Simplifying container security with Snyk’s security expertise
Hadas Bloom

March 8, 2022
0 mins readThe most beautiful and inspiring aspect about open source code is, well, that it’s open source. We can look at open source packages like gifts that are exchanged between developers across the engineering world, allowing them to learn from the work other people do, contribute their own expertise, and grow their professional capabilities. Contributing to open source is much appreciated, and it is important to remember not only to benefit from these projects, but also to contribute back. This community collaboration evolves open source continually, with shared knowledge and packages acting as foundations for new, exciting technologies.
But these free-to-use libraries and projects also bring risks with them, whether by mistake or by malicious actors — and this is exactly where and why Snyk comes in.
Naturally, with the continued evolution of open source technologies, like new and evolved Linux distributions and container tools like Docker, more and more bundled images of these open source packages are created and used. Basically, a container image is a file that contains the code, libraries, dependencies and other tools and files needed for applications to run. A container,then, is the running instance of that image, and it defines the “space” in which the application runs and is developed. A container allows you to create an environment in which your code can work, and relies on the image, and, in fact, is started up from the image. Even better, and one of the most powerful aspects of container images, is that they can build upon each other. You could start with an image that has just the basic Linux elements — maybe you get something like alpine from Docker; layer on language-specific tools and frameworks to create a language-specific image; then layer on some development tools for that language; then finally your own code specifics.
So if an image is just a file with a set of packages, you’re probably already asking yourself what is the challenge in determining which vulnerabilities affect them? Can’t we assume that if a vulnerability exists in an open source package, and that open source package is used in an image, that the image is vulnerable? That’s a wonderful question, thank you for asking! Just as the usage of a base image, like alpine in our example above, brings you many tools and opportunities, each package also brings you the possibility of adding vulnerabilities under the hood. All of a sudden, discovering vulnerabilities in your own code is not enough — you need to make sure your base image, and all the images you create as you layer on your tools, is secure as well.
For the purposes of this blog, we’re going to focus on that very first part of the image — the parent image you first select to build upon (alpine in the example). That layer tends to be where most of the core Linux packages are introduced, and where the Linux package manager itself is added. It’s also an area that tends to introduce confusion because, unlike all the other things you might choose to add, you have the least amount of control in what you get in that base image. So let’s take a deeper dive into our problem space in the container vulnerability world and then look at how Snyk can help solve that problem.
Understanding Linux vulnerabilities in the container world
Package management system
Each Linux distribution (Alpine, Debian, Ubuntu, etc.) has its own set of maintainers, and while they are all providing a version of Linux, which implies some commonality, they still have the ability to devise their own naming and versioning schemes for updates. This means that they don’t always keep the same name or versions that the corresponding upstream package has, and thus, when you get into the details of fixes for a particular issue, or even just general patches for the system, they could each have different advice for their users.
Let’s take a look, for example, at the fix for CVE-2021-44228, also known as Log4Shell, in the famous log4j package. The upstream package, maintained by the Apache team in Maven, is named logging-log4j2 and the fix for this critical vulnerability was released in version 2.15.0. If you’re a Debian user, however, the name of the package that Debian provides is apache-log4j2and the fix was released in the current stable branch, Debian 11 (“bullseye”), in version 2.15.0-1~deb11u1. In Ubuntu, the naming is similar in this case to Debian, apache-log4j2, but the fixed version in the latest Ubuntu release (21.10) is 2.15.0-0.21.10.1.
To summarize the fixed packages of CVE-2021-44228:
Package Name | Fixed Version | |
|---|---|---|
Java Upstream (Maven) | logging-log4j2 | 2.15.0 |
Debian 11 (“Bullseye”) | apache-log4j2 | 2.15.0~deb11u1 |
Ubuntu 21.10 (“Impish Indri”) | apache-log4j2 | 2.15.0-0.21.10.1 |
This relatively simple example shows us that even if our hard-working security analysts have found or triaged a vulnerability in an upstream open source package, we can’t immediately presume to know which package is based on it in the different Linux distributions, the version numbers that are affected, or even if a particular distribution is affected at all. A different triage process is required for the packages downstreamed to the various images.
The reason the naming and versioning is handled this way, is that it makes it easier for the different Linux distribution teams to follow their own versions, understand based on their own format which upstream version they are using, and allows them to control their own packages. Each distribution manages and is responsible for all the build aspects and compilation of a package that is used in their ecosystem. Maintaining their own package names and versions allows them to control patch releases and backports correctly in their system.
