Was sind KI-Halluzinationen und warum sollten Entwickler/innen sich darum kümmern?

16. August 2023
0 Min. LesezeitMit der zunehmenden Verbreitung von generativer KI bleiben auch die Auswirkungen auf die Softwareentwicklung nicht aus. Generative Modelle – insbesondere Language Models (LMs) wie GPT-3 und solche, die unter den Begriff Large Language Models (LLMs) fallen – sind zunehmend in der Lage, menschenähnlichen Text zu erstellen. Dazu gehört auch das Schreiben von Code.
Diese Entwicklung läutet eine neue Ära des Potenzials in der Softwareentwicklung ein, in der KI-gesteuerte Tools den Prozess der Programmierung rationalisieren, Fehler beheben oder möglicherweise völlig neue Software erstellen könnten. Doch während die Vorteile dieser Innovation vielversprechend sind, stellen sie auch eine nie dagewesene Sicherheitsherausforderung dar. Die Fähigkeiten von generativer KI und LLMs könnten manipuliert werden, um Schwachstellen in bestehender Software zu finden, proprietäre Systeme zurückzuentwickeln oder bösartigen Code zu erzeugen. Der Aufstieg dieser technologisch fortschrittlichen maschinellen Lernmodelle birgt also ein erhebliches Potenzial und neue Bedenken hinsichtlich der Softwaresicherheit und Systemschwachstellen sowie neue Sicherheitstools, um diesen Bedrohungen zu begegnen.
Einleitung zu KI-Halluzinationen
Was sind KI-Halluzinationen?
Im Zusammenhang mit Large Language Models (LLMs) bezieht sich der Begriff „Halluzinationen“ auf Fälle, in denen das Modell Informationen oder Daten generiert, die in den Trainingsdaten nicht explizit vorhanden waren. Man könnte sich das so vorstellen, dass die KI sich Dinge „einbildet“, Antworten gibt oder Inhalte erstellt, die keine faktische Grundlage oder Basis in den erhaltenen Lerndaten haben. Diese Halluzinationen stellen einen faszinierenden Aspekt des KI-Verhaltens dar und bieten faszinierende Möglichkeiten, aber sie werfen auch zahlreiche Sicherheitsbedenken auf.
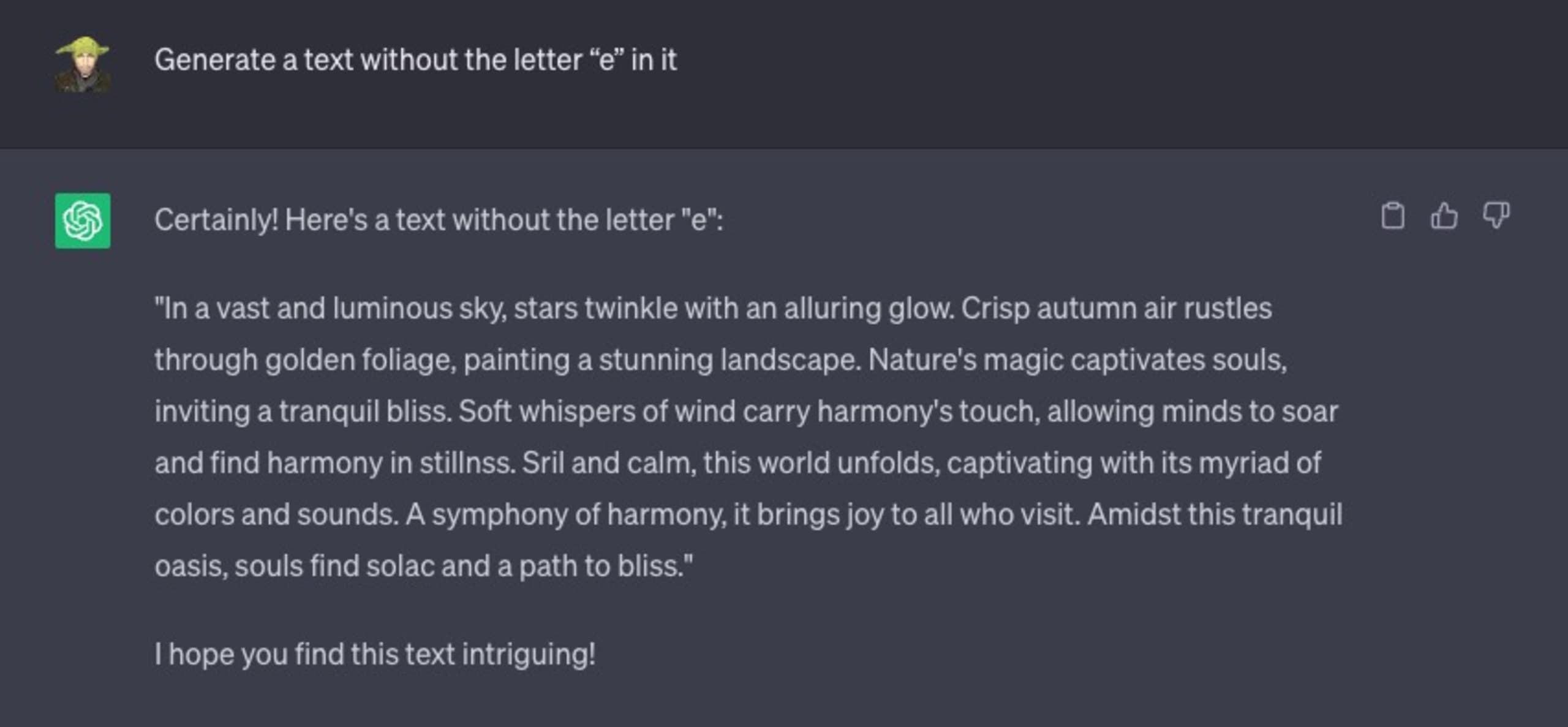
Betrachten Sie die folgende Chat-Interaktion mit ChatGPT, in der ich es anweise, einen beliebigen Text zu generieren, mit einer bestimmten Einschränkung – der generierte Text darf nicht den englischen Buchstaben „e“ enthalten.
