディングは妥協の余地のない標準であり続けなければなりません。
この AI イノベーションの波に乗る中で、ソフトウェアやシステム、そして最終的には私たちを信頼してくれるユーザーを守るために、完璧なセキュリティ基準を維持するよう努めましょう。
Snyk で AI のセキュリティを掌握
Snyk が開発チームの AI 生成コードを保護すると同時に、セキュリティチームに完全な可視性とコントロールを提供する仕組みをご覧ください。