The most correct way to look at this would be to relate to each and every package as a different entity, depending on where we can download it from. If the package “lives” in a certain Linux distribution’s package manager, even if it does have the same name as the one controlled in PyPi, Maven, or others, we need to treat it as a different package that is maintained by a different team that compiled it specifically to match their environment and needs.
Data terminology and structure
Alongside the different package names and versions used by each Linux distribution, there is also a difference in the terms used for defining various aspects of the security data provided by each source.
There can be, for instance, a difference between the definition of “critical” severity. One team can use “critical” more frequently and freely than another team that would usually use “high” severity, and only in very specific situations mark the vulnerability as “critical”.
On the other hand, different terms might actually mean the same thing and be used the same — such as the terms “moderate” and “medium”, which may be used by different teams to express the same severity.
Additionally, when a team uses the term “important”, for example, there needs to be an identification between importance in terms of prioritization for fixing the issue, compared to the importance of the vulnerability itself (i.e its severity is relatively high).
To explain the complexity here, let’s have a look at CVE-2021-3507 affecting Debian:
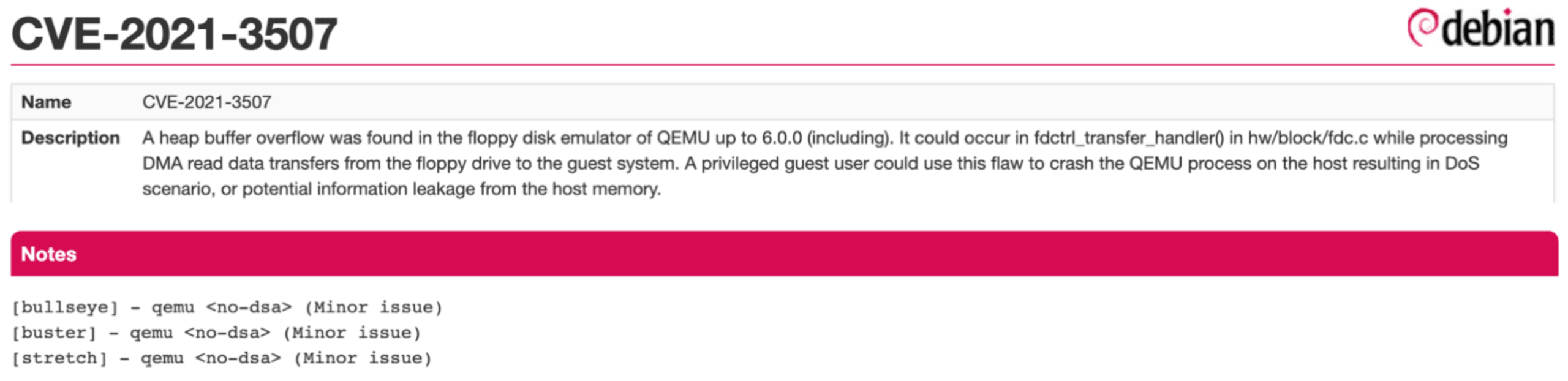
As can be seen in the advisory referenced, this CVE is marked as <no-dsa> (Minor issue) for Stretch (Debian 9), Buster (10) and Bullseye (11). Those are indicators of the severity of this issue, in the Debian maintainers’ view, for those versions of Debian.
NVD, on the other hand, gave this CVE a “medium” CVSS score, which indicates a wider analysis of the vulnerability, especially relevant to the upstream package qemu package.
Multitude of data
Each Linux distribution and each of its releases, contains many packages by default, and many (many) more that can be downloaded from the specific distribution’s repository. This implies that our container could have hundreds of vulnerabilities, affecting packages written in multiple languages. The multitude of vulnerability data in the container environment makes it a more complex challenge for Snyk, for security teams, and for developers using containers, to triage and understand the specific vulnerabilities and what should be done with them. Consequently, doing a deep dive into each and every vulnerability is very challenging.
These unique problems of the world of container vulnerabilities lead to the challenge of identifying the most accurate data within a container. Exactly which vulnerabilities are relevant to a specific container and what is the actual risk of them in the context of how the container interacts with the Linux kernel and with the application running inside, is the question we are continually working on to answer in the most precise way in our container vulnerability team here at Snyk. We built a complex model that takes many different factors into account to accurately identify and prioritize these vulnerabilities.
