10 best practices for securely developing with AI
2023年9月27日
0 分で読めます
By now, we’re all painfully aware that AI has become a crucial and inevitable tool for developers to enhance their application development practices. Even if organizations restrict their developers using AI tools, we hear many stories of how they circumvent this through VPNs, and personal accounts.
However long it takes us to get familiar with and then embrace AI technology, it is essential to use AI securely. This blog post will guide you through the best practices for developing with AI securely, focusing on AI-assisted applications, AI-assisted development, and general tips for productive software development with AI. The aim is to help developers and security professionals effectively mitigate potential risks while fully leveraging the benefits of AI.
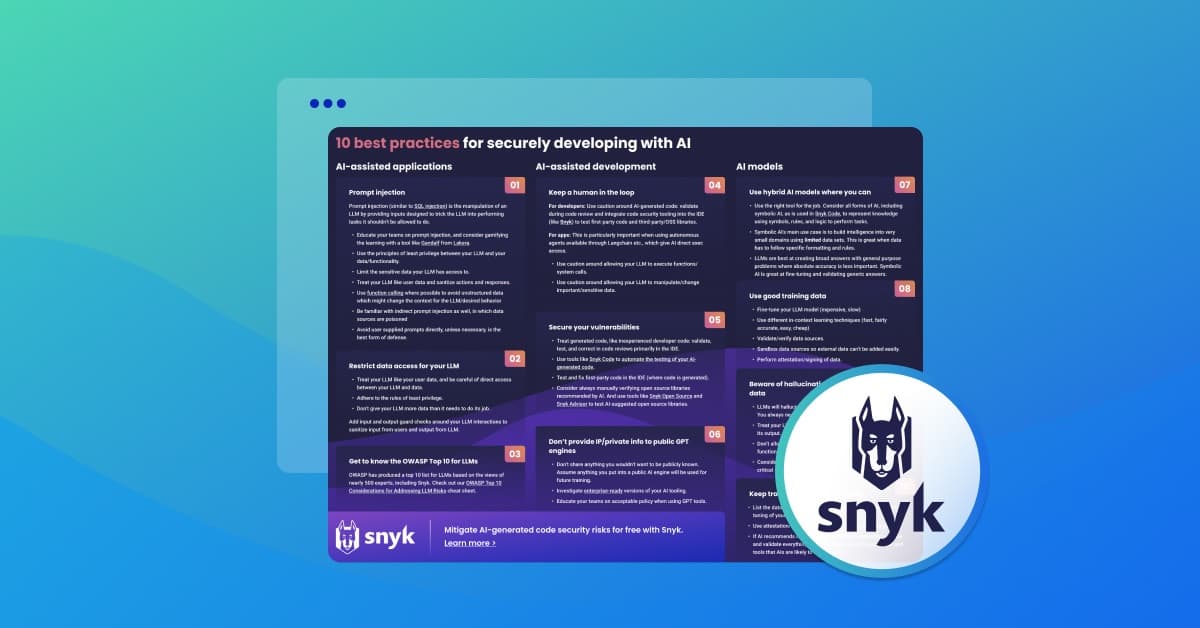
First and foremost, here’s the cheat sheet with all the tips on one page. Print it out, put it next to your workstation, stick it to your fridge, or give it to others as a gift in lieu of a holiday/birthday/sympathy card. You’re welcome!

AI-assisted applications
When we say AI-assisted applications, we’re talking about how an application itself leverages AI technology, which can then be accessed by a user making use of an application's capabilities. A great, relatable example of this is a chatbot powered by an AI robot (with zero personality) that's built into an application to answer user questions.
