How Snyk Code prioritizes vulnerabilities using their Priority Score
Frank Fischer
November 9, 2021
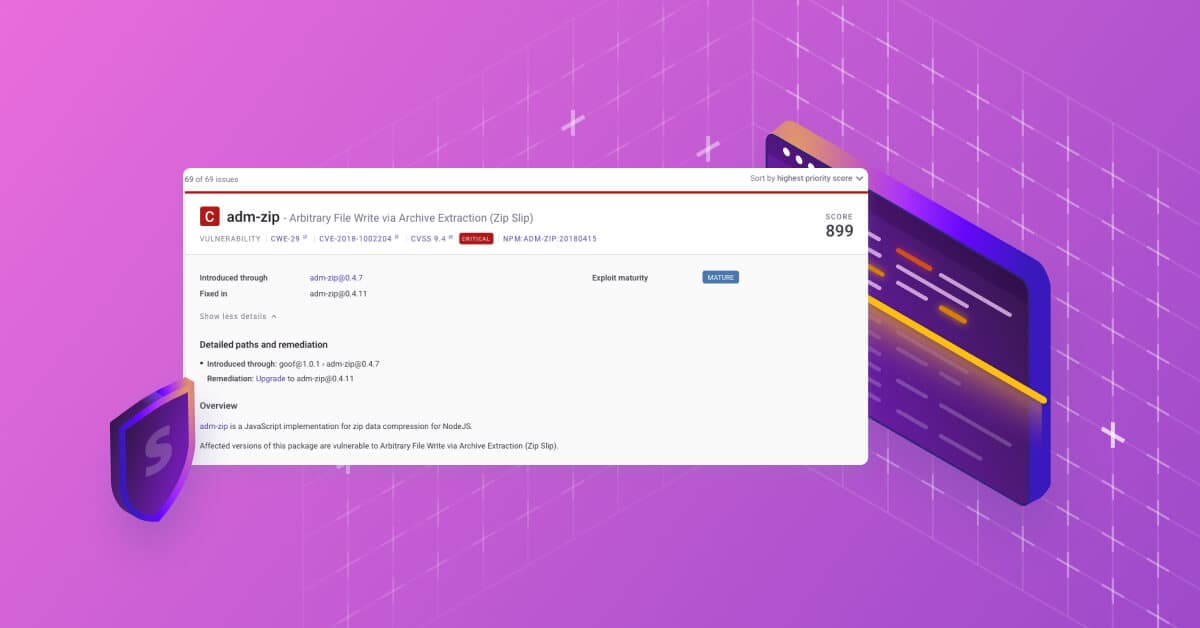
0 mins readIf every vulnerability seems to be equally critical, engineers would get overwhelmed and probably waste time on the wrong issues. This is why it’s important for developer security tools to provide clear and simple prioritization functionality. As you’ve likely noticed, Snyk Code provides a Priority Score on the top right corner of the overview panel. When hovering over it, an explanation is shown how the priority score was calculated. And for speedy prioritization, you can sort by Priority Score in the top right corner.
