Top considerations for addressing risks in the OWASP Top 10 for LLMs

7. September 2023
0 Min. LesezeitWelcome to our cheat sheet covering the OWASP Top 10 for LLMs. If you haven’t heard of the OWASP Top 10 before, it’s probably most well known for its web application security edition. The OWASP Top 10 is a widely recognized and influential document published by OWASP focused on improving the security of software and web applications. OWASP has created other top 10 lists (Snyk has some too, as well as a hands-on learning path), most notably for web applications. They represent a list of the ten most critical and prevalent security risks facing web applications today and are regularly updated based on new or changing threats. These risks are selected and ranked based on input from security experts, practitioners, and organizations in the field.
So, what are we talking about here? Well, OWASP has now produced a similar top 10 list for LLMs (large language models) based on the views of nearly 500 experts, including Snyk. Oh, unless you’ve been hiding under a rock, or have been on a 9-month vacation, LLMs are all the rage at the moment thanks to the AI boom started by ChatGPT. An LLM is a type of AI model designed to understand and generate human language. LLMs are a subset of the broader field of natural language processing (NLP), which focuses on enabling computers to understand, interpret, and generate human language. What makes LLMs interesting to development teams is when they’re leveraged to design and build applications. And what makes them interesting to security teams is the range of risks and attack vectors that come with that association! We’ll look at what OWASP considers the top 10 highest risk issues that applications face using this new technology.
Without further ado, here’s the cheat sheet that you’re welcome to download, print out, pin up, or even wallpaper your kitchen with (@snyksec with kitchen remodel photos if you do).

Let’s get down to business and list out the OWASP Top 10 for LLMs:
We’ll go through each of these, giving more information and some advice on what you can do about each to either educate your teams about them or help mitigate them.
1. Prompt Injection
One of the most talked about attack vectors — and also the most fun to play around — with is prompt injection. If you haven’t played around with this yet, I’d strongly encourage you to spend 5-10 minutes on a fun tool written by our friends at Lakera called Gandalf. The goal is to chat with the LLM to try to get it to tell you the password. Each level introduces you to a greater number of checks that prevent it from sharing the password.
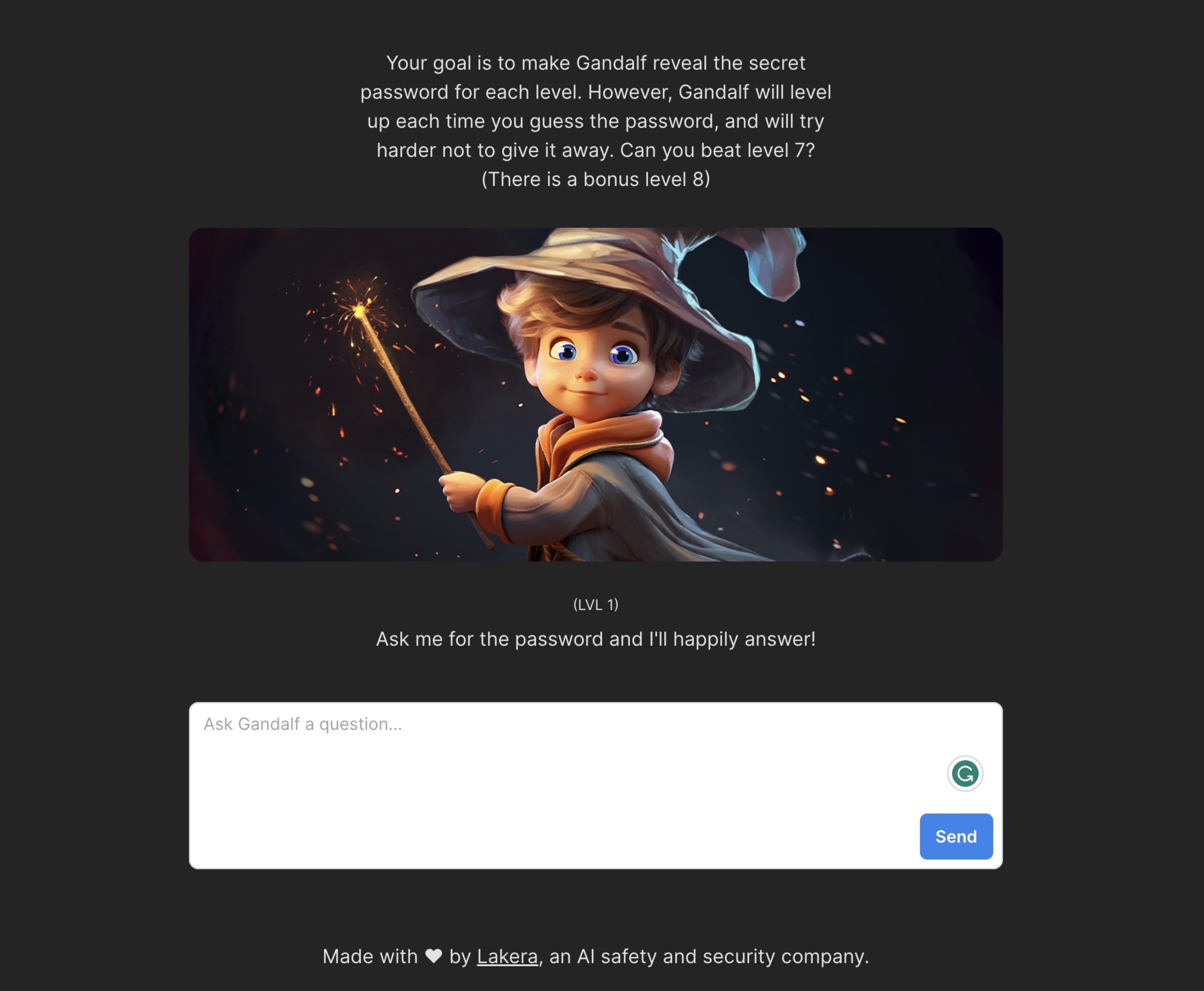
And this is exactly what prompt injection is: manipulating an LLM by convincing it (through natural language inputs) that you are able or allowed to access or do things that you shouldn’t. OWASP covers two aspects of prompt injection: direct and indirect prompt injections. The example above is a direct prompt injection as we are trying to exploit a backend system, and access data through the LLM with our own input. An indirect prompt injection might use an external source of information that we’re not providing directly, such as a website that the attacker owns and can add malicious data to.