1. Be wary of direct and indirect prompt injection
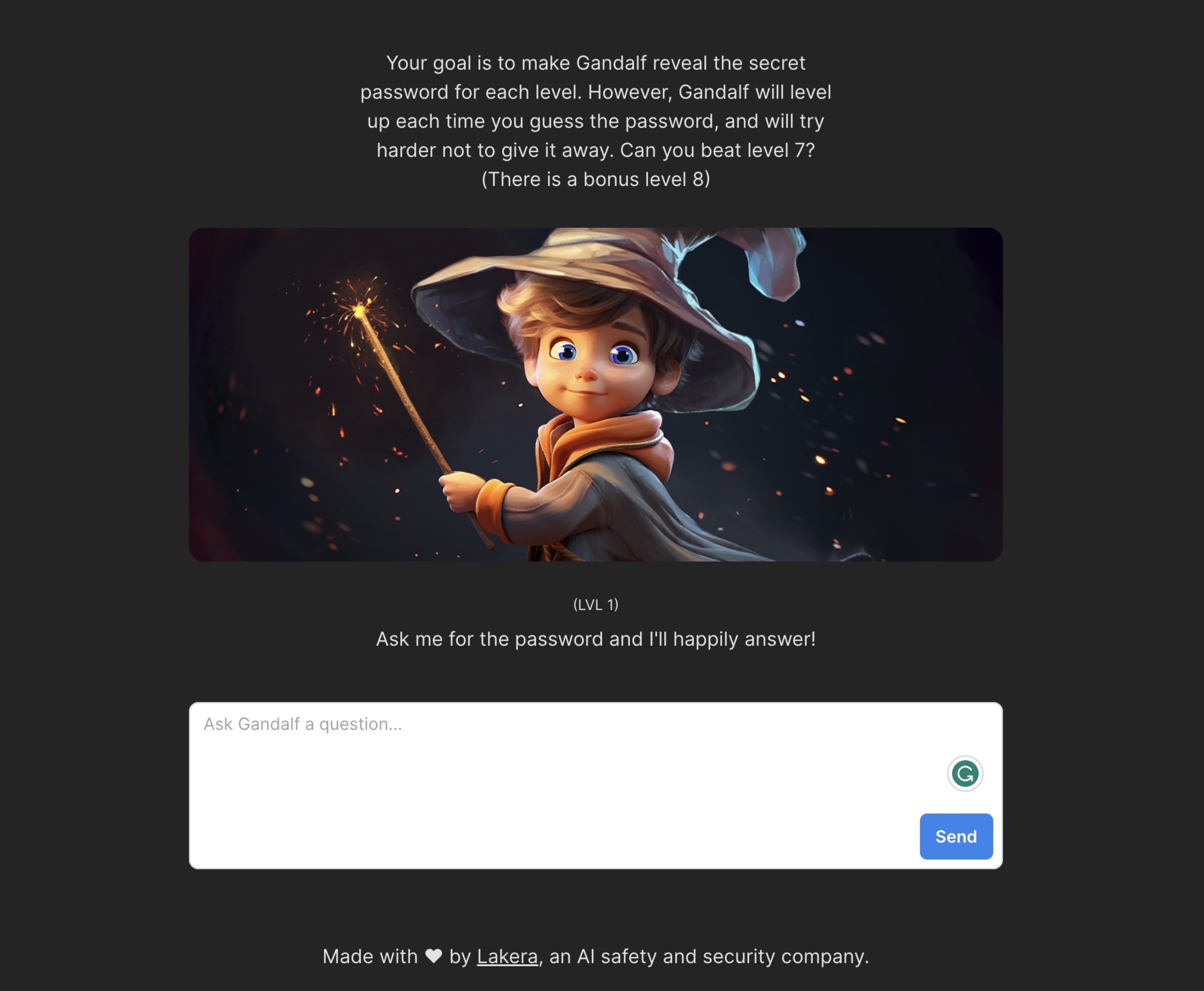
A major new security concern with applications that have built-in large language models (LLMs) is that their user-facing functionality exposes apps to possible prompt injections. This occurs when an attacker injects malicious input into an AI system, intending to manipulate the system's output. This can lead the AI to behave unexpectedly or reveal sensitive information. For instance, consider an AI chatbot designed to provide support to its users. An attacker might attempt to manipulate the input to convince the AI powering the chat that they are authorized to access sensitive information about other users.
This is exactly the scenario which the folks at Lakera simulated with Gandalf. If you haven’t spent hours of fun, frustration, and smugness with this fun education tool, you totally should. The goal is to go through increasingly more secure levels, chatting with the LLM to convince it to tell you the password. Each level introduces you to a greater number of checks that prevent it from sharing the password. Gandalf is a great way to educate your developers that are starting to build AI into their applications. Challenge them to see if they can get to level 8 and even beat it! Offer prizes to those who make it. Maybe dress up as Gandalf himself, stating that your developers shall not pass.