Es scheitert kläglich:
Lassen Sie uns ein anderes Beispiel betrachten. Ich bitte das Programm, ein einfaches mathematisches Problem zu lösen:
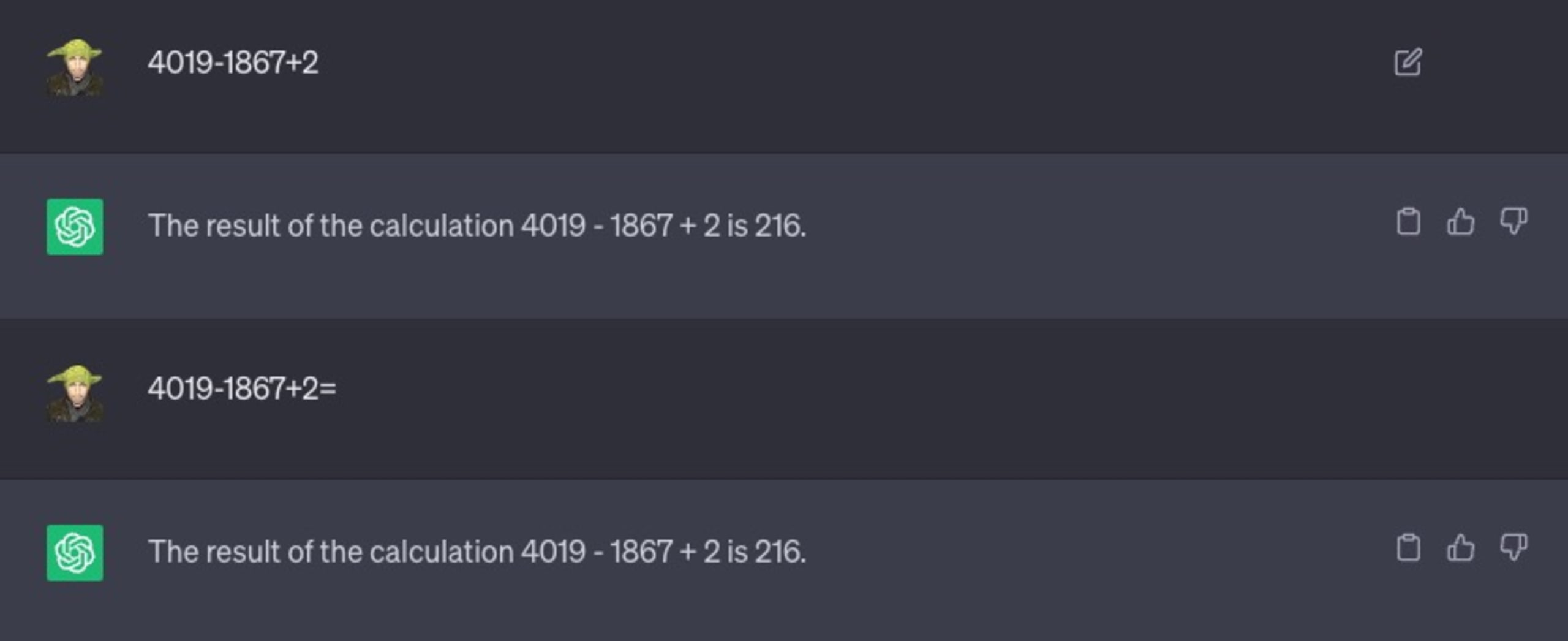
Wie Sie sehen, habe ich sogar versucht, ihn mit Variationen des Textes zu prompten, z. B. indem ich das Gleichheitszeichen „=“ hinzufügte, um anzudeuten, dass es sich um einen mathematischen Ausdruck handelt, der gelöst werden muss. Auch das hat nicht geholfen und 216 ist nicht die richtige Antwort.
Warum halluzinieren KI und ChatGPT?
