Automatic source locations with Rego

2024年2月12日
0 分で読めますAt Snyk, we are big fans of Open Policy Agent’s Rego. Snyk IaC is built around a large set of rules written in Rego, and customers can add their own custom rules as well.
We recently released a series of improvements to Snyk IaC, and in this blog post, we’re taking a technical dive into a particularly interesting feature — automatic source code locations for rule violations.
When checking IaC files against known issues, the updated `snyk iac test` command will show accurate file, line, and column information for each rule violation. This works even for custom rules, without the user doing any work.
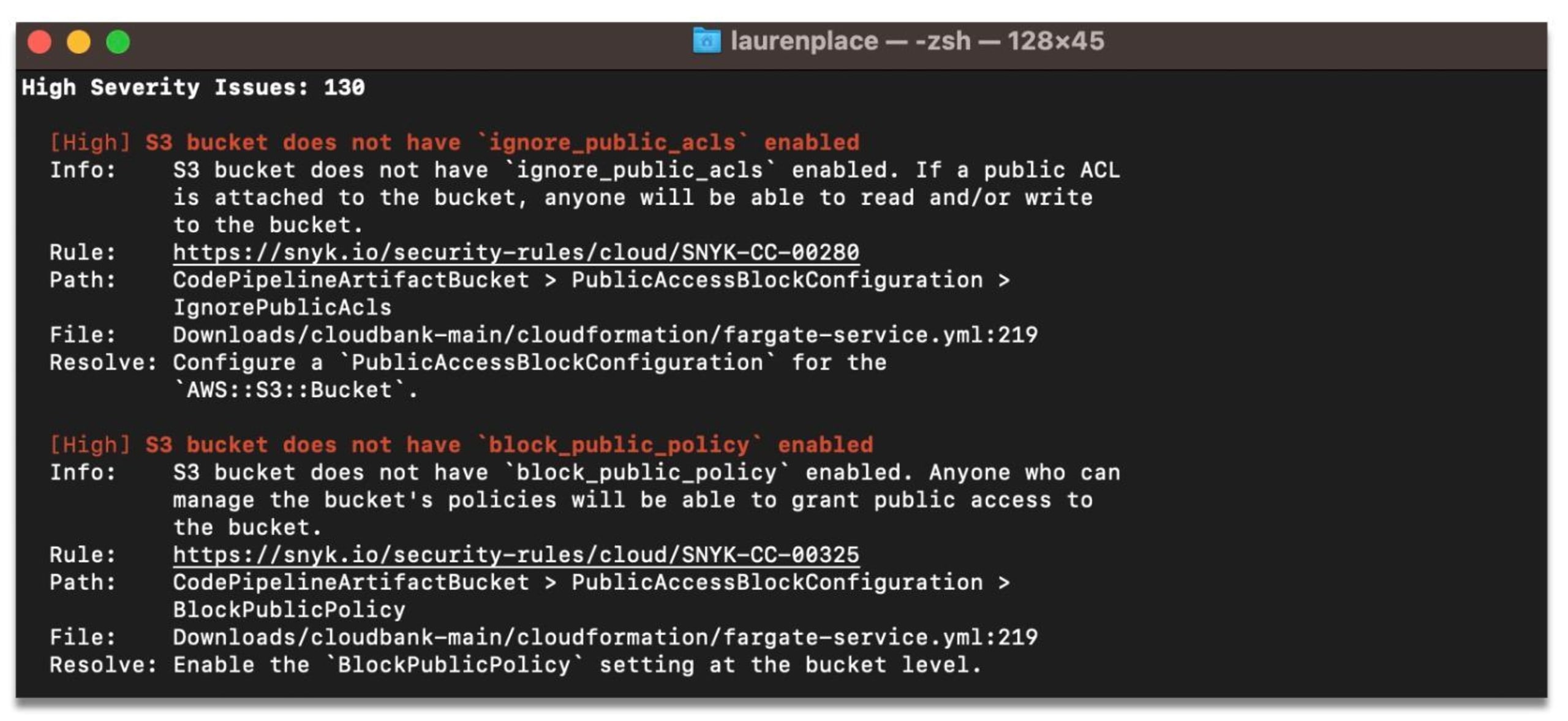
But before we provide a standalone proof-of-concept for this technique, we’ll need to make some simplifications. The full implementation of this is available in our unified policy engine.
Let’s start by looking at a CloudFormation example. While our IaC engine supports many formats, with a strong focus on Terraform, CloudFormation is a good example since we can parse it without too many dependencies (it’s just YAML, after all).
We want to ensure that no subnets use a CIDR block larger than `/24`, so let’s write a Rego policy to do just that:
This way, `deny` will produce a set of denied resources. We won’t go into the details of how Rego works, but if you want to learn more, we recommend the excellent OPA by Example course.
We can subdivide the problem into two parts:
We’ll want to infer that our policy uses the `CidrBlock` attribute
Then, we’ll retrieve the source code location
Let’s start with (2) since it provides a good way to familiarize ourselves with the code.
Source location retrieval
A source location looks like this:
We will also introduce an auxiliary type to represent paths in YAML. In YAML, there are two kinds of nested documents — arrays and objects.
If we wanted to be able to refer to any subdocument, we could use something akin to JSON paths. In the example above, [`"some_array", 1`] would then point to `"word"`. But since we won’t support arrays in our proof-of-concept, we can get by just using an array of strings.
One example of a path would be something like:
Now we can provide a convenience type to load YAML and tell us the `Location` of certain `Paths`.