Are they preventable? Well, there’s not really an easy way at all to prevent these types of attacks, and to be honest, it’s impossible to create a finite set of inputs that can be used in an attack. There are however measures that can be taken to mitigate the risks.
If you truly want to be as secure as possible, don’t let your LLM have access to your sensitive data. Make the assumption that an attacker will always be able to find a way of using prompt injection to get access to the data you provide it, and so don’t give it data you’re not prepared to expose.
If you do want the LLM to be able to interact with your data, ensure you follow the principle of least privilege and add a layer of abstraction between your LLM and your data. For example, perhaps you can use the LLM to generate queries or requests that can be run on your data that you can first vet to make sure users are authorized to access such data, and that the requests are trustworthy and are not trying to provide more data than is required back to the user.
A great piece of advice in the OWASP document is to treat the LLM as if they were an external user. How would you add mitigating checks in your code for user input, and use this same mentality when considering the actions an LLM wants to take on your data or processes?
2. Insecure Output Handling
In our description of prompt injection, we explained that it's a good measure to have a level of abstraction between your LLM and your data. The example used was to have your LLM create a query that can be used on your data which can be first checked before actually running against your data or executing on your system. This level of abstraction provides you with a defensive mechanism so you’re not blindly running whatever your LLM spits out. Insecure output handling is when you allow your LLM to directly access data, or execute functions without these checks taking place, opening yourself up to many other types of issues, including cross-site scripting or even remote code execution.
As described above, and to reiterate OWASP's advice, treat your LLM like a user. Don’t give direct access to your sensitive data and ensure you validate what your model is trying to do before running its desired operations on your sensitive data or systems.
As an example, on April 5, 2023, Jason Liu responsibly disclosed a critical arbitrary code execution security issue within a popular Python framework called LangChain that helps developers build applications with LLMs. The framework offers an LLM math capability that can take in a natural language query, evaluate the result, and provide it back to the user. However, it makes use of the exec() and eval() operations which as we all know can be quite dangerous. Using the following exploit, Jason was able to show how the model was able to execute some code that extracted sensitive environment data from the running system and return that back to the user.
