Architecting a Serverless web application in AWS

2016年5月9日
0 分で読めますEditor's note
This blog originally appeared on fugue.co. Fugue joined Snyk in 2022 and is a key component of Snyk IaC.
Here at Fugue, the Web Team is a small but spirited minority—in favor of JavaScript, 60 frames per second, and keeping our DevOps simple. We like experimentation and new approaches to computing that favor substance and elegance over fad and bling. For some time, we’ve been using AWS Lambda with SNS topics and votebots, but we hadn’t tried anything big with it. Until now. The Serverless framework gave us the push we needed. Our goal? To power an application useful to a business function via an API built with Lambda and API Gateway, harming no EC2 instances in the process.
Let’s rewind for just a moment to give a brief explanation of AWS Lambda. Like IBM OpenWhisk, Google Cloud Functions, and Azure Functions, it's a service “for executing code in response to specific events such as a file being uploaded to Amazon S3, an event stream, or a request to an API gateway." Fintan Ryan, partially quoted, gives a good overview here. Your code is automatically scaled to meet requests. This kind of direct computing is on a trajectory of voracious expansion.
The application
The front-end web application we’ve built is straightforward. A user logs in and is presented with some content about our software builds and secure download URLs. The application lives in S3. We are building a REST API to power this experience. Consider the architecture of the API:
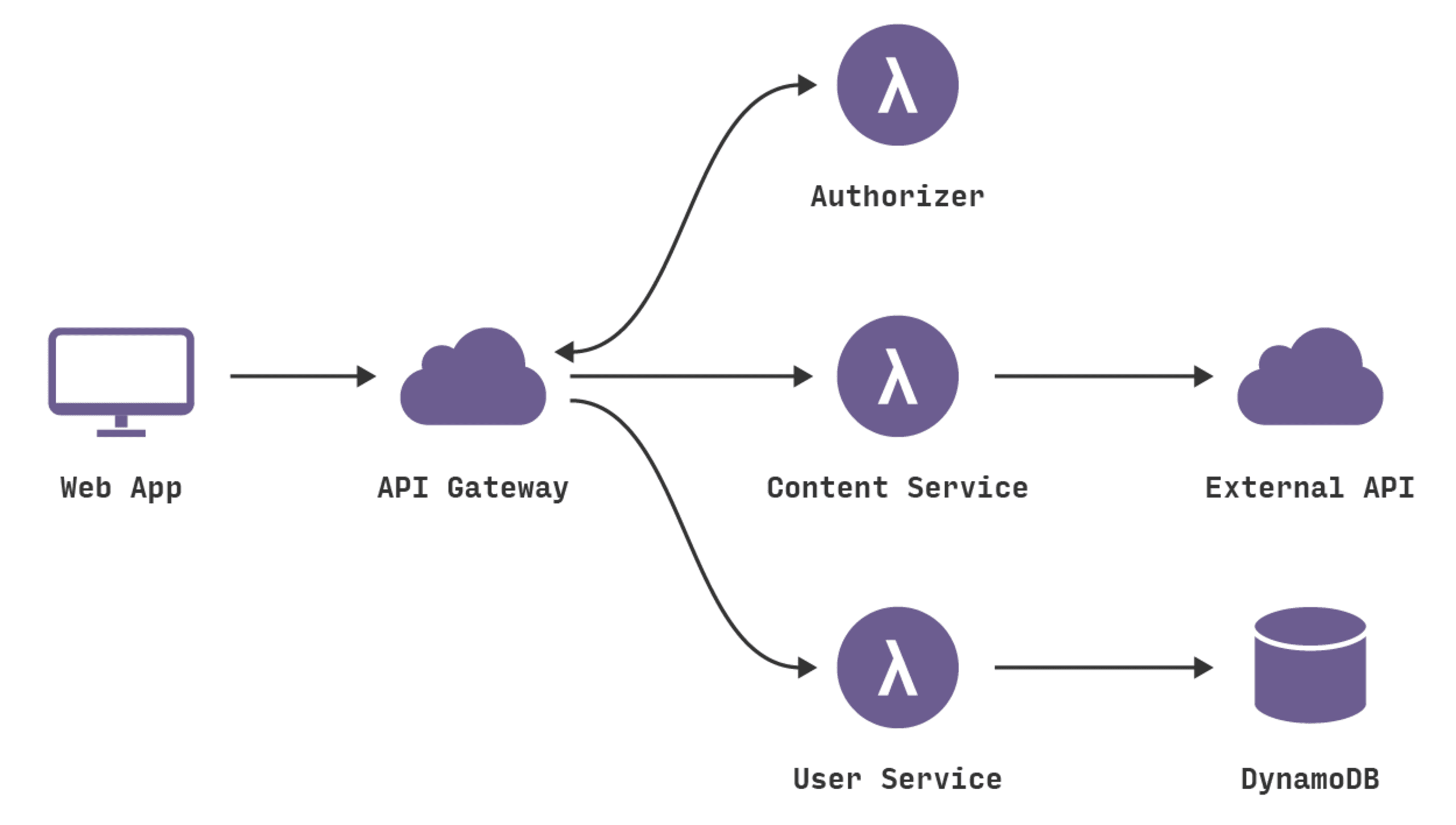
Notice that we have a set of API Gateway endpoints that trigger Lambda functions. The User Service Lambda stores data in DynamoDB. The Content Service Lambda connects to our distribution service API to retrieve content, does some cosmetic transformation, and passes that content back to the front-end application. The Authorization Lambda validates user session tokens and provides access to secured endpoints.
You could manually configure all of these services in AWS, but we’re using the Serverless framework as a deployment tool and to give our project some structure.
Introducing serverless
Serverless is a framework for building applications with Lambda and API Gateway. It also supports management of other AWS resources via CloudFormation templates. It comes in the form of a well documented Node.js CLI.
Serverless is powerful because it manages both your code and your AWS configuration. It has a specific project structure with JSON configuration files for your Lambda functions. The function configuration files include definitions for your API Gateway endpoints and other events that can trigger the function. To deploy your project, you have to create a Serverless user in your AWS account and grant it permissions for the services you’re using. You can then use the CLI to deploy, which configures the AWS services that you’re using and publishes your Lambda function code.
