RPM Package Manager: RPM package security scanning with Snyk
Ivan Stanev

2020年11月13日
0 分で読めますAs part of scanning container images, Snyk can detect various pieces of information like the operating system distribution, software package manager, installed applications, and all of the application dependencies. RPM is one of the most common package managers in the Linux ecosystem and is fully supported in Snyk.
What is the RPM Package Manager?
RPM is used in many Linux distributions including Red Hat Enterprise Linux, Fedora, CentOS, and others. It originated in Red Hat Linux, and originally stood for RedHat Package Manager, although it's now a recursive acronym that stands for RPM Package Manager. RPM can refer both to the package manager, and to the rpm file format which it uses to distribute applications.
What data format does RPM use?
The RPM package manager is particularly challenging to work with because it does not list its dependencies in a human-readable format (like JSON or XML). Instead, packages are stored in binary format in a BerkeleyDB database which makes reading these packages infeasible unless we know the correct binary format and layout of both the database and the database entries.
While there was open source code available to read the RPM database, we could not easily use it in Snyk because our technology stack is based on Node.js and TypeScript. It is possible to compile and use C bindings for BerkeleyDB but we wanted to avoid the overhead of cross-compiling and maintaining this, and we also only needed a library that reads RPM packages, which is a tiny subset of the functionality provided by both RPM and BerkeleyDB.
Through the magic of open source, the BerkeleyDB license used in RPM allowed us to freely read and modify the code so we opted to recreate the functionality ourselves. In the end, we solved the challenge and released a fully open source TypeScript library which you can find on our Snyk rpm-parser repository on GitHub.
In this blog post, I want to share how we did this and to explain the process of dissecting the internals of the RPM database. Prepare for some low-level bits and bytes tinkering! ?ï¸
What does an RPM database look like?
We know that BerkeleyDB is a binary database so how can we extract meaningful content? Binary file formats are usually detected by peeking at the start of a file where you can find a special marker (for example, a "magic number") that denote the type of the file. The best way to find this out is to read the source code and try it out on a copy of the RPM database. The BerkeleyDB database created by RPM is stored under /var/lib/rpm/Packages so our first stop is to inspect its contents. The BerkeleyDB source code shows us that the first few bytes of the file contain this:
typedef struct _dbmeta33 {
DB_LSN lsn; /* 00-07: LSN. */ db_pgno_t pgno; /* 08-11: Current page number. */ u_int32_t magic; /* 12-15: Magic number. */ u_int32_t version; /* 16-19: Version. */ u_int32_t pagesize; /* 20-23: Pagesize. */ u_int8_t encrypt_alg; /* 24: Encryption algorithm. */ u_int8_t type; /* 25: Page type. */ /* omitted */}
BerkeleyDB supports several types of databases: B-Tree, Hash (HStore) and Queue, and other types in most recent versions. Every database type has a different magic number: 0x053162 for B-Tree, 0x061561 for Hash, and 0x042253 for Queue. It turns out that every RPM database that we open is of type Hash because we find the magic number 0x061561 starting at byte 12 of the /var/lib/rpm/Packages file, and also the type stores the value 0x08, which the source code type definitions list as the following:
#defineP_HASHMETA8/* Hash metadata page. */
The field pagesize and a subsequent last_pgno (last page number) in the type definition tell us that the database is split into equally-sized pages. This also means that individual data items can be spread across multiple database pages and the pages are most likely not in order (as we will find out later once analyzing them).
It turns out that this generic database metadata is shared between every database type, so this initial _dbmeta33 section is further extended depending on the database type. Since we are only interested in the Hash database we get the following extra data:
typedef struct _hashmeta33 {
DBMETA dbmeta; /* 00-71: Generic meta-data page header. */ /* omitted */ u_int32_t nelem; /* 88-91: Number of keys in hash table */ /* omitted */ u_int8_t iv[DB_IV_BYTES]; /* 476-495: Crypto IV */ u_int8_t chksum[DB_MAC_KEY]; /* 496-511: Page chksum */}
Through nelem (number of elements) we can also understand how many elements we have in the database. But the iv (initialization vector) and chksum (checksum) hint that encryption is probably used.
