GPT-4 を上回る精度:Snyk の CodeReduce が他の LLM のパフォーマンスをどのように改善したか

2024年5月7日
0 分で読めますSnyk は、2021 年の Snyk Code のリリース以来、AI を活用したサイバーセキュリティのパイオニアとして、SAST 分野で初のセキュリティ問題の特定に、DeepCode AI エンジンを通じて比類のない精度とスピードをもたらしてきました。過去 3 年間で AI と LLM が急速に発展する中、Snyk は、DeepCode AI Fix、脆弱性自動修正機能、サードパーティ依存関係到達可能性機能などの新しい AI ベース機能の導入において最前線に立っています。
Snyk は最近、Snyk Code によって特定されたセキュリティ上の問題を自動的に修正するベータ機能の DeepCode AI Fix におけるモデルの大幅な改善を発表しました。DeepCode AI Fix は、最新の AI テクノロジーと社内エキスパート機能を組み合わせて、信頼性の高い修正を生成します。セキュリティの問題の修正は複雑です。これを詳しく知るために、DeepCode AI Fix を支える主要テクノロジーの CodeReduce と厳選されたセキュリティ修正データセットについて説明した調査レポートを詳しく見ていきます。
セキュリティ修正の自動化 - 複雑な問題
開発者は多くの場合、セキュリティ上の問題を独自に発見して修正することに多くの時間を費やしています。DeepCode AI が登場する前、Snyk Code は問題を特定する最初のステップで開発者を支援していましたが、当時も、開発者はセキュリティのトレーニングを受けていないことが多く、その状態は今も変わらないため、セキュリティの問題を修正する次のステップは困難で時間がかかるものになる可能性があります。セキュリティの問題を修正するには、開発者が手動でコードをレビューし、コードがどのように機能するかを理解して、コードのコンテキスト内でセキュリティの問題を把握し、実際に問題を修正する前に修復方法を調査する必要があります。
自動化されたセキュリティ問題の修正、つまり「自動修正」は、修復作業の大部分を削減することを目的として、多くの企業が長年にわたって優先課題として取り組んできました。ところが、多くの試みにもかかわらず、精度の高い修正を含んだソリューションの作成は困難であることがわかりました。その結果、ほとんどの自動修正ツールは、少数の問題やわずか数行のコードに対する軽微な変更、単なる書式設定の問題などに対処することに重点を置いていました。
LLM の登場により、新世代の AI を使用してより優れた自動修正機能を構築する可能性が開かれました。ただし、LLM の場合でも、望ましい結果が得られるよう十分に設定されていなければ、セキュリティの問題を修復する方法は限定的になります。ほとんどの LLM は、さまざまなデータとコードを使用してトレーニングされていますが、セキュリティ修復に特化したトレーニングは受けていません。このことは、次の 2 つの重要な問題があることを意味しました。