How are these challenges solved?
After defining the complexity, we can look into the solution for identifying the most accurate data. The process for collecting, analyzing, and raising the correct container vulnerabilities starts with a scalable pipeline that can handle large scale data from many sources in a smartly automated way, but also triggers human interaction when needed. It requires in-depth knowledge based on a combination of security expertise and collaboration with the different Linux distribution security teams, who give the supplementary context we are lacking. From all of this knowledge, derived from many sources, we can gather and choose the most relevant and useful information. Lastly, we can prioritize vulnerabilities in their specific context based on all of these factors, plus any other external data points we can gather, to reduce irrelevant noise. Here’s what that means for us here at Snyk.
How does Snyk analyze container and Linux vulnerabilities?
The main goal of our Container Security Team is to answer the questions: Which vulnerabilities affect a container, what is the priority for fixing them, and what can I do with them?
Here’s a glimpse to how we make sure we answer this question in the most accurate, complete and timely manner:
Timely data collection
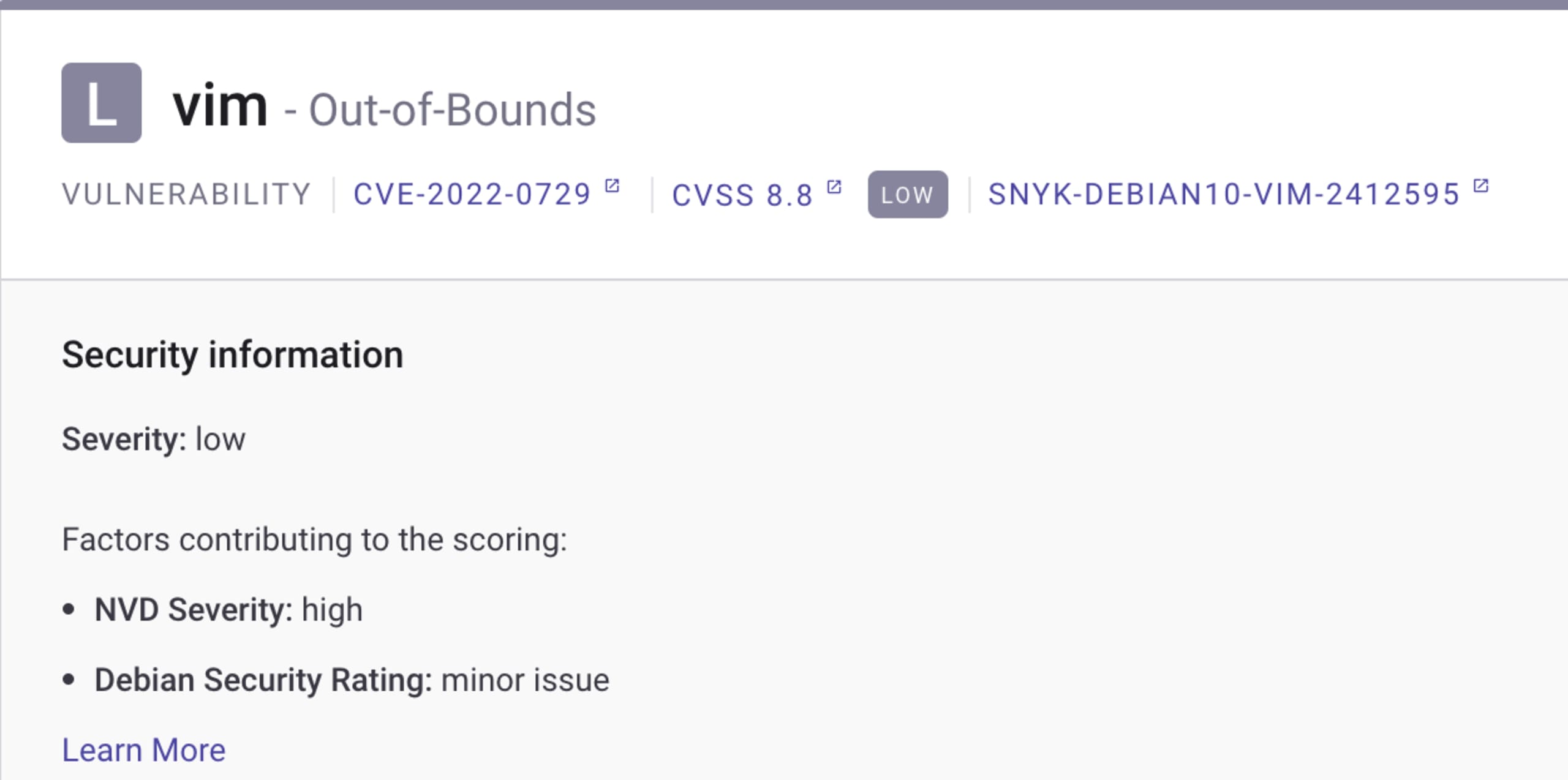
We independently collect security data from the different Linux distribution sources. This means we follow new releases and advisories, both of packages and a whole new version of the distribution, as soon as they are updated. This requires us to update our vulnerability data immediately with any new information that comes from the Linux distribution sources. One example of these kinds of updates you can see directly in our Snyk Container results is the relative importance of the vulnerability, which defines its severity in the context of the specific image. In the example below, the original CVSS score is 8.8, which is considered “high” severity, but the Debian maintainers analyzed the vulnerability in Debian 10 (the version used in this container) and determined it was a “minor issue,” resulting in the overall “low” severity rating in Snyk. This is very important data for the correct prioritization and triaging of the vulnerability, because it helps organize which of the many issues should be dealt with first.