If we read these bytes and store them in a JavaScript object which we can later print, we get something like this:
{
/* omitted */ "crypto_magic": 0,
"iv": [ /* lots of zeros */ ],
"chksum": [ /* lots of zeros */ ],
"dbmeta": {
"pgno": 0,
"magic": 398689, /* 0x061561, which is the Hash DB magic number */ "version": 4,
"pagesize": 4096,
"encrypt_alg": 0,
"type": 8, /* Hash DB */ "free": 1259,
"last_pgno": 3837,
"nparts": 0,
"key_count": 146,
"record_count": 146,
"flags": 0,
"uid": [ /* a bunch of bytes */ ],
/* omitted */ }
}
It turns out that RPM does not use encryption for the database, at least not by default, so we can ignore this use-case completely.
So far we have the following view of the database layout:
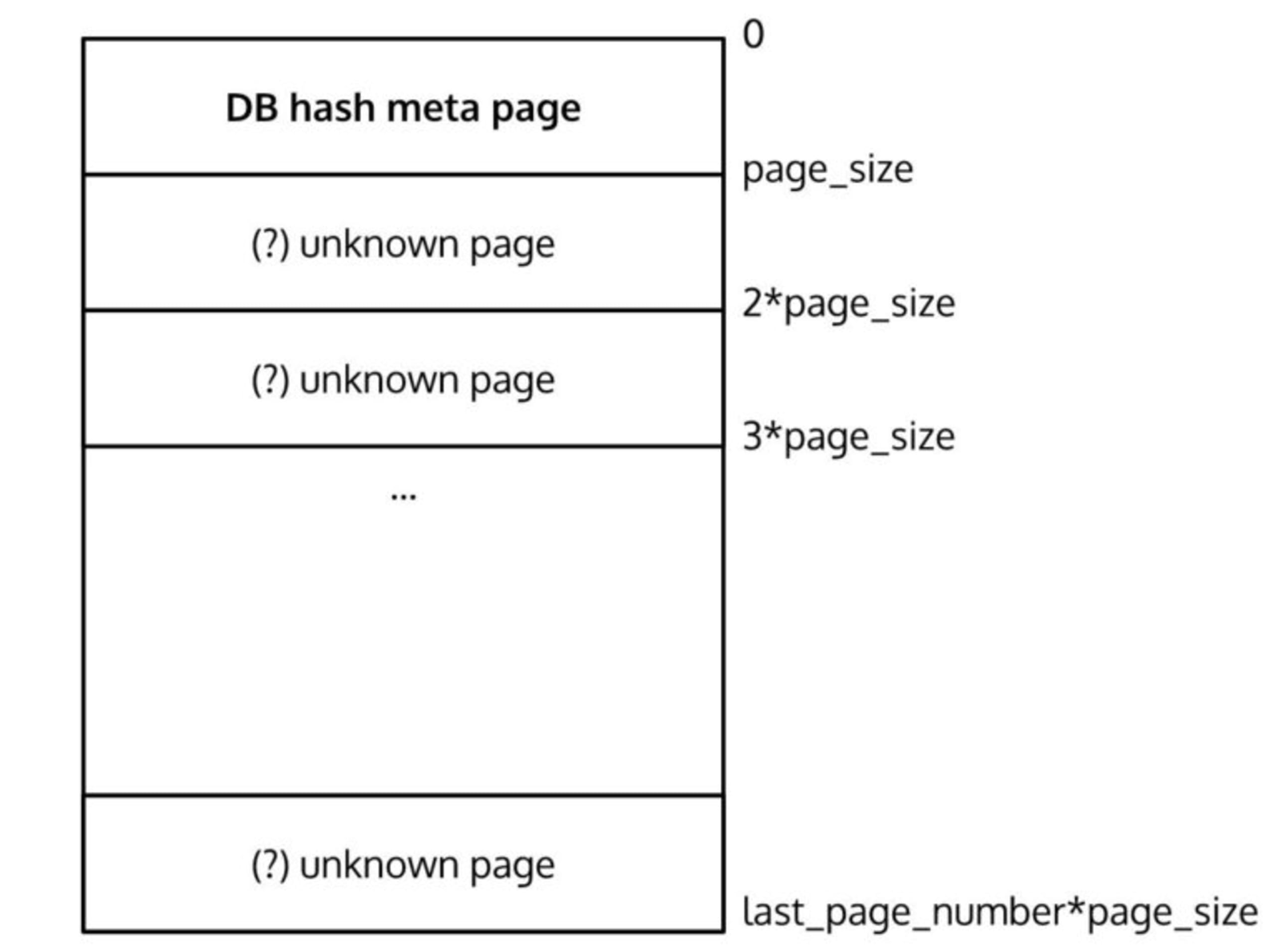
Since a page is 4096 bytes long and the first page is the database metadata, let's go to the next page and see what type of data we can expect. The BerkeleyDB source code is also very helpful and tells us to expect the following layout:
*+-----------------------------------+
*| lsn | pgno | prev pgno |
*+-----------------------------------+
*| next pgno | entries | hf offset |
*+-----------------------------------+
*| level | type | chksum |
*+-----------------------------------+
*| iv | index | free --> |
*+-----------+-----------------------+