Finding the source location of a `Path` comes down to walking a tree of YAML nodes:
Sets and trees of paths
With that out of the way, we’ve reduced the problem from automatically inferring source locations that are used in a policy to automatically inferring attribute paths.
This is also significant for other reasons — for example, Snyk can apply the same policies to IaC resources as well as resources discovered through cloud scans, the latter of which don’t really have meaningful source locations, but they do have meaningful attribute paths!
So, we want to define sets of attribute paths. Since paths are backed by arrays, we unfortunately can’t use something like `map[Path]struct{}` as a set in Go.
Instead, we will need to store these in a recursive tree.
This representation has other advantages. In general, we only care about the longest paths that a policy uses, since they are more specific. Our example policy is using `Path{"Resources", "PrivateSubnet", "Properties"}` as well as `Path{"Resources", "PrivateSubnet", "Properties", "CidrBlock"} — we only care about the latter.
We’ll define a recursive method to insert a` Path` into our tree:
…as well as a way to get a list of Paths back out. This does a bit of unnecessary allocation, but we can live with that.
We now have a way to nicely store the `Paths` that were used by a policy, and we have a way to convert those into source locations.
Static vs runtime analysis
The next question is to figure out which `Paths` in a given input are used by a policy, and then `Insert` those into the tree.
This is not an easy question, as the code may manipulate the input in different ways before using the paths. We’ll need to look through user-defined ( `has_bad_subnet`) as well as built-in functions ( `object.get`), just to illustrate one of the possible obstacles:
Fortunately, we are not alone in this since people have been curious about what programs do since the first program was written. There are generally two ways of answering a question like that about a piece of code:
Static analysis: Try to answer by looking at the syntax tree, types, and other static information that we can retrieve from (or add to) the OPA interpreter. The advantage is that we don’t need to run this policy, which is great if we don’t trust the policy authors. The downside is that static analysis techniques will usually result in some false negatives as well as false positives.
Runtime analysis: Trace the execution of specific policies, and infer from what `Paths` are being used by looking at runtime information. The downside here is that we actually need to run the policy, and adding this analysis may slow down policy evaluation.
We tried both approaches but decided to go with the latter since we found it much easier to implement reliably, and the performance overhead was negligible. It’s also worth mentioning that this is not a binary choice — you could take a hybrid approach and combine the two.
OPA provides a Tracer interface that can be used to receive events about what the interpreter is doing. A common use case for tracers is to send metrics or debug information to some centralized log. Today, we’ll be using it for something else, though.
Tracing usage of terms
Rego is an expressive language. Even though some desugaring happens to reduce it to a simpler format for the interpreter, there are still a fair number of events.
We are only interested in two of them. We consider a value used if:
1. It is unified (you can think of this as assigned, we won’t go in detail) against another expression, such as:
This also covers `==` and `:=`. Since this is a test that can fail, we can state we used the left-hand side as well as the right-hand side.
2. It is used as an argument to a built-in function, like:
While Rego borrows some concepts from lazy languages, arguments to built-in functions are always completely grounded before the built-in is invoked. Therefore, we can say we used all arguments supplied to the built-in.
3. It is used as a standalone expression, such as:
This is commonly used to evaluate booleans and check that attributes exist.
Now, it’s time to implement. We match two events and delegate to a specific function to make the code a bit more readable:
We’ll handle the insertion into our `PathTree` later in an auxiliary function called `used(*ast.Term)`. For now, let’s mark both the left- and right-hand sides to the unification as used:
`event.Plug` is a helper to fill in variables with their actual values.
An `EvalOp` event covers both (2) and (3) mentioned above. In the case of a built-in function, we will have an array of terms, of which the first element is the function, and the remaining elements are the arguments. We can check that we’re dealing with a built-in function by looking in `ast.BuiltinMap`.
The case for a standalone expression is easy.
Annotating terms
When we try to implement `used(*ast.Term)`, the next question poses itself — given a term, how do we map it to a `Path` in the input?
One option would be to search the input document for matching terms. But that would produce a lot of false positives, since a given string like `10.0.0.0/24` may appear many times in the input!
Instead, we will annotate all terms with their path. Terms in OPA can contain some metadata, including the location in the Rego source file. We can reuse this field to store an input` Path`. This is a bit hacky, but with some squinting, we are morally on the right side, since the field is meant to store locations.
The following snippet illustrates how we want to annotate the first few lines of our CloudFormation template:
`annotate` implements a recursive traversal to determine the `Path` at each node in the value. For conciseness, we only support objects and leave sets and arrays out.
With this annotation in place, it’s easy to write `used(*ast.Term)`. The only thing to keep in mind is that not all values are annotated. We only do that for those coming from the input document, not, for example, literals embedded in the Rego source code.
Wrapping up
That’s it, folks! We skipped over a lot of details, such as arrays and how to apply this to a more complex IaC language like HCL.
In addition to that, we’re also marking the `Type` attributes as used, since we check those in our policy. This isn’t great, and as an alternative, we try to provide a resources-oriented Rego API instead. But that’s beyond the scope of this example.
If you’re interested in learning more about any of these features, we recommend checking out snyk/policy-engine for the core implementation or the updated Snyk IaC, which comes with this and a whole host of other features, including an exhaustive rule bundle.
What follows is a main function to tie everything together and print out some debug information. It’s mostly just wrapping up the primitives we defined so far, and running it on an example. But let’s include it to make this post function as a reproducible standalone example.
The full code for this PoC can be found in this gist.
開発者のために設計された IaC セキュリティ
Snyk を導入すると、統一された Policy as Code エンジンにより SDLC からクラウドでのランタイムまで IaC が保護されるため、すべてのチームが安全に開発、デプロイ、運用できます。