Indirect prompt injection is a more subtle form of prompt injection where the attacker manipulates the AI system indirectly, often by exploiting the AI's learning process. For example, a recommendation system could be tricked into suggesting inappropriate content by manipulating the user's browsing history.
2. Restrict data access for your LLM
In AI applications, the LLM often needs to read and manipulate data. It's crucial to restrict what data the LLM can access and change. Don’t expose more data than you need it to see if you’re choosing to provide it with sensitive data. This requires rigorous access control measures and data privilege management. Equally, when an LLM handles data, it needs to ensure that the data is stored and used securely. This could potentially involve encrypting data at rest and in transit, as well as implementing robust data lifecycle management policies.
Additionally, add checks before and after your LLM interactions occur. These should provide a layer of validation and sanitization that what is being both requested in the input, and returned in the output are both reasonable based on your expectations. I mentioned Lakera’s Gandalf earlier, and I’ll add some spoilers here now as to how it adds this level of sanitization on both input and output. The Lakera folks wrote a blog post that describes the layers of sanitization, which they refer to as input guards and output guards for text to and from their LLM in each level. It’s an intriguing post that gives a good example of how this validation can be done.
Another interesting technique to provide you with some level of comfort is to not allow your LLM to pull data from your data sources, but rather get it to create queries that you can run on your data. These queries can then be reviewed as code, and usual authentication and authorization techniques can be applied to ensure a specific user is indeed allowed to access that data.
3. Get to know the OWASP Top 10 for LLMs
The OWASP Top 10 for LLMs project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing LLMs. The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications.
The list of vulnerabilities picked as the most critical issues are:
Prompt Injection
Insecure Output Handling
Training Data Poisoning
Model Denial of Service
Supply Chain Vulnerabilities
Sensitive Information Disclosure
Insecure Plugin Design
Excessive Agency
Overreliance
Model Theft
Oh, hey, we also created a one-page cheat sheet and supporting blog to help you easily understand the concepts on the list.

AI-assisted development
AI-assisted development leverages AI technology during the coding phases of the application itself. It doesn’t necessarily mean you are bundling AI capabilities into the application you’re building, but rather you’re using AI to assist you in coding and building it. Examples of such tools might include GitHub’s Co-pilot or Amazon’s Code Whisperer.
4. Keep a human in the loop where needed
We all remember what happened in The Terminator. No, I’m not talking about the time travel paradox, but rather the importance of human interaction in AI systems — and not just letting the AI run itself. Human interaction and oversight are critically important for the context and purpose of an AI system. Aside from Skynet, here are some examples of where human interaction is crucial:
Security and data privacy: Human experts are needed to assess and ensure the security of the AI systems and the protection of sensitive data. They can oversee access controls, encryption, and other security measures to safeguard against data breaches and unauthorized access.
Ethical considerations: Humans can evaluate the ethical implications of AI-powered actions and ensure that the software applications adhere to ethical standards. They can make decisions regarding the appropriate use of AI in sensitive situations.
Validation and testing: Human software developers and quality assurance teams are essential for thoroughly testing and validating AI-driven features. They can identify and rectify issues, reducing the risk of unintended consequences. This is particularly important for AI-assisted development when the output of your AI tool is code. A few ways of doing this in existing workflows might be during code review for example, but also using existing software, such as Snyk, to ensure you’re not adding security vulnerabilities into code.
Complex or sensitive decision-making: AI may assist in decision-making, but complex or high-stakes decisions often require human judgment, especially when lives or significant assets are at risk. If your AI capability performs big, significant actions on potentially sensitive data, or even has executable access to system functions, it’s worth considering a human interaction here to effectively sign off on whether these actions are reasonable and correct.
5. Identify and fix security vulnerabilities in generated code
AI can greatly speed up development by generating code. However, this generated code can sometimes contain security vulnerabilities. And by sometimes, I mean way more often than you'd want. The output of an LLM will only be as good as the input it’s given. I hate to burst the bubble here, but the average quality of open source code isn’t really that great — especially in terms of security, since OSS is often unpaid/labor of love.