セキュリティの自動修正のような特殊な分野の場合、LLM が適切で正確なコード修正を生成するためには、セキュリティおよびセマンティックコード修正の特殊なデータセットから学習できることが必要です。
ハルシネーションが起こりうること、また、LLM が限られたコンテキストを処理して出力を生成できることを踏まえると、「汎用」の LLM (セキュリティ用に特別にトレーニングされたものではない) をより精度の高い出力に導くためにプロンプトにコードを追加しても、必ずしも良い結果が得られるとは限りません。
LLM の制限に対処してより優れた修正を生成する
Snyk は、特定された問題に対処するために必要な作業よりも、LLM を使用するメリットの方が大きいと判断し、自ら問題を解決することにしました。
データセットの修正
できるだけ最良の結果が得られるように、オープンソースセキュリティ修正の包括的なデータセットを構築しました。まず、オープンソースコミットの大規模なラベル付けを実行し、JavaScript の問題と修正のクリーンなデータセットを構築しました (その後で、Java、Python、C/C++、C#、Go、APEX などの他の言語についても同様の措置を講じました)。次に、ラベル付きデータを手動で追加する代わりに、DeepCode AI エンジンによる Snyk Code のプログラム分析機能を使用して、データにラベルを付けるのと同じ定量的な効果を効率的に生み出し、クリーンなデータセットを作成しました。
CodeReduce テクノロジー (特許出願中)
CodeReduce はプログラム分析を利用して、報告された不具合と必要なコンテキストを含んだ短いコードスニペットに LLM がフォーカスできるようにすることで、修正の実行に必要なコード部分のみに LLM の注意機構を制限します。これによって、LLM で処理する必要があるコードの量が大幅に削減され、テストされたすべての AI モデルにわたって修正生成の質が向上し、ハルシネーションが軽減されます。さらに、モデルに渡される情報が少なくなるので、モデルの処理が高速化されます。また、リアルタイムの修正生成が可能になるため、より精度の高い的確な修正を取得できるだけでなく、修正の迅速化も実現します。
CodeReduce のプロセスには次のステップが含まれます。
セキュリティの問題を特定する
CodeReduce でコンテキストを使用して必要最小限のコードまで絞り込む
CodeReduce で処理したコードを LLM プロンプトに追加して、修正を生成する
修正を適用する
Snyk Code のスキャン機能を使用して、DeepCode AI Fix によって脆弱性が修正されたこと、および修正によって新たな脆弱性が導入されていないことを再確認する
MergeBack を使用して修正を元のコードにマージする
これらすべてをまとめた次の図は、セキュリティの問題を自動的に修正するためのパイプラインを示しています。CodeReduce に関する調査レポートで詳しく説明されている追加の最適化のおかげで、すべての処理が数秒で行われます。
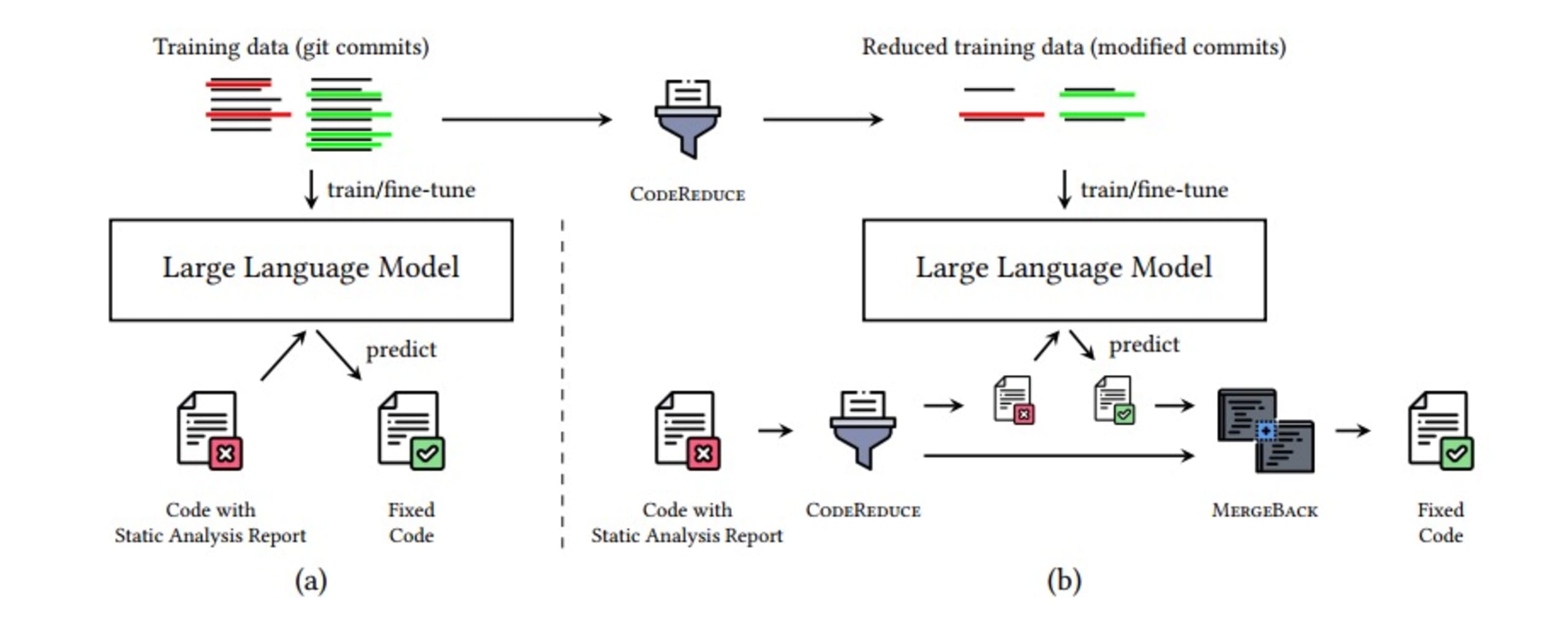
その結果は?