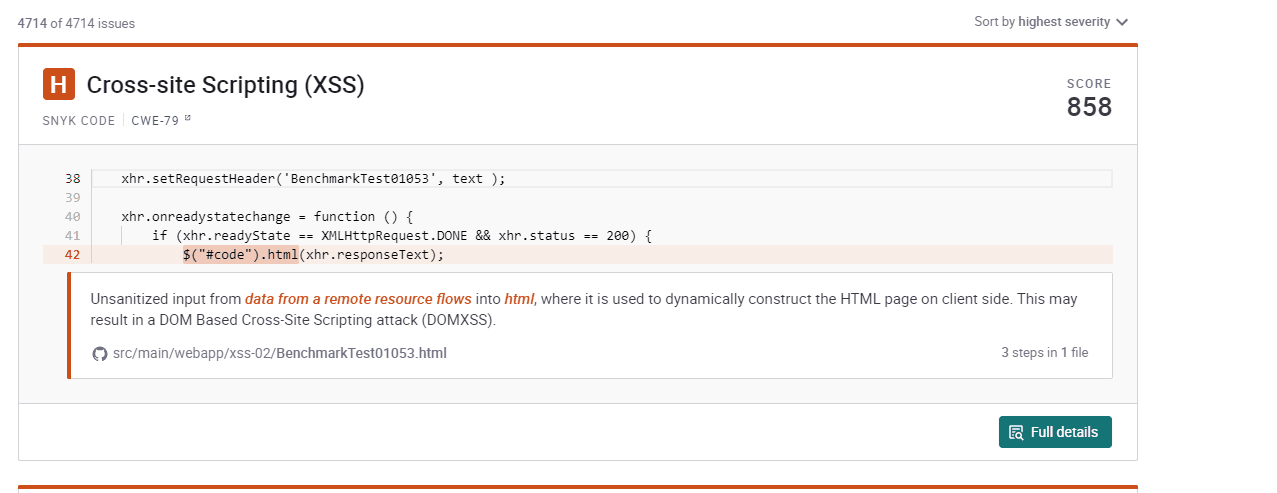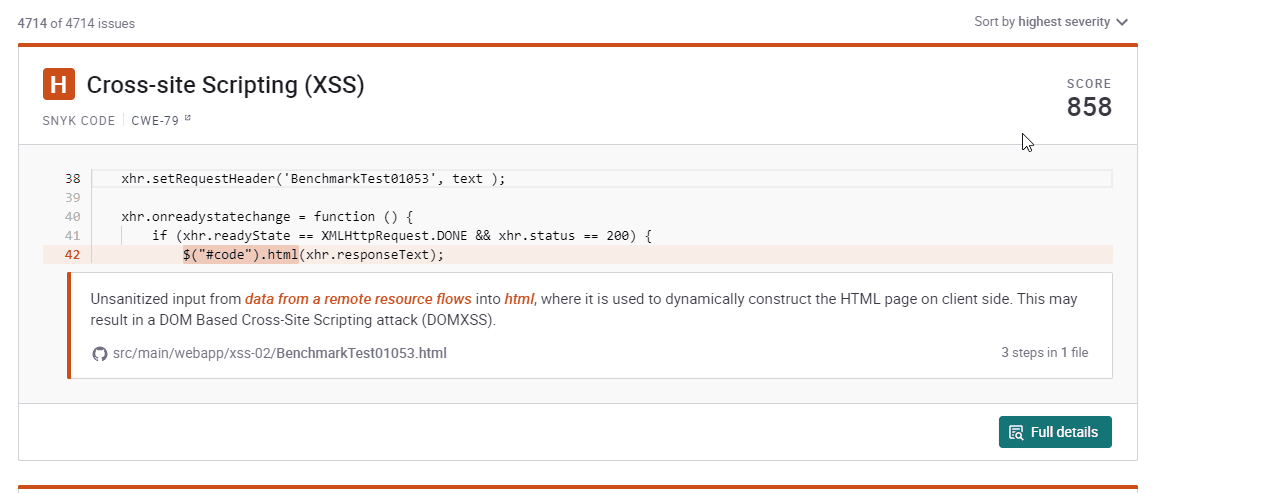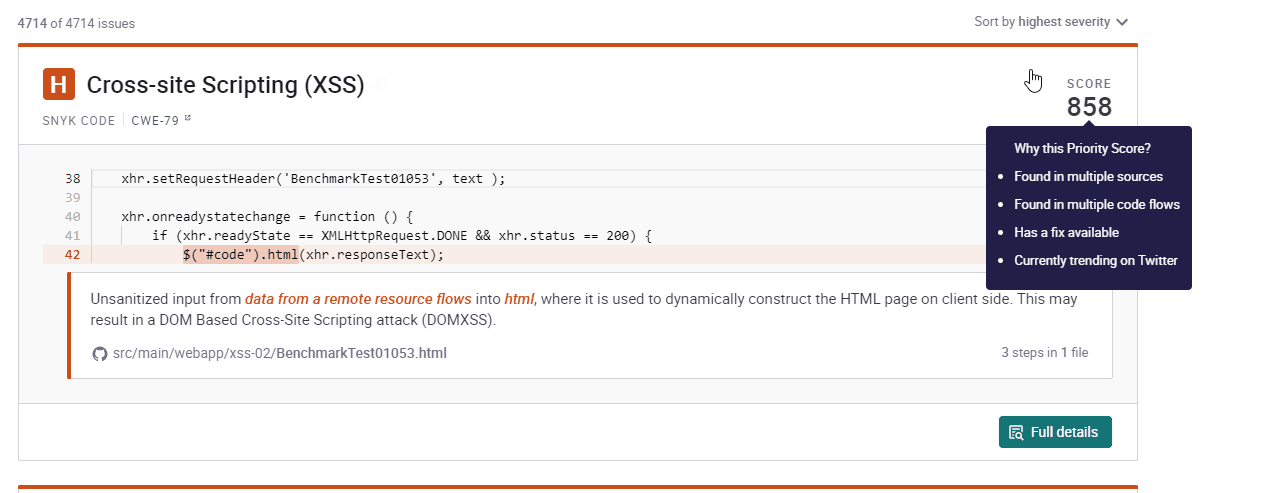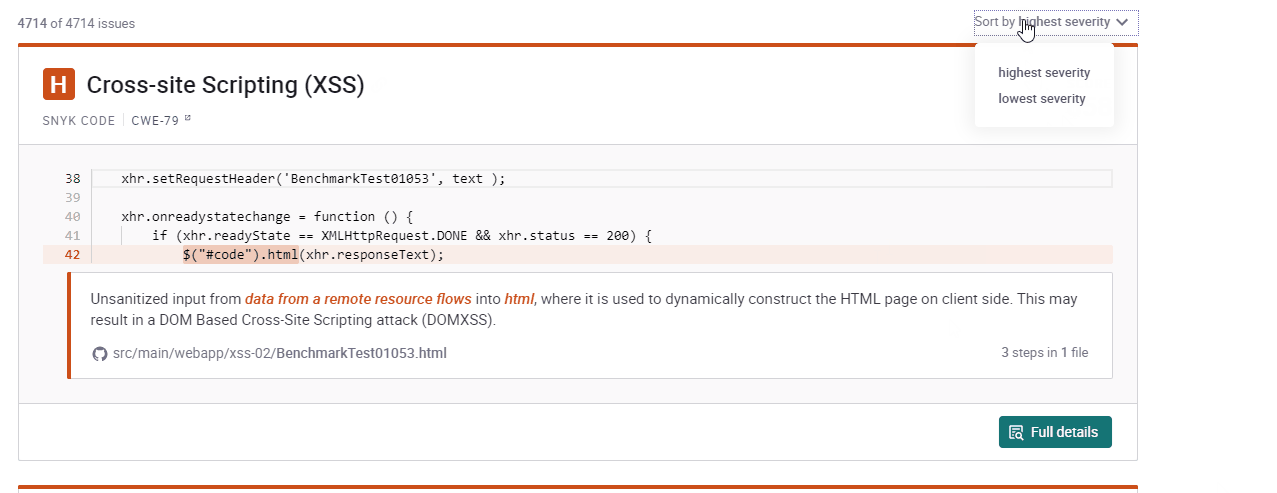
But a Priority Score is more than just a number. In this article, I want to introduce you into the thinking process behind the score as well as give you some practical tips on how to use it optimally.
Note: As you will see, we’ve made specific decisions on how to calculate the score. Maybe you would have decided differently, and this is fine! There is no perfect answer and we are always interested in productive feedback.
The Basics of Priority Score
For starters, a Priority Score is an integer number between 1 and 1000. The higher the number, the stronger that Snyk Code suggests you remediate the vulnerability. It’s very important to note that while the Priority Scores of Snyk Open Source or Snyk Container look similar, we do not advise you to compare scores across products. Only compare Snyk Code scores with other Snyk Code scores.