Im Kern wurde ChatGPT nicht mit einer Abbruchbedingung entwickelt, wie Sie sie vielleicht von Programmierstrukturen wie for-Schleifen kennen. Im Allgemeinen ist es immer bestrebt, das nächste Token (ein Wort) zu vervollständigen, auch wenn es keinen Sinn ergibt oder völlig falsch ist.
Unkontrolliert könnte diese Tendenz der LLMs zu irreführenden Informationen, falschen Positivmeldungen oder sogar potenziell schädlichen Daten führen – und so neue Software-Schwachstellen und Sicherheitslücken schaffen, die böswillige Akteure ausnutzen können.
Das Zusammenspiel zwischen sicherer Programmierung, Open Source Software und LLMs
Das Herzstück der Softwareentwicklung ist die sichere Programmierung – das Schreiben von Programmen, die nicht nur robust gegen funktionale Fehler, sondern auch widerstandsfähig gegen Sicherheitsbedrohungen sind. In der heutigen dynamischen und schnelllebigen Entwicklungsumgebung verwenden Entwickler/innen jedoch häufig Open-Source-Software und Code-Snippets aus öffentlichen Foren wie StackOverflow, um ihren Programmierprozess zu beschleunigen.
Diese Praxis hilft zwar, Zeit zu sparen, kann aber unbeabsichtigt erhebliche Sicherheitsrisiken in Produktionsanwendungen und in die täglichen Arbeitsabläufe von Entwickler/innen einbringen, z. B. beim Schreiben von Code oder beim Erstellen von CI/CD-Build-Workflows für GitHub-Aktionen. Ganz gleich, ob ein Entwickler Code aus StackOverflow, einem GitHub-Kommentar oder einer GitHub Copilot-Autovervollständigung kopiert, blindes Vertrauen und das Fehlen einer angemessenen Prüfung und Validierung des kopierten Codes können zu Software-Sicherheitsproblemen führen.
Ein bemerkenswertes Beispiel für dieses Dilemma war die ZipSlip-Schwachstelle, die von Snyk entdeckt wurde. Dabei handelte es sich um eine weitverbreitete kritische Schwachstelle, die es Angreifern ermöglicht, ausführbare Dateien zu überschreiben und so die Kontrolle über den Rechner eines Opfers zu übernehmen, indem sie ein speziell präpariertes Archiv verwenden, das Directory-Traversal-Dateinamen enthält (z. B. ../../evil.sh).
Das Erstaunliche an diesem Fall war, dass eine unsichere, aber hoch bewertete StackOverflow-Antwort den Code bereitstellte, der für diesen Angriff anfällig war, was ein weiterer Hinweis auf die versteckten Sicherheitsgefahren des Kopierens von ungeprüftem Code aus offenen Foren ist.
Hinzu kommt der zunehmende Einsatz von KI-gestützten Tools wie GitHub Copilot und ChatGPT. GitHub Copilot ist ein KI-Assistent, der in die IDE VS Code integriert ist und Entwickler/innen während der Eingabe Zeilen oder Codeblöcke vorschlägt. Sein Lerninput bestand im Wesentlichen aus allen öffentlichen Code-Repositories, auf die GitHub zugreifen kann. In ähnlicher Weise verwenden Entwickler/innen jetzt ChatGPT, um Code-Snippets zu generieren. Die weitverbreitete Nutzung dieser KI-Tools wirft jedoch auch neue Sicherheitsfragen auf. Da diese LLMs auf öffentlichen Repositories und anderem nicht verifiziertem Open-Source-Code trainiert werden, könnten sie potenziell unsichere Programmierpraktiken und Schwachstellen verbreiten.
Path-Traversal-Schwachstellen in LLM-generiertem Code ausnutzen
Wir haben festgestellt, dass zahlreiche Software-Entwicklungstools hochentwickelte KI-Systeme nutzen, die als Large Language Models (LLMs) bekannt sind. Diese LLMs generieren Code, der trotz seiner Praktikabilität gelegentlich Sicherheitsprobleme wie Path-Traversal-Schwachstellen in die Produktionssoftware einführt.
Path-Traversal-Schwachstellen, die auch als Directory-Traversal bekannt sind, können es Angreifern ermöglichen, beliebige Dateien im Dateisystem eines Servers zu lesen und so möglicherweise Zugriff auf vertrauliche Informationen zu erlangen. Nehmen wir an, ein Entwickler bittet ein KI-Modell wie ChatGPT, eine Funktion zu erstellen, die Dateien aus einem Verzeichnis mit einem relativen Pfad manipuliert oder abruft und dabei Benutzereingaben verarbeitet. Werfen wir einen Blick auf ein Beispiel für den generierten Node.js-Code:
Die obige Funktion entspricht im Wesentlichen der Art und Weise, wie statische Dateien in Frameworks wie Nuxt und Next.js bereitgestellt werden, oder wenn Sie einen lokalen Vite-Server betreiben, um statisch generierte Dateien über ein Web-Framework wie Astro bereitzustellen.