Addressing pain points
Serverless effectively addresses a few of the pain points we found while trying to set up this kind of project in AWS without using any framework:
1) Lambda functions are self-contained and can’t share code.
If you’re attempting a project with multiple functions, you’re probably going to want to share some code between them, even if it’s just a utils library. Lambda functions are deployed to containers in isolation, so your function can’t depend on a common library directory. Serverless solves this by allowing us to configure the specific directory level we want to include in the deployment package. As a result, you can include code in your function from a folder at a higher directory, which could also be used by other functions, and the included files will be zipped up with your deployment package.
2) Lambda functions don’t support environmental variables.
How do you securely include secret credentials like API keys in your Lambda function without inlining them in your code and making them visible to users of your Github repo? Serverless stores environmental variable definitions in JSON files in a gitignored _meta folder and inlines the values into your functions as part of the deployment process. If you’re working with a team, the Meta Sync plugin syncs these variable definitions securely through S3.
3) Making API Gateway communicate with Lambda is hard.
Every API Gateway endpoint needs a request template that specifies what information about the request will be available to the Lambda function it triggers. Your Lambda function is probably going to want to know the request path and method, the URL parameters, query parameters, and perhaps a custom header or a POST request body. None of that is available without a request template. Similarly, API Gateway doesn’t interpret a response from a Lambda function by default, so if your function returns an error, there is no automatic mapping to HTTP error response codes. You will need to add a response template to map error message strings from the Lambda function to the appropriate response code. Serverless makes this easier by supporting request and response template inheritance, so you can define universal templates for all of your endpoints and then override them on an endpoint by endpoint basis as necessary.
Project structure
Here’s the directory structure of our application’s Serverless project:
s-project.json
This contains the project name, description, and custom plugins that are being used by this project.
s-resources-cf.json
This is a CloudFormation template for the resources that this project uses aside from Lambda and API Gateway. In our case, this is a DynamoDB table and an IAM role and policy for the Lambda function that allows it to read and write to DynamoDB.