The Priority Score shall help you to be effective in increasing the security of your application. For Snyk, this translates to impact and action. While the severity of a vulnerability is important, we need to look deeper. With impact, we look to see if a fix might address multiple vulnerabilities. If it does, the Priority Score goes up. With actionability, Snyk Code determines how easy it is to remediate a vulnerability. If a fix is quick and easy, the Priority score goes up.
With this added depth of analysis, we can prioritize fix remediation in a way that maximizes engineering’s time.
How the Priority Score is calculated
As a mathematical function, the Priority Score is calculated by adding points based on facts of the issue. The score is recalculated every time a snapshot and scan is performed. Priority Scores — even if snapshots are taken in close succession — might differ (we’ll explore why below). Snyk provides all data points used to calculate the Priority Score in a JSON data file.
Note: The following describes how it is calculated as of September 2021. We are constantly researching and learning, plus the cybersecurity space is fast moving. We might decide to change the calculation in the future. At Snyk, we are always evaluating the logic behind Priority Scores to maintain industry-leading efficacy in an evolving threat landscape.
Severity
The severity assigned by the scanning engine to the issue found counts for 50% of the priority score overall. If the engine assigns `High` severity, this parameter is 500 points, `Medium` is 250 points, and `Low` is 100 points. It’s important to note that the engine already uses a heuristic to assign the severity level. As our engine is context aware, it takes aspects of the context into account. For example, if the issue is found/originating in a test file, severity will be adjusted.
The other 50% of the score comes from various facts:
Occurrences
The relative number of occurrences of the vulnerability at hand translates into points. As an example, imagine your program has 10 issues of three issue types: 5 x A, 2 x B and 3 x C. So C would get 30 points. The idea here is to cluster issue types together and promote remediation that addresses them all at once. Because if you can fix one occurrence, you can fix them all.
Hotfiles
Hotfiles are files that are responsible for multiple issues. Snyk Code assigns 100 points of the sink to hotfiles, 50 points when the code flow traverses a hotfile, and 0 if it actually does not touch hotfiles (e.g., files the engine identifies as test files are excluded). The underlying idea here is to focus your work on hot areas within the application to reduce context switching between several files. Also it takes into account that fixing one issue could actually lead to the remedy of other, neighboring ones.
Fix examples
If Snyk Code has good examples from open source how an issues has been fixed previously, this is worth 200 points. We do this because we believe this makes the issue so much more actionable. Previous fixes help you address issues quickly and easily, and quick wins — to be honest — are great for keeping teams motivated.
Commonly fixed in OSS
This is an interesting one. If the engine sees a vulnerability in more than 1,000 repositories in our open source training set, it assigns 100 points. There are several reasons for this:
If the vulnerability is that prevalent, the chances of exploitation — even by script kiddies — increases, which makes it more dangerous.
If the vulnerability has already been addressed hundreds of times, a best practice on how to fix it exists and can be applied.
Best Practices for Priority Score
As you’ve seen above, the Priority Score is a powerful tool that can guide your remediation efforts. We encourage you to make use of it. Before wrapping up, here are some other best practices for using Priority Scores:
In the Snyk UI, you can filter the result set to an upper and a lower threshold of the Priority Score.
Since the Priority Score is recalculated each time you scan and is influenced by code changes, we advise to always use the latest score value. So, instead of doing a scan and generating 10 Jira tickets out of the top 10 issues found, fix an issue and rescan. Use the new Priority Score leader which might be different based on previous remediations.
Do not compare Priority Scores from different Snyk solutions. They describe different things and are backed by different, non-comparable logic.
Hover over your score and have a look at the reasons that led to the Priority Score. Sometimes “shopping” a bit for an easy fix to start with can help you have some success at the beginning. Motivation is key!
Get started in capture the flag
Learn how to solve capture the flag challenges by watching our virtual 101 workshop on demand.