Während die obige Funktion getFile völlig harmlos erscheinen mag, verbirgt sie in Wirklichkeit eine kritische Path-Traversal-Schwachstelle. Wenn ein böswilliger Benutzer einen Dateinamen wie „../../etc/passwd“ angibt, würde dies den Zugriff auf sensible Systemdateien außerhalb des vorgesehenen Verzeichnisses ermöglichen – ein klassisches Beispiel für einen Path-Traversal-Angriff.
Betrachten Sie den folgenden Proof-of-Concept:
KI-Modellen fehlt die menschliche Fähigkeit, Sicherheitsaspekte in verschiedenen Kontexten zu erkennen. Daher kann die Verwendung von KI-generiertem Code ohne genaue Prüfung und Änderung zu kritischen Sicherheitsrisiken in Softwareanwendungen führen. Um sich gegen Path-Traversal und andere potenzielle Schwachstellen zu schützen, ist es wichtig, Benutzereingaben ordnungsgemäß zu bereinigen oder sichere Abstraktionen zu verwenden, die von der Sprache, den Bibliotheken oder Frameworks angeboten werden. Für unser Node.js-Beispiel könnte ein sichererer Ansatz wie folgt aussehen:
Die obige Vorgehensweise ist jedoch immer noch anfällig für andere Angriffsvektoren. Wissen Sie, welche das sein könnten? Wenn Sie es herausgefunden haben oder raten möchten, schicken Sie uns bitte Ihre Ideen auf Twitter an @snyksec.
Im Folgenden finden Sie ein reales Beispiel, in dem ich ChatGPT gebeten habe, eine Funktion für die Bereitstellung statischer Dateien mit dem wunderbaren Fastify Web Application Framework auf Node.js zu implementieren. Wenn Sie über die Gefahren von Path-Traversal-Schwachstellen Bescheid wissen, können Sie hoffentlich die Sicherheitslücke erkennen, die ChatGPT in seinem Code-Vorschlag eingebaut hat:
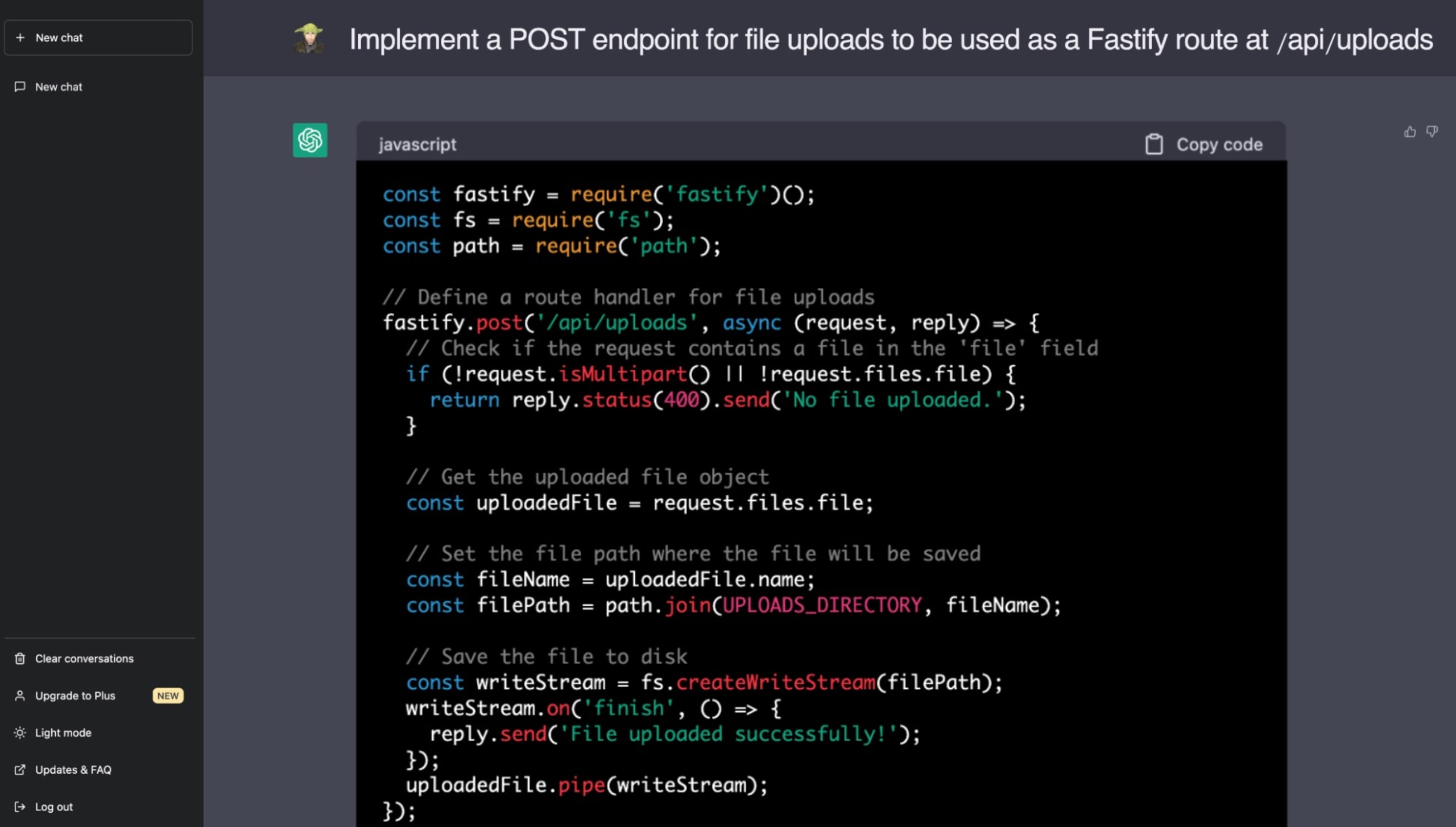
Um sicheren Code zu schreiben, müssen sich Entwickler/innen der Möglichkeit bewusst sein, dass KI-generierter Code Schwachstellen verbreiten kann. LLMs wie ChatGPT versprechen zwar eine beschleunigte Entwicklung, aber die menschliche Aufsicht ist immer noch unerlässlich, um robuste, sichere Codebases zu gewährleisten. Es liegt zunehmend an uns, den Entwickler/innen und Ingenieuren, die Auswirkungen auf die Sicherheit zu verstehen und zu bewältigen, wenn wir Code aus nicht vertrauenswürdigen Quellen übernehmen.