_meta
This folder contains JSON files of environmental variables for the project, potentially specific to deployment stage and region. This folder is gitignored.
functions
This folder contains subfolders for each of our Lambda functions. Serverless is agnostic to organizational structure here, so you can nest functions inside folders however you choose. A function folder must contain a file with your function code (in this case, handler.js) and an s-function.json file, which contains function configuration and the endpoints that can trigger your function. It also can contain an event.json, which holds a test object that we’ll talk about later. As we mentioned before, we have a lib folder which sits next to our function folders and which each function folder (i.e., user, content) can include.
A closer look at Serverless project components
There are three key architectural components to our Serverless project: Lambda functions, an API Gateway REST API, and other AWS resources like our DynamoDB table and IAM role. Let’s take a deeper look at how we’re using these components.
Lambda functions
Apart from the authorizer Lambda function, which we’ll talk about in a minute, we have separated our code into two functions: content and user. Why?
Technically, you can divide your Lambda code up however you want. All of your endpoints could trigger a single function, which would parse the request and figure out how to respond. Or you can create functions for every endpoint and event in your project. We took a hybrid approach of grouping code into microservice functions after considering a couple of factors:
Code organization
Assigning similar endpoints to one function makes sense. All of our user-related code is working with the same database table and using the same external libraries. If we group this similar code into one function, we can be sure that code changes will immediately apply to all endpoints.
Performance
Lambda documentation indicates that smaller functions perform better. Function latency is much higher if the function hasn’t been invoked recently—in our experience, if the invocation hasn’t happened within about five minutes. After the first invocation, the latency then drops dramatically. The amount of initial latency, or “cold-start time,” is directly related to the size of the function. Smaller functions have quicker cold-start times. (You also can improve this cold-start time by increasing the memory allocation for your functions, which proportionally increases CPU.)
This slow cold-start time is not a problem for asynchronous Lambda use cases, but it is a problem for an API that will get a limited amount of traffic. Our API has to respond quickly or the user experience of the application will suffer.
Bundling related functionality into larger Lambda functions ensures a level of priming. For example, when a user logs into their account and then sees their profile, that might be two API calls. The first one could be a slow, if the function hasn’t been invoked recently, but the second one is guaranteed to be fast if both endpoints are triggering the same function.
Note: We’ve discussed keeping our functions primed by simply pinging an endpoint once every five minutes. This would doubtless work, but we haven’t felt the need to implement it.
Function handler
In our s-function.json file, we define the function handler. In our case, it’s a function called handler in handler.js. This is the function that will be called when the Lambda function is invoked. Here’s what the content function’s handler.js looks like:
As you can see, it’s really just acting as a router for our function. All of the important code is abstracted out into /lib/download.js, which is not aware that it’s part of a Lambda function. This makes writing unit tests for our code easier, since /lib/download.js is just a JavaScript file with no special Lambda dependencies.
API Gateway REST API
Endpoints are configured in the s-function.json file. Here’s an example of an endpoint configuration:
This endpoint will be available at GET /downloads.
Request and Response Templates
You saw $${requestTemplate} and $${responseTemplate} in the endpoint configuration above. That’s indicating that the downloads endpoint will inherit requestTemplate and responseTemplate that we defined in a global templates file for our project.
Request and response templates are represented in JSON and use JSONPath expressions. You can manipulate JSONPath expressions using Apache Velocity Template Language (VTL). The syntax is a little tricky.
Serverless recently added support for YAML request and response templates, but we’re currently using the JSON format. Here’s a look at our request template:
Yep, it looks a little crazy, as escaped JSON inside JSON is wont to do, but it generates an event object for the Lambda function that contains everything we need to know about the request:
body contains the parsed JSON body of the request
path is the path of the requested endpoint
method is the HTTP method used by the request
headers contains all the HTTP headers in the request
params contains the path parameters of the request
query contains the query parameters of the request
authorizedUser is the username of the authorized user, if the endpoint required authorization
And here is our response template. If the Lambda function succeeded, the result string is passed through as JSON to the user (using the response200 template fragment). If the function failed, the regexes will attempt to match against the result string. We’re responding with different HTTP error codes based on the error message.
Handling authorization
We’re leveraging two API Gateway features for the permissions component of our application: API keys and custom authorizer functions. Both of these features allow us to simplify our application code by removing any authorization concerns from the core Lambda functions.