問題が解決された後は、自動セキュリティ修正がどの程度うまく機能するかをテストするため、さまざまな LLM 間で使用できるベンチマークを作成しました。
評価は、TFix (ウィンドウベースのモデル) およびさまざまなラージコンテキストモデル (GPT-3.5 や GPT-4 など) のベースラインに対して、CodeReduce を使用するモデル (次の表で ‡ 記号で示す) の「Pass@𝑘」および「ExactMatch@𝑘」メトリクスを使用して実行しました。
「Pass @k」の「k」変数は、毎回生成される 5 つの修正のうち、関連するセキュリティの問題に対処し、新しいセキュリティの問題を引き起こさない修正がいくつあるか (最小 1 個の修正から最大 5 個の修正まで) を測定します。
また、テストの対象にするセキュリティ問題のカテゴリも 5 つ定義しました。
AST:抽象構文ツリーを必要とするが、専用のデータフローを必要としない脆弱性
Local:不正な値を受け入れないメソッドに流入する不正な値
FileWide:シグネチャまたは実装の問題
SecurityLocal:API の使用状況、メソッド呼び出しの追跡
SecurityFlow:複雑なデータフローを必要とする複雑な汚染解析
また、比較のために、StarCoder、Mixtral、T5、GPT-3.5、GPT-4 などのさまざまな LLM も選択しました。結果は次のようになりました。
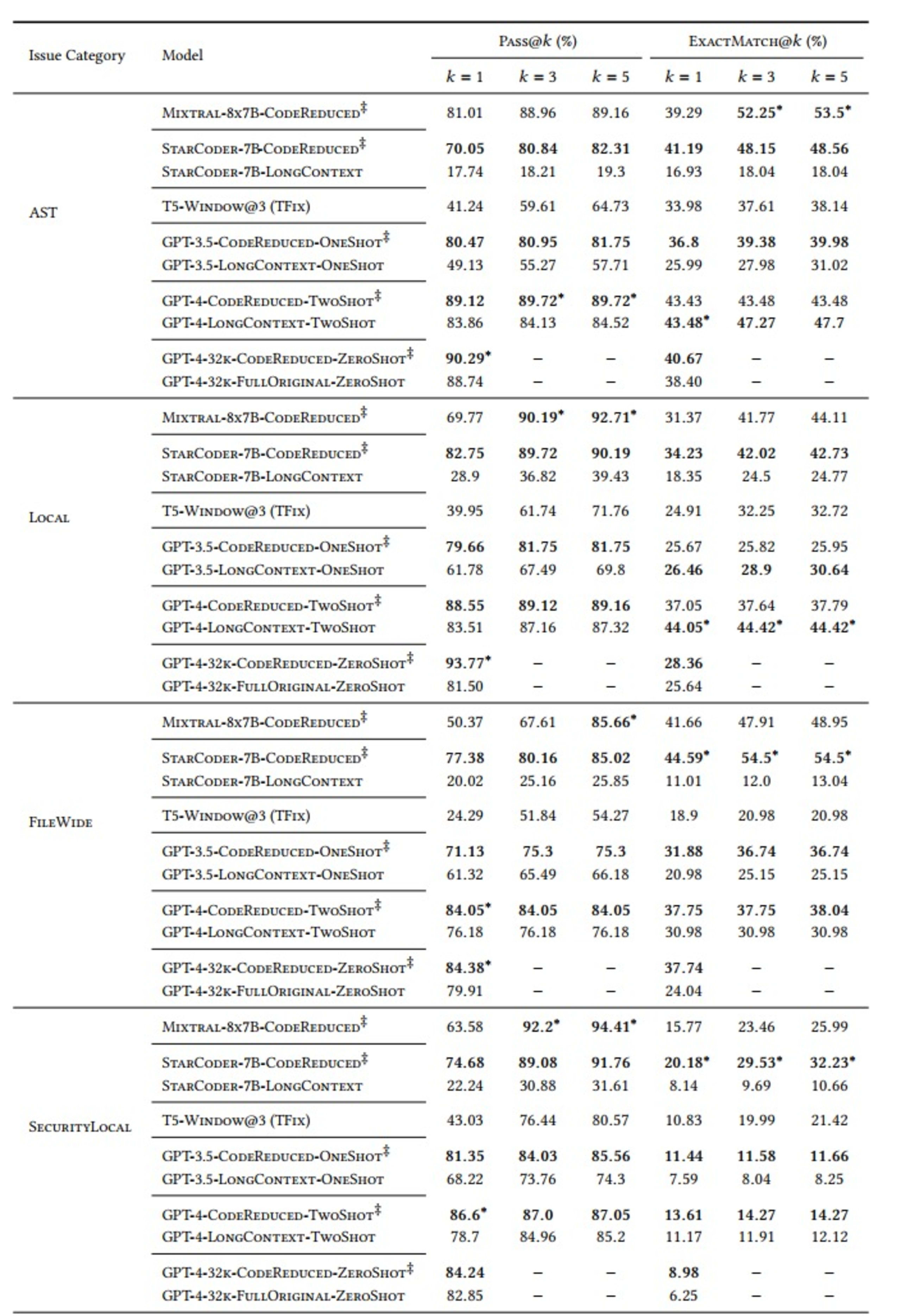
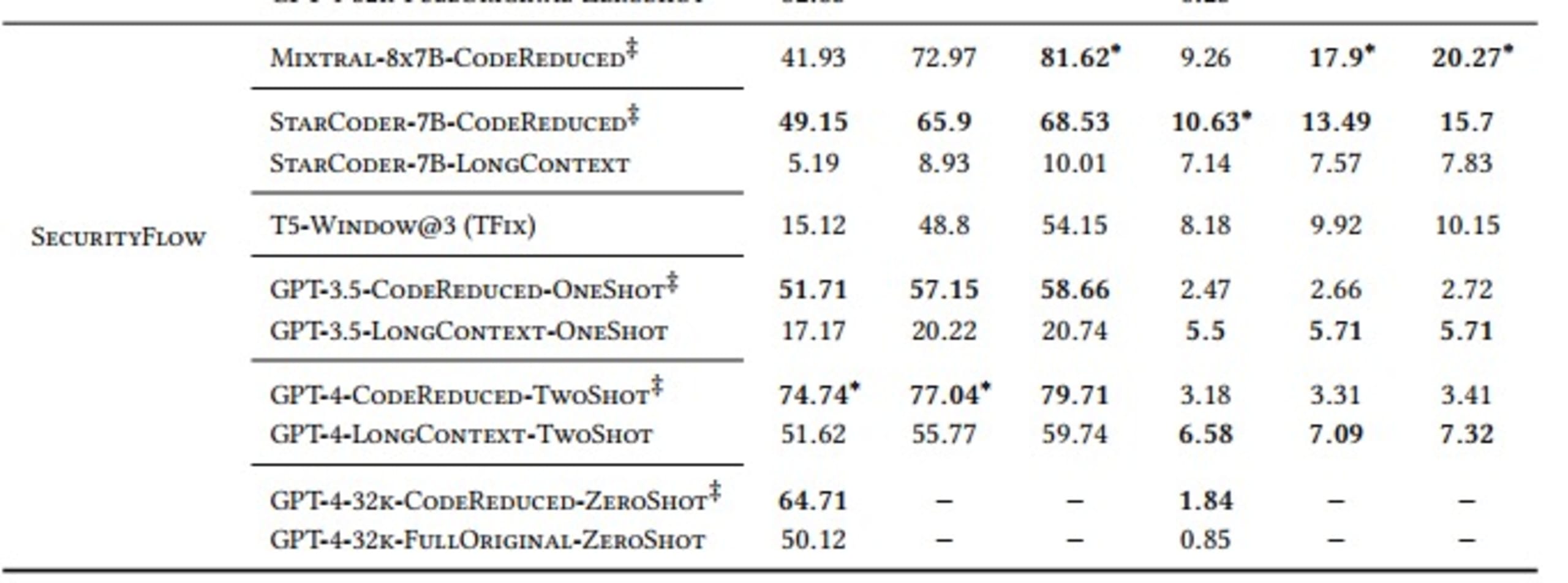