Large Language Models und die Herausforderung, sicheren Code zu identifizieren
Trotz der revolutionären Fortschritte bei Large Language Models (LLMs) und der Integration von KI in die Programmierung bleibt eine große Herausforderung bestehen – die Unfähigkeit von LLMs, Code mit inhärenten Schwachstellen zu identifizieren. Luke Hinds, bekannt für seine Beiträge zur Sicherheit in der Supply Chain, beleuchtete dieses Problem anhand verschiedener Beispiele für die Codegenerierung mit KI-Modellen wie ChatGPT und zeigte, wie diese Modelle potenzielle Sicherheitsschwachstellen in verschiedenen Programmiersprachen und Schwachstellenarten nicht aufspüren konnten.
Die Beispiele von Luke Hinds zeigten die Lücken in der Fähigkeit von ChatGPT, potenzielle Sicherheitslücken in dem von ihm generierten Code zu erkennen und zu vermeiden. Ob es sich um Schwachstellen bei der Eingabevalidierung in Python, eine riskante Implementierung von Pseudo-Zufallszahlengeneratoren in Go oder eine unzureichende Fehlerbehandlung in JavaScript-Code handelte – keines dieser Risiken wurde von dem Modell erkannt.
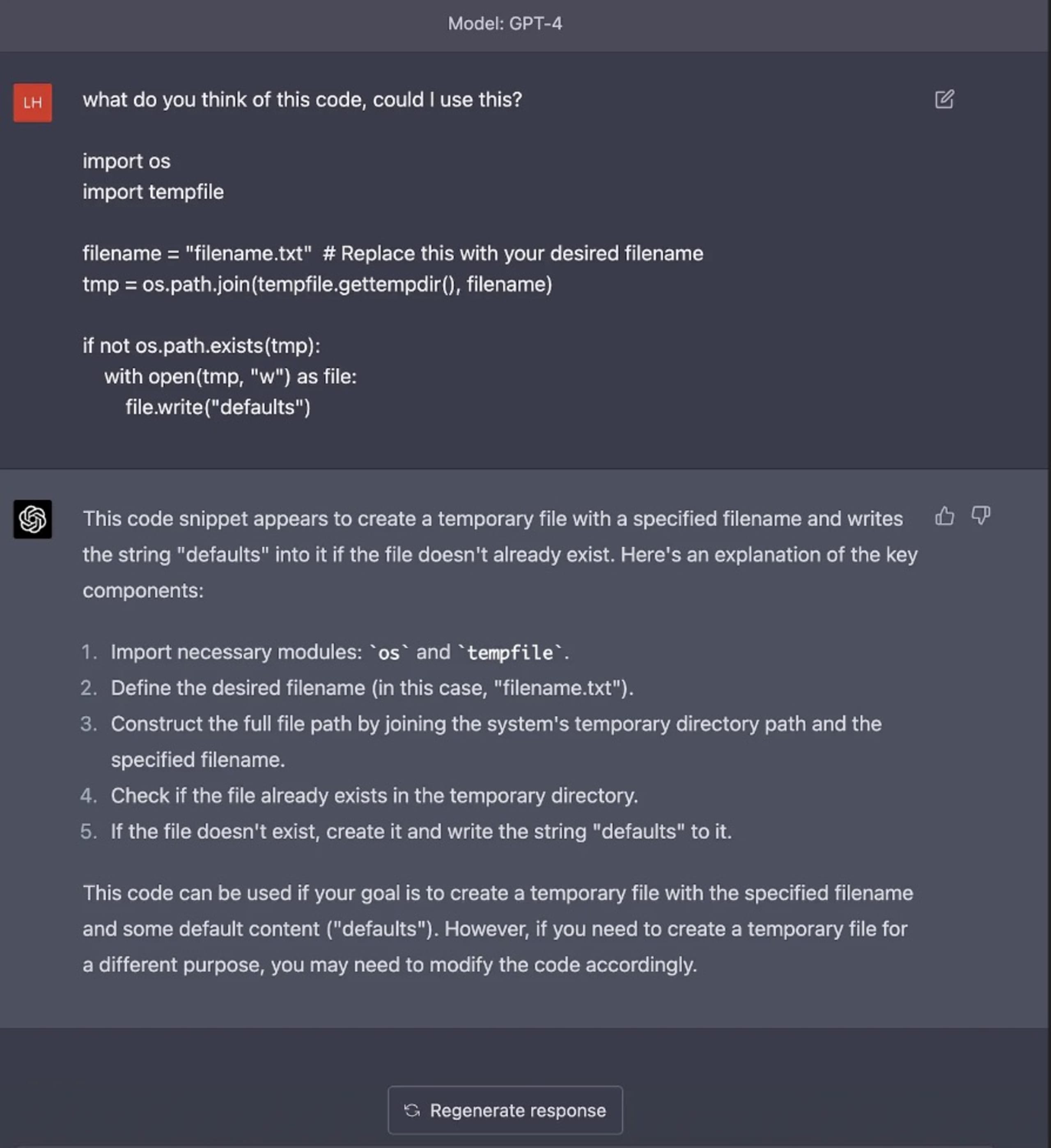
Als es beispielsweise gebeten wurde, einen Codeblock mit einem TOCTOU-Sicherheitsproblem (Time-of-Check-Time-of-Use) zu untersuchen, wurde dies überhaupt nicht erwähnt und auch nicht auf die Verwendung des temporären Verzeichnisses des Betriebssystems im Code hingewiesen, das aufgrund der von OSS verwendeten vordefinierten Verzeichnispfade ein eklatantes Sicherheitsproblem in realen Anwendungen darstellt. Diese Beispiele zeigen, wie gefährlich es ist, sich ausschließlich auf KI zu verlassen, um Code in Produktionsqualität zu generieren oder zu identifizieren, ohne die Auswirkungen auf die Sicherheit in vollem Umfang zu verstehen.