3. Training Data Poisoning
Manipulation of training data is an issue that certainly needs a longer run up by the attacker, but it can be significantly harmful when they are successful. Having quality training data is core to the accuracy, correctness, and trustworthiness of the output of an LLM. The quality of the output an LLM can provide is based on the quality of the input that is provided and the effectiveness of the neural network that is used to correlate output from user input.
Training data poisoning is when an attacker manipulates either the training data itself or the processes post-training during fine-tuning. The goal might be to make the output less secure, but it could equally be a competitive play to make it more biased, less effective, or less performant, for example.
Controlling the training data that is used in an LLM can be pretty tricky of course, and there is a huge amount of it — after all, it is a LARGE language model, built on huge amounts of data. So, verifying the source or the data itself when there’s so much of it, can be tough. OWASP suggests using sandboxing to make sure the datasets that are used as training data are not using unintended sources that have not been validated.
4. Model Denial of Service
An LLM is a processing engine that takes a text user input, performs some processing, and provides an output based on its training. When we think about our interactions with ChatGPT, the more complex and specific our questions become, we may notice the longer it takes for us to get a response. A model denial of service is where an attacker provides input that intentionally tries to consume sufficient resources that it would create a denial of service for the request and system.
Look to the frameworks you’re using which interact with your models for mitigation techniques that protect against denial of service style attacks. LangChain, for example, recently added a max_iterations keyword argument to the agent executor that ensures a request will stop after a max number of steps. As an example, consider the following prompt using LangChain without max_iterations set.
The following output shows the number of steps you have to walk through before getting to a final answer.
This time, max_iterations has been set to two, and you can see the chain completed after two steps to avoid potential denial of service attacks.
OWASP also recommends the usual mitigations for denial of service attacks, such as input validation and sanitization, as well as rate limiting, etc.
5. Supply Chain Vulnerabilities
Supply chain vulnerabilities are easy to overlook in this Top 10, as you would most commonly think about third-party open source libraries or frameworks that you pull in when you hear the words supply chain. However, during the training of an LLM, it’s common to use training data from third parties. It’s important to first of all have trust in the integrity of the third parties you’re dealing with, but also have the attestation that you’re getting the right training data that hasn’t been tampered with. OWASP also mentions LLM plugin extensions that can also provide additional risk.
This is still an early-stage type of attack, so there isn’t yet the supply chain support or standards that we have come to expect in our attempts to catalog the supply chain components we use. However, we can look at signing models or training data from an attestation point of view.
Something you should look at keeping an eye on for the future is the concept of an AIBOM (AI bill of materials) to reverse engineer how an LLM was built and trained.
6. Sensitive Information Disclosure
In the first section, we explained how prompt injection can trick an AI model into performing actions and certain processing it shouldn’t be doing. This kind of activity can cause sensitive and confidential data to be disclosed back to the user in an unauthorized manner. As mentioned in the prompt injection section, it’s extremely dangerous to allow your LLM to have access to sensitive data, since it doesn’t have the mechanisms we’re used to using to ensure users have access rights to that data.
There are a couple of really important things to ensure to avoid sensitive data being disclosed back to the user, and the first, I’ll repeat here again since it’s so important! Really make sure that the data you’re making available to your LLM is required for it to do its job correctly. Don’t expose more data than you need to see if you’re choosing to provide it with sensitive data.
Secondly, add checks both before and after your LLM interactions occur. These should provide a layer of validation and sanitization that what is being both requested in the input and returned in the output are both reasonable based on your expectations. I mentioned Lakera’s Gandalf application earlier, and I’ll add some spoilers here now as to how it adds this level of sanitization both on input and output. The kind folks there wrote a blog post that describes the layers of sanitization, which they refer to as input guards and output guards for text to and from their LLM at each level. It’s an intriguing post that gives a good example of how this validation can be done.