API keys
API Gateway allows you to create an API key and assign it to individual endpoints. We’re using this to protect certain sensitive endpoints that shouldn’t be accessed client-side, like user management. API Gateway will look for an x-api-key header on any requests to the selected endpoints and try to match the value against the API key we created. If the header is missing or incorrect, the request returns a 403 error and never invokes the Lambda function.
Custom authorizers
API Gateway recently added custom authorization, which allows a Lambda function to control endpoint access. An incoming request will invoke the custom authorizer function with an authorization token from a specified custom request header. The custom authorizer will do some validation on the authorization token (in our case, a JSON Web Token), and return an IAM policy to authorize the request. If the policy is invalid for the request or if authorization fails, API Gateway will return a 403. If the policy is valid, the assigned Lambda function for the endpoint is triggered.
Here’s an example of the IAM policy that our custom authorizer returns:
Since our web app does not have granular permissions, we’re granting access to every endpoint in the API that uses the custom authorizer. The generated IAM policy will be cached by API Gateway with the authorization token that was used to generate it. Subsequent requests to any protected endpoint with the same authorization token header will automatically get this policy, bypassing the custom authorizer, for a TTL that you specify.
Serverless project workflow
Environments
At a minimum, our project needs separate development, testing, and production environments.
Serverless has the concept of “stages,” which are implemented in different ways in different AWS services, but together they act like an environment.
Lambda: Every time the code of a Lambda function is changed, a new version of the Lambda is automatically created. Lambda functions can have aliases for versions, and Serverless uses aliases to point at different versions for different stages. For example, if the dev stage is published, and becomes v1 of the Lambda function, Serverless also creates a dev alias to point to v1. If the prod stage of the function is published next, the prod code becomes v2, but the dev alias is still pointing at v1.
API Gateway: A single API in API Gateway can have multiple stages. Each stage of an API endpoint can trigger a different Lambda alias, so the dev API Gateway stage can use the dev alias of the Lambda function, whatever version that happens to be pointing to. The stage name becomes part of the endpoint path.
Other AWS services, like DynamoDB tables, S3 buckets, etc., exist individually per stage.
Testing
Each Lambda function folder can contain a mock event object for testing in an event.json file:
serverless function run will execute the function using event.json as the event. This is useful for end-to-end function testing.
There are a few Serverless plugins that simulate API Gateway locally for testing, like Offline and Serve. Since API Gateway is still actively adding features, we found that those plugins did not always support the features we were trying to use, so we ended up doing most of our API Gateway testing in the AWS Console.
We’re using Jasmine for unit tests on our lib JavaScript files.
Deployment
Three things need to be deployed for our project to be ready for use: functions, endpoints, and project resources (again, these are the AWS resources listed in s-resources.json). We can deploy these individually, using these CLI commands:
Or, we can use the snazzy interactive deployment dashboard, via the serverless dash deploy command:
Using either of these options, we can deploy very granularly, so it’s possible to update one function or one endpoint without changing anything else.
The interactive dashboard is really nice for local development and testing, but for use with continuous integration tools, we use the first set of commands. By default, the CLI will prompt you for missing options, but you can disable this interactivity by setting an environment variable called CI to true. We use Travis CI for continuous integration and deployments, so Travis executes our unit tests and then uses the CLI in CI mode to deploy our code to AWS.
Check out the Serverless CLI reference for more details.
Final thoughts
A few months ago, our CEO Josh shared his thoughts about AWS Lambda and cloud’s continuing evolution. He noted:
Lambda is an opinionated service regarding application architecture in a way that traditional PaaS offerings aren't. It doesn't pretend to be a traditional computer or cluster of traditional computers. Instead, Lambda is event-driven by nature and imposes statelessness at the function level. This means you'll need to think a little differently about how to compose an application. You gain near infinite scalability and very low cost compared to compute instances or containers. As a trade-off, you commit time to learning, but may very well invent some new patterns during your experimentation and inquiry.
Agreed. Committing the time to learning and doing is worth the effort. We hope the example laid out here is useful. More frameworks like Serverless are likely to pop up in the near future, but it’s a good one for getting your feet wet and producing a solid web app.
開発者のために設計された IaC セキュリティ
Snyk を導入すると、統一された Policy as Code エンジンにより SDLC からクラウドでのランタイムまで IaC が保護されるため、すべてのチームが安全に開発、デプロイ、運用できます。