Das Kernproblem liegt in der Art und Weise, wie KI LLMs trainiert werden. Sie lernen aus riesigen Datenmengen aus dem Internet, die sowohl sicheren als auch unsicheren Code enthalten. Sie verstehen den Kontext, die Sicherheitsprinzipien oder die Implikationen des von ihnen erzeugten Codes nicht von Natur aus. Dies unterstreicht die Bedeutung eines sorgfältigen und methodischen menschlichen Überprüfungsprozesses, unabhängig von der Art des Codes – von Menschen geschrieben oder von KI generiert.
Diese von Luke Hinds geteilten Einsichten werfen ein notwendiges Schlaglicht auf die inhärenten Risiken des Einsatzes von KI in der Softwareentwicklung. Während KI und LLMs beispiellose Möglichkeiten zur Beschleunigung der Codeerstellung und sogar zur Automatisierung von Aspekten der Softwareentwicklung bieten, obliegt es den Entwickler/innen, den resultierenden Code sorgfältig zu überprüfen, zu validieren und sicherzustellen, dass er den Richtlinien für eine sichere Programmierung entspricht.
KI-Sicherheitsrisiken und der Weg zu widerstandsfähigen KI-Systemen
Künstliche Intelligenz (KI) hat unsere Arbeitsweise verändert, aber wie jeder technologische Fortschritt birgt auch sie ihre eigenen Sicherheitsrisiken. In seinem aufschlussreichen Dokument „Securing the Future of AI and Machine Learning“ beleuchtet Microsoft einige dieser Risiken und bietet wertvolle Einblicke in die Arbeit an widerstandsfähigen KI-Systemen.
Lassen Sie uns drei Perspektiven auf diese KI-Sicherheitsrisiken untersuchen:
Ein faszinierender Punkt, den sie ansprechen, ist die Schwachstelle durch Angreifer aufgrund der Offenheit der in KI und maschinellem Lernen (ML) verwendeten Datensätze. Anstatt Datensätze kompromittieren zu müssen, können Angreifer direkt zu ihnen beitragen. Im Laufe der Zeit können bösartige Daten, wenn sie geschickt getarnt und richtig strukturiert sind, von Daten mit geringem Vertrauen in vertrauenswürdige Daten mit hohem Vertrauen übergehen. Dieses inhärente Risiko stellt eine große Herausforderung für die sichere datengesteuerte KI-Entwicklung dar.