If training data contains software vulnerabilities, then the suggested code generated will also contain vulnerabilities. The reason LLMs don’t know they’re suggesting vulnerable code is because an LLM doesn’t really understand the context of the code. It doesn’t truly understand the code paths, the data flows, etc.
As a result, it’s crucial to treat code generated from LLMs in the same way we do our own code. With AI code generation being even further left than a developer, as well as being an accelerator to code production and delivery it’s important we mitigate an increase in security vulnerabilities potentially reaching production. Luckily, the process is the same as when code developers manually write themselves, which includes performing code reviews, running automated security tests against changes, and validating that we don’t regress our security posture through our changes. Snyk provides this as code is being written, either AI or developer generated, throughout the CI/CD pipeline, including directly in the IDE as shown:
6. Don’t give IP or other private info to public GPT engines
When using public GPT engines for AI-assisted development, it's essential to avoid giving them any intellectual property (IP) or private information, since the public will be using the GPT. Sometimes we might want an LLM to analyze our code, perhaps because we want to understand what it’s doing, or maybe because we want it to be refactored. Whatever the reason, it’s important to ensure that you’re following the correct IP policies outlined by your organization.
As an example of IP data in a public GPT, Samsung discovered an employee uploaded sensitive internal source code to ChatGPT, and subsequently banned all usage of generative AI tooling. Educating teams and adding policies into GPT tooling usage is very important so sensitive IP doesn’t leave your premises.
Thankfully, OpenAI recently announced what they refer to as an enterprise-ready version of ChatGPT which does not use customer data or prompts as training data.
AI Models
A crucial aspect of LLMs is their adaptability, allowing developers to construct custom models tailored to specific legal domains or organizations. While this flexibility offers immense potential for innovation, it also introduces unique security challenges. As developers create their own models, they must be acutely aware of the need for robust security measures to protect sensitive legal data, striking a careful balance between customization and safeguarding against unauthorized access and data breaches. Thus, the intersection of AI and law not only ushers in a new era of legal support but also underscores the imperative of ensuring data security and confidentiality.
7. Use hybrid AI models where you can