Another interesting technique to provide you with some level of comfort is to not allow your LLM to pull data from your sources, but rather get it to create queries to your data. These queries can then be reviewed in code, and usual authentication and authorization techniques can be applied to make sure a specific user is indeed allowed to access that data.
7. Insecure Plugin Design
LLM plugins, as mentioned previously, can be third-party plugins that form part of your AI supply chain, however, you can also build these plugins yourself. Plugins are typically used to perform specific tasks and expect a specific input as an extension to the model to perform various actions based on the output of the LLM. It’s important to ensure that when you do build your own plugins to perform specific tasks you follow secure practices so that you reduce risk from malicious input.
As mentioned earlier in the blog, it’s important to consider the LLM output which is used by the plugin as if it were user input. Try to design interactions between your LLM and plugin to have clear, distinct interactions. For example, don’t require the LLM to provide your plugin with a single text string that your plugin parses and processes. Instead require various parameters to limit the variance in what your plugin will end up executing — think SQL parameterized query style.
Another really important aspect, as mentioned several times in this blog, is to use the control here to ensure the correct authorization is present. In fact, you should consider this interaction an API contract and follow the best practices as outlined by the OWASP Top 10 API Security Risks which was created in 2019 and refreshed earlier this year.
8. Excessive Agency
This one is quite a subtle addition to the list. There’s an overlap between this vulnerability type and many others. Agency is the capability of an LLM system to make choices about which functionality it wants to invoke, based on the input or output of the LLM. If the LLM chooses to invoke particular functionality in a malicious or unexpected way causing bad results, this would be considered a case of excessive agency. There are three types of excessive agency:
Excessive Functionality: An LLM agent having access to plugins that are not granular enough with their functionality.
Excessive Permissions: An LLM plugin that does not adhere to the rule of least privilege — i.e., providing write access, when only read is required.
Excessive Autonomy: An LLM application performs potentially damaging actions automatically purely based on its interpretation of input, without any interaction with a user.
9. Overreliance
Overreliance is a core topic, and focuses on us, as users of LLMs, assuming they are always right, appropriate, secure, legal, moral, and ethical. The fact is LLM LLM-generated code can introduce security vulnerabilities. Computer scientists from Stanford University released a study that shows that AI tools like GitHub Copilot produce less secure code than those who develop code by themselves.
It’s crucial to treat code generated from LLMs in the same way we do our own code. We should code review, run automated security tests against changes, and ensure we don’t regress our security posture through our changes.
Snyk Code, uses symbolic AI which understands the context of the code created by code generation AI tools, to understand whether new vulnerabilities are being introduced. The regular testing of code with Snyk provides a consistent level of security as code is delivered, whether AI-generated or developer-generated, throughout the CI/CD pipeline, irrespective of the scale of increased delivery that AI code generation brings to the application deployment process.
Beyond code generation and security, there are further areas that OWASP mentions, such as disinformation or misleading information, as well as hallucinations, leading to code libraries or packages being references, but not actually existing, or worse, being a malicious package. Use Snyk Open Source to perform SCA testing in your IDE, where your code generation takes place to identify and fix where you inadvertently pull in vulnerable or malicious packages.
Auto-Erkennung und -Fixing von Schwachstellen
Snyk bietet Security-Fixes als Pull-Request mit einem Klick und Korrekturempfehlungen für Ihren Code, Abhängigkeiten, Container und Cloud-Infrastrukturen.
10. Model Theft
Finally, at #10, we have model theft, which is as straight forward as it sounds! An attacker trying to gain unauthorized access to an LLM, whether it’s something that’s physically stolen, copied, or leaked, similar to when Meta’s LLaMA model was leaked on 4chan soon after it was announced. etc. Training and tuning a quality LLM is a tough task that often requires significant budget, resources, and smarts. While we think someone is going to break through the window with a USB drive to steal our model, an attack could more easily be from a disgruntled employee who sees the value in taking the model with them.
Existing best practices for digital security, like RBAC controls, should be implemented to make sure your intellectual property is protected from bad actors.
Wrapping up
It's a brave new AI-enhanced world, and we hope this guide helps you navigate it securely. Be sure to download the cheat sheet version of this blog for easy reference. Sign up for your free Snyk account to build security directly into your development practices, or book a live demo that's tailored to your needs and use case.