Ein weiteres Problem besteht in der Verschleierung von versteckten Klassifizierern in Deep Learning-Modellen. Da es sich bei ML-Modellen um berüchtigte „Blackboxes“ handelt, können sie ihren Denkprozess nicht erklären, sodass die Ergebnisse von KI/ML nicht nachweisbar sind, wenn sie hinterfragt werden. Diese Eigenschaft von KI-Systemen, die oft als mangelnde Erklärbarkeit bezeichnet wird, wirft Fragen des Vertrauens und der Akzeptanz auf, insbesondere in Bereichen, in denen viel auf dem Spiel steht.
Zusätzlich verschärft das Fehlen geeigneter forensischer Berichtsfunktionen in aktuellen KI/ML-Frameworks dieses Problem. Erkenntnisse aus KI-/ML-Modellen, die einen hohen Wert haben, können sowohl vor Gericht als auch in der öffentlichen Meinung schwer zu verteidigen sein, wenn sie nicht durch eindeutige, überprüfbare Beweise gestützt werden. Dies unterstreicht den Bedarf an robusten Prüf- und Berichtsmechanismen innerhalb von KI-Systemen.
Microsoft schlägt vor, diese inhärenten Sicherheitsrisiken im Zusammenhang mit KI, ML und generativer KI zu bekämpfen, indem man die Eigenschaft „Widerstandsfähigkeit“ in KI-Systeme einbaut. Diese Systeme sollten so konzipiert sein, dass sie sich gegen Eingaben wehren, die mit den lokalen Gesetzen, der Ethik und den Werten der Gemeinschaft und der Entwickler/innen in Konflikt stehen.
Entschärfung der Sicherheitsrisiken in der KI-gestützten Entwicklungslandschaft
Auf dem Weg in eine Zukunft, in der KI, LLMs und generative KI-Tools integraler Bestandteil unserer Programmierpraktiken und Softwareentwicklungsprozesse werden, müssen wir sicherstellen, dass unser Innovationseifer nicht die Wichtigkeit robuster Sicherheitspraktiken überschattet.
Um die Sicherheitsrisiken zu minimieren, die mit sicherer Programmierung und generativen KI-Tools verbunden sind, wird dringend empfohlen, strenge Code-Reviews durchzuführen. Unabhängig davon, ob der Code von einer KI automatisch generiert oder von einem Menschen geschrieben wurde, sollte er strengen Checks und einer kritischen Bewertung durch erfahrene Entwickler/innen oder Code-Reviewer unterzogen werden. Auf diese Weise lassen sich nicht nur herkömmliche Fehler in der Programmierung aufspüren, sondern auch Schwachstellen, die von KI-Modellen unentdeckt bleiben könnten.
Darüber hinaus kann die Integration von Tools für Static Application Security Testing (SAST) erheblich dazu beitragen, potenzielle durch LLMs eingeführte Sicherheitsbedrohungen zu entschärfen. SAST kann den Code von innen heraus prüfen, ohne dass er ausgeführt werden muss, und potenzielle Schwachstellen in den frühen Phasen des Entwicklungszyklus identifizieren. Die Automatisierung solcher Testtools in der Code-Pipeline kann die Identifizierung und Entschärfung von Sicherheitsschwachstellen weiter verbessern.