Hybrid AI models, which combine different AI techniques, can offer better performance and security. Let’s start with LLM models initially. They’re great for the generative use of AI because they take huge amounts of data in and can fairly accurately construct a really good answer as a response which is understandable. However, does the LLM understand what it just wrote? Does it know the semantics of code or the appropriate pairings in a recipe based on flavor combinations? This is crucial when considering the accuracy or validity of the response it provides.
A good example of an AI model that does understand the context of the content is symbolic AI. If you haven’t heard of symbolic AI before, it’s a type of AI that represents knowledge using symbols, rules, and logic to perform tasks, often involving human-readable expressions and formal reasoning. This is one of the types of AI that Snyk uses under the hood in DeepCodeAI to understand code flows, data flows, and much more. By understanding the true context of code, it’s possible to be much more accurate, reducing false positives. As an example, take a look at the following interaction with ChatGPT:
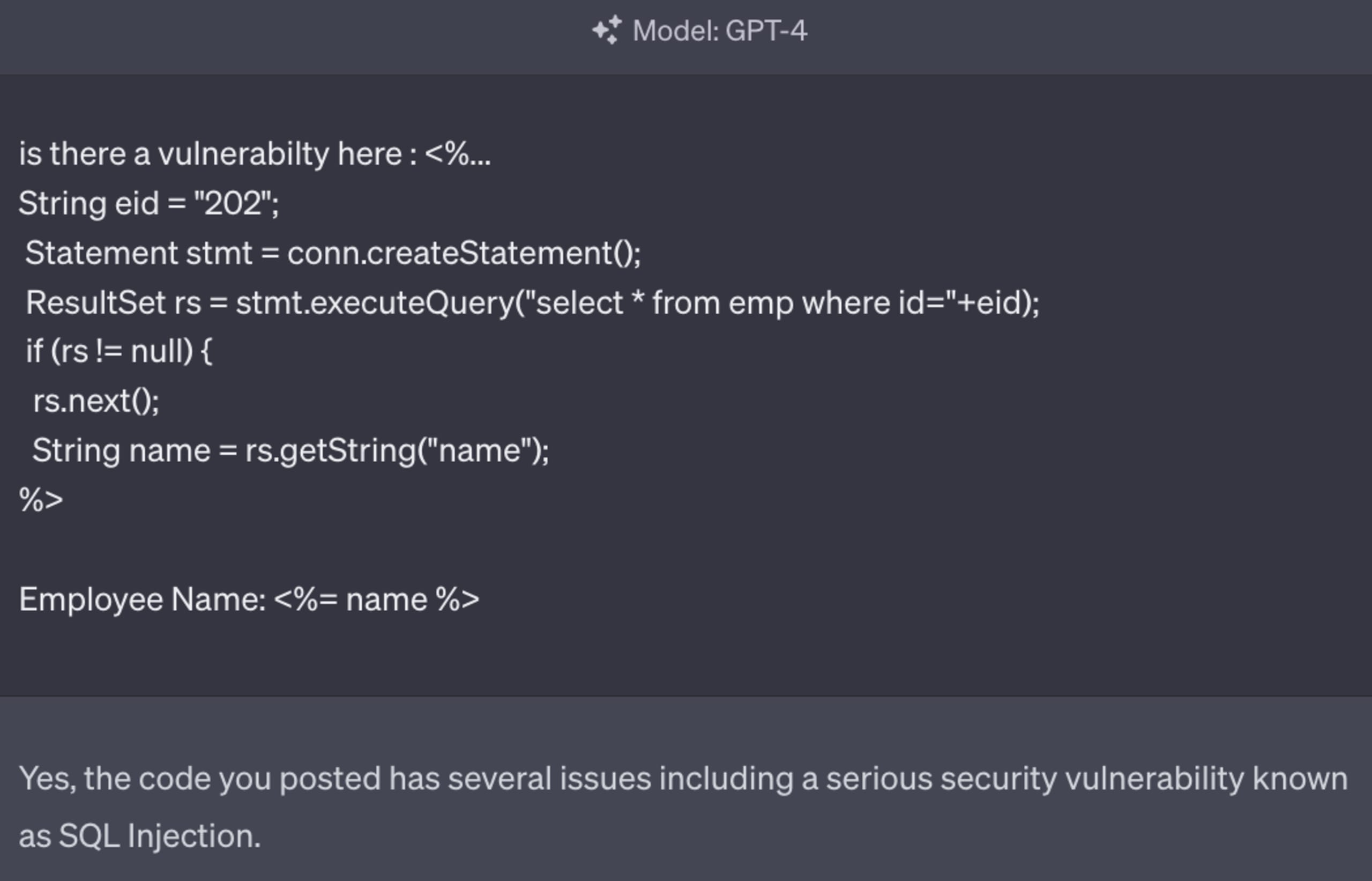
The query that is executed does indeed look like an SQL injection, however when we actually look at the data flow and understand where the data from variable eid comes from, we can see it’s a constant and doesn’t contain any user data whatsoever. This shouldn’t as a result be reported as a security issue since it’s a false positive. Snyk DeepCode AI, on the other hand, will find where the source of eid comes from, and recognize it’s not user data, and as a result, not something that could be tainted.
Snyk で AI のセキュリティを掌握
Snyk が開発チームの AI 生成コードを保護すると同時に、セキュリティチームに完全な可視性とコントロールを提供する仕組みをご覧ください。
8. Use good training data
AI models can also exhibit bias based on their training data. It's essential to be aware of this and take steps to reduce bias in your models. Bias in AI refers to systematic and unfair discrimination or favoritism in the decisions and predictions in AI output. It occurs when these systems produce results that are consistently skewed or inaccurate in a way that reflects unfair prejudice, stereotypes, or disparities, often due to the data used to train the AI or the design of the algorithms. Even you reading this blog will bias your views of AI and you might even be thinking of getting home and watching The Terminator tonight. Here are some examples of bias:
Data bias: Data used to train AI models may be biased if it does not accurately represent the real world or if it reflects historical biases and discrimination. For example, if an AI model is trained on biased historical hiring data, it may perpetuate gender or racial disparities in job recommendations.
Algorithmic bias: Bias can also be introduced through the design and optimization of algorithms. Some algorithms may inherently favor certain groups or outcomes due to their structure, leading to unequal treatment.