Collaboration and in-depth understanding of the Linux distribution ecosystems
To understand each Linux distribution’s security data, we research it, understand its components, and verify its completeness. Additionally, we identify edge cases and any additional data that the specific distribution provides that we can potentially use for triage. For example, while working on improving our Red Hat security information, we noticed that their public vulnerability pages include more information on vulnerabilities than their OVAL streams did. For example, whether the vulnerability is under investigation or not affecting Red Hat’s specific product. We brought this to the attention of Red Hat’s security team, and since then they have included this important information to their OVAL streams, the official security data source we are using.
Human security expertise
In our mostly automated process that is based on the research described above, we identify and call for a security expert’s decision in specific situations. For example, when an advisory is removed by the distribution and we want to verify it before revoking. Our sophisticated revocation process is extremely important for us to make sure our automated systems don’t remove any affecting vulnerabilities, but also to avoid false positives and ease a developer’s work.
Additional enrichments and sources
We enrich our vulnerability data from external sources that we continually add. These include data from NVD, exploit information, Twitter trends, and in our latest announcement, runtime signals from Sysdig.
Contextual prioritization
From all these we prioritize the vulnerability using our unique priority score, mark it’s severity, add all additional data for more context and present the vulnerability in a way that would be most useful to triage and understand.
A glimpse into the future of Snyk container vulnerability research
We have much on our plate coming up for dealing with container vulnerabilities in the future.
One example of these are Snyk security insights. With these, we aim to reduce as much noise as possible from an already noisy environment. Giving our security insights into specific situations and conditions will provide a better way to understand if a vulnerability is not relevant in a specific configuration, environment or application, and will help us collaborate with the developer on triaging vulnerabilities.
An example for a Snyk Container vulnerability insight that we are working on is to suggest ignoring a vulnerability if it exists in a build-time package, or even more than that — fully deleting the affected build-time package (which will automatically eliminate the rest of the vulnerabilities in the same package). This is based on research of the initial assumption that there is a low possibility of exploiting a vulnerability during build-time, and vulnerabilities affecting runtime applications should be much more prioritized. You can think of this as the opposite of the Sysdig integration: where Sysdig tells you what’s running in production, which would raise the priority for fixing a vulnerability, the Snyk build-time insights might lower the priority of fixing (or even make it easy to ignore automatically) when we have a vulnerability against build tools that do not run in production.
Moreover, we are working on adding additional metadata to container vulnerabilities that will give more relevant information to make prioritization and analysis more efficient. This additional data includes, for example, information regarding the fix state in which the vulnerability is at (Will it ever be fixed at all? Is a fix already merged and waiting for release?), as well as security notes that will give more context regarding the severities or other vulnerability states. And of course, we are continually looking into and working on expanding our support for additional distributions that we don’t yet support.
Managing vulnerabilities in your containers is a complicated matter, but you don’t have to do it on your own. Snyk’s industry-leading intelligence is constantly improving and evolving, so you don’t need to be an expert to stay secure — you just need a free Snyk account.
Developer-first container security
Snyk finds and automatically fixes vulnerabilities in container images and Kubernetes workloads.