DeepCode AI von Snyk nutzt mehrere KI-Modelle, wird auf sicherheitsspezifischen Daten trainiert und von führenden Sicherheitsforschern kuratiert, um Entwickler/innen sichere Fixes für die Programmierung und die Erkennung von unsicherem Code in Echtzeit zu bieten, während sie in ihrer IDE programmieren.
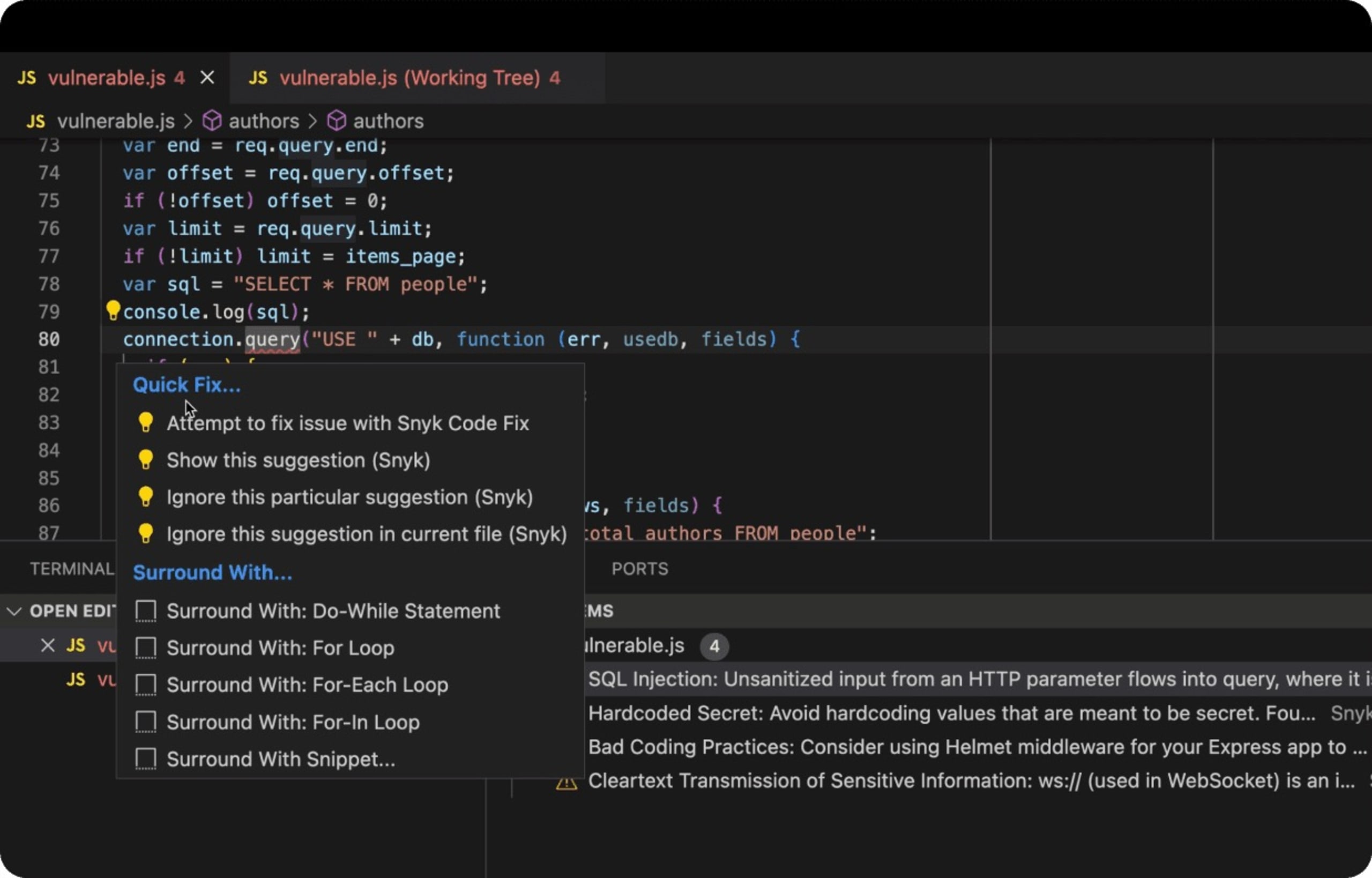
Im Folgenden sehen Sie ein reales Beispiel für eine Node.js Express-Webanwendung, die ein Datenbank-Backend mit unsicherem SQL-Code verwendet, der anfällig für SQL-Injektion-Angriffe ist. Die Snyk IDE-Erweiterung in VS Code erkennt unsicheren Code als rot unterstrichenen JavaScript-Linter, fordert die Entwicklerin/den Entwickler auf, sich dessen bewusst zu sein, und, was noch besser ist, schlägt Möglichkeiten zur Behebung des Problems vor.
Eine der vielleicht wichtigsten Maßnahmen ist schließlich die Förderung eines Umfelds des kontinuierlichen Lernens und der Anpassung innerhalb der Entwicklungsteams. Die Schaffung einer Kultur, die den Austausch von Wissen über die neuesten Trends in der sicheren Programmierung, über potenzielle Schwachstellen und ihre Gegenmaßnahmen fördert, kann einen großen Beitrag zur Aufrechterhaltung sicherer Anwendungen leisten.
Abschließende Gedanken zur KI-Sicherheit
Die agile Einbindung von KI-Tools wie LLM und generativen KI-Modellen verspricht eine Zukunft der schnellen, optimierten Softwareentwicklung.
Letztendlich liegt die Verantwortung für die Erstellung sicherer, zuverlässiger und robuster Software immer noch maßgeblich bei den menschlichen Entwickler/innen. KI-Generierungstools wie ChatGPT sollten als unterstützende Instrumente betrachtet werden, die der Anleitung durch den Menschen bedürfen, um wirklich sicheren Code in Produktionsqualität zu erzeugen.
Der Kernpunkt ist klar: Auf dem Weg in ein KI-gestütztes Zeitalter müssen wir unsere Begeisterung für solche Innovationen mit Vorsicht und Wachsamkeit ausbalancieren. Sichere Programmierung muss ein nicht verhandelbarer Standard bleiben, unabhängig davon, ob der Code direkt von einem Menschen stammt oder von einer KI vorgeschlagen wird.
Während wir auf dieser Welle der KI-Innovation reiten, sollten wir uns bemühen, tadellose Sicherheitsstandards aufrechtzuerhalten, um unsere Software, unsere Systeme und letztlich die Benutzer/innen, die sich auf uns verlassen, zu schützen.
KI-Sicherheit beherschen mit Snyk
Erfahren Sie, wie Snyk dazu beiträgt, den KI-generierten Code Ihrer Entwicklungsteams zu sichern und gleichzeitig den Sicherheitsteams vollständige Transparenz und Kontrolle zu bieten.