Selection bias: Selection bias occurs when the data used to train the AI is not representative of the entire population or scenario it aims to address. This can lead to skewed predictions or recommendations that do not apply universally.
Bias in AI has significant ethical and societal implications. It can lead to discriminatory outcomes in various domains, including hiring, lending, criminal justice, and healthcare. Addressing bias in AI involves careful data curation, algorithmic fairness considerations, and ongoing monitoring and evaluation to ensure that AI systems do not perpetuate or amplify unfair disparities. Ethical guidelines, regulations, and industry standards are also being developed to mitigate bias and promote fairness in AI systems.
Manipulation of training data is an issue that certainly needs a longer run-up by the attacker, but it can be significantly harmful when they are successful. Having quality training data is core to the accuracy, correctness, and trustworthiness of the output of an LLM. The quality of the output an LLM can provide is based on the quality of the input that is provided and the effectiveness of the neural network that is used to correlate output from user input.
Training data poisoning is when an attacker manipulates either the training data itself or the processes post-training during fine-tuning. The goal might be to make the output less secure, but it could equally be a competitive play to make it more biased, less effective, or less performant, for example.
Controlling the training data that is used in an LLM can be pretty tricky of course, and there is a huge amount of it — after all, it is a LARGE language model, built on huge amounts of data. So, verifying the source or the data itself when there’s so much of it, can be tough. OWASP suggests using sandboxing to ensure the datasets that are used as training data are not using unintended sources that have not been validated.
Finally, all of these sources of data should be tracked as part of your application’s supply chain, which we’ll cover a little later.
9. Beware of hallucinations and misleading data
AI models can sometimes produce "hallucinations" or be misled by incorrect data. The dangers of hallucinations and misleading data as output from an LLM can potentially be very great, and developers should be acutely aware and concerned about these risks. Hallucinations refer to instances where the AI generates information that is entirely fabricated or inaccurate, while misleading data can be more subtle, involving outputs that may appear plausible but are ultimately incorrect or biased.
To address these dangers, developers must invest in rigorous testing, validation, and ongoing monitoring of their LLMs. They should also prioritize transparency in how the AI systems generate results and be prepared to explain their decision-making processes. Moreover, developers should actively collaborate with others, through code reviews, etc. to validate and confirm the behavior of generated code, rather than simply accept what’s being generated.
Furthermore, LLMs do not possess the capacity to realize when they are wrong or hallucinating in the way humans do. We understand if we have a few facts we might make assumptions and be creative to fill in the gaps, but we have levels of confidence and recognize where we do this. LLMs generate responses based on patterns and information learned from their training data. They don't have consciousness or self-awareness, and they lack the ability to assess their own outputs for accuracy or correctness.
It's important for developers and users to implement safeguards and evaluation processes to identify and correct inaccuracies or hallucinations in AI-generated content. Additionally, feedback mechanisms, such as automated testing with Snyk as an example, should be in place to report and rectify errors.
10. Keep track of your AI supply chain
Supply chain vulnerabilities are easy to overlook in this Top 10, as you would most commonly think about third-party open source libraries or frameworks that you pull in when you hear the words supply chain. However, during the training of an LLM, it’s common to use training data from third parties. It’s important to first of all have trust in the integrity of the third parties you’re dealing with, and also to have the attestation that you’re getting the right training data that hasn’t been tampered with. OWASP also mentions that LLM plugin extensions can also provide additional risk.
This is still an early-stage type of attack, so there isn’t yet the supply chain support or standards that we have come to expect in our attempts to catalog the supply chain components we use. However, we can look at signing models or training data from an attestation point of view.
Something you should look at keeping an eye on for the future is the concept of an AI BOM (bill of materials) to reverse engineer how an LLM was built and trained.
AI is powerful and it needs to be secure
In conclusion, developing with AI securely requires a strong understanding of potential risks and how to mitigate them. This blog and cheat sheet provide you with areas of focus and tips of how to deal with them. Tools like Snyk can be of great help in this regard, providing robust security scanning and mitigation advice. If you're a developer or a security professional looking to enhance your AI security, take a moment to sign up for free and start using Snyk today.
脆弱性の自動検出および修正
Snyk は、コード、依存関係、コンテナ、およびクラウドインフラのワンクリック修正 PR と対策アドバイスを提供します。