表に示すとおり、正しい修正を生成するために複雑な長距離依存関係を学習する必要があるモデルは、CodeReduce によって抽出されたコードコンテキストを使用すると、CodeReduce を使用せずに修正を作成する場合よりもパフォーマンスが大幅に向上します。そのことを示す良い例としては、StarCoder モデルを使用した場合の AST 問題の修正に関する Pass@5 の結果が大幅に改善され、成功率が 19.3% (CodeReduce なし) から 82.31% (CodeReduce 使用) に向上しています。
重要ポイント
DeepCode AI Fix は全般的に、TFix によって設定された以前の最先端ベースラインを上回り、複数の一般的な AI モデルのパフォーマンスをさまざまなセットアップで向上させました。これは、DeepCode AI Fix が Snyk 独自の CodeReduce テクノロジーによるプログラム分析を利用して、長距離の依存関係とデータ フローに対処できるためです。このようにして DeepCode AI Fix は、注意を払う対象を絞り込むことで、関連するセキュリティ問題の学習に伴うタスクを大幅に簡素化し、より正確で関連性の高い修正を提供します。
Snyk Code に登録し、Snyk プレビュー設定で Snyk Code の修正案を有効にすることで、DeepCode AI Fix の強力な機能を IDE で体験できるようになりました。詳細についてはドキュメントをご覧ください。また、Snyk Code 内から修正に関するフィードバックをお寄せください。DeepCode AI Fix の将来に役立たせていただきます。
Capture the Flag を始める
バーチャル 101 ワークショップオンデマンドで、Capture the Flag の課題の解決方法をご覧ください。