*| F R E E A R E A |
*+-----------------------------------+
*| <-- free | item |
*+-----------------------------------+
*| item | item | item |
*+-----------------------------------+The type definitions give us the sizes of each of these entries. So, by reading the right amount of bytes, we can map them to a JavaScript object and get the following:
{
"pgno": 1,
"prev_pgno": 0,
"next_pgno": 0,
"entries": 148,
"hf_offset": 2845,
"level": 0,
"type": 13,
/* omitted */}Notice the type: 13 which notes a completely new type of page, which the type definitions list as:
#defineP_HASH 13 /* Sorted hash page. */
The prev_pgno and next_pgno are set to 0 which means that the data (whatever it is) is fully stored in this page and we do not have to go to other pages to collect it.
Notice the value of hf_offset. Looking at the whole data stored on the page, we see that bytes around the ~2850 byte mark are zeroed, which corresponds with the value of hf_offset. This means that hf_offset points to where the data finishes on the page. This will be particularly useful later once we read data items from multiple pages and we want to know where the data starts and where it ends.
So every page starts with a generic 26-byte page header and the rest of the 4070 bytes are partially or fully filled with data. The hash-type page contains an index with entries that point to some byte/offset on the current page. These offsets point to data at the opposite end of the page. The way this data is stored on the hash page resembles how a stack and a heap look like:
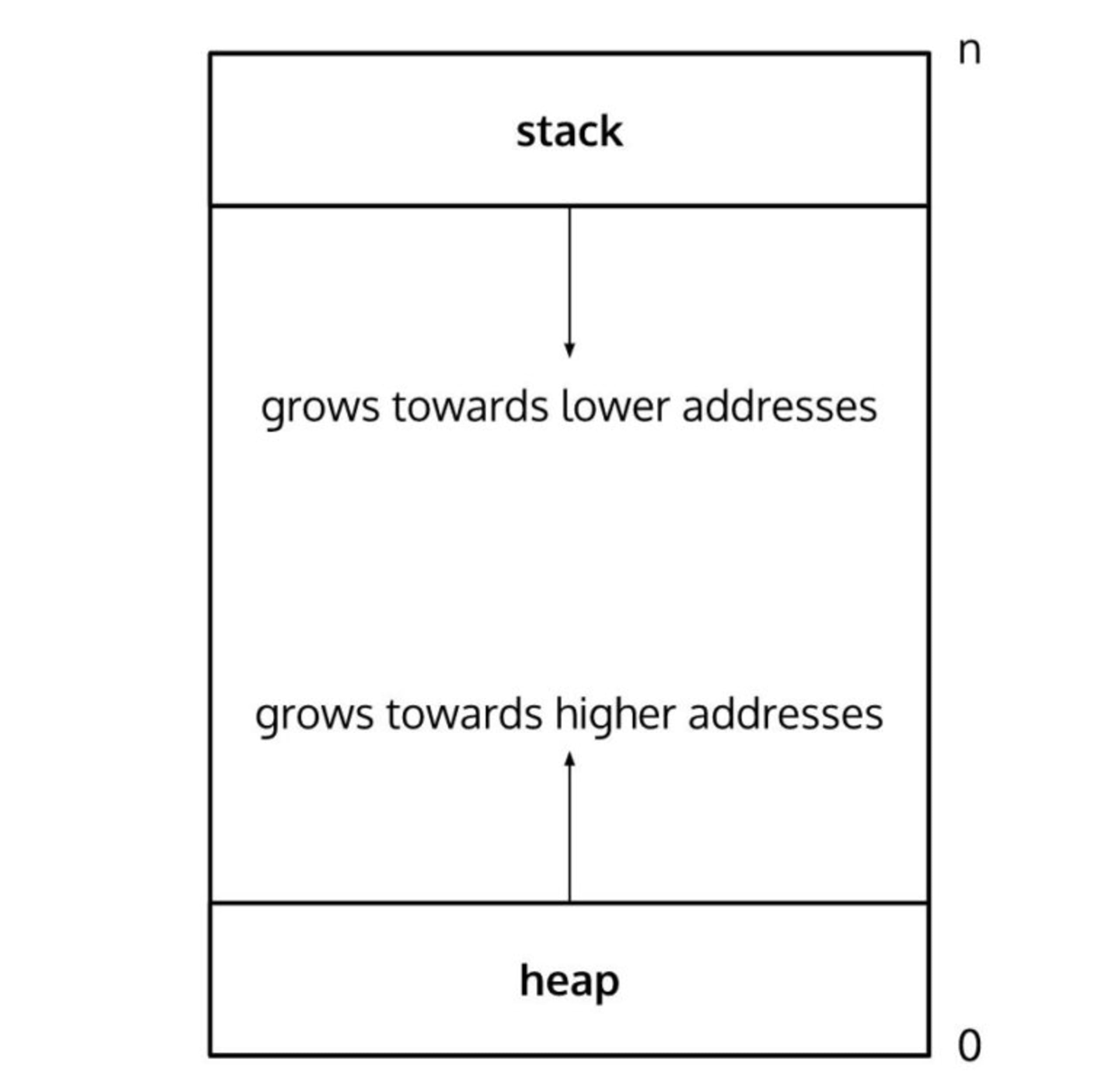
The index is stored in the heap region of the page whereas the data (pointed to by the offsets in the index) is stored in the stack region.
The index contains entries as pairs of keys and values, listed one by one. The key is an internal identifier to the database, the value points to an offset within the current page. We can find a type definition that helps us interpret what is stored at each offset:
typedef struct _hoffpage {
u_int8_t type; /* 00: Page type and delete flag. */ u_int8_t unused[3]; /* 01-03: Padding, unused. */ db_pgno_t pgno; /* 04-07: Offpage page number. */ u_int32_t tlen; /* 08-11: Total length of item. */} HOFFPAGE;
With this piece of data we could determine where in the whole BerkeleyDB this piece of data is stored, or at least where it begins. The data starts at a specific page number and can span multiple pages if the length is higher than the page size (remember the pagesize we read from page 0?).
So far we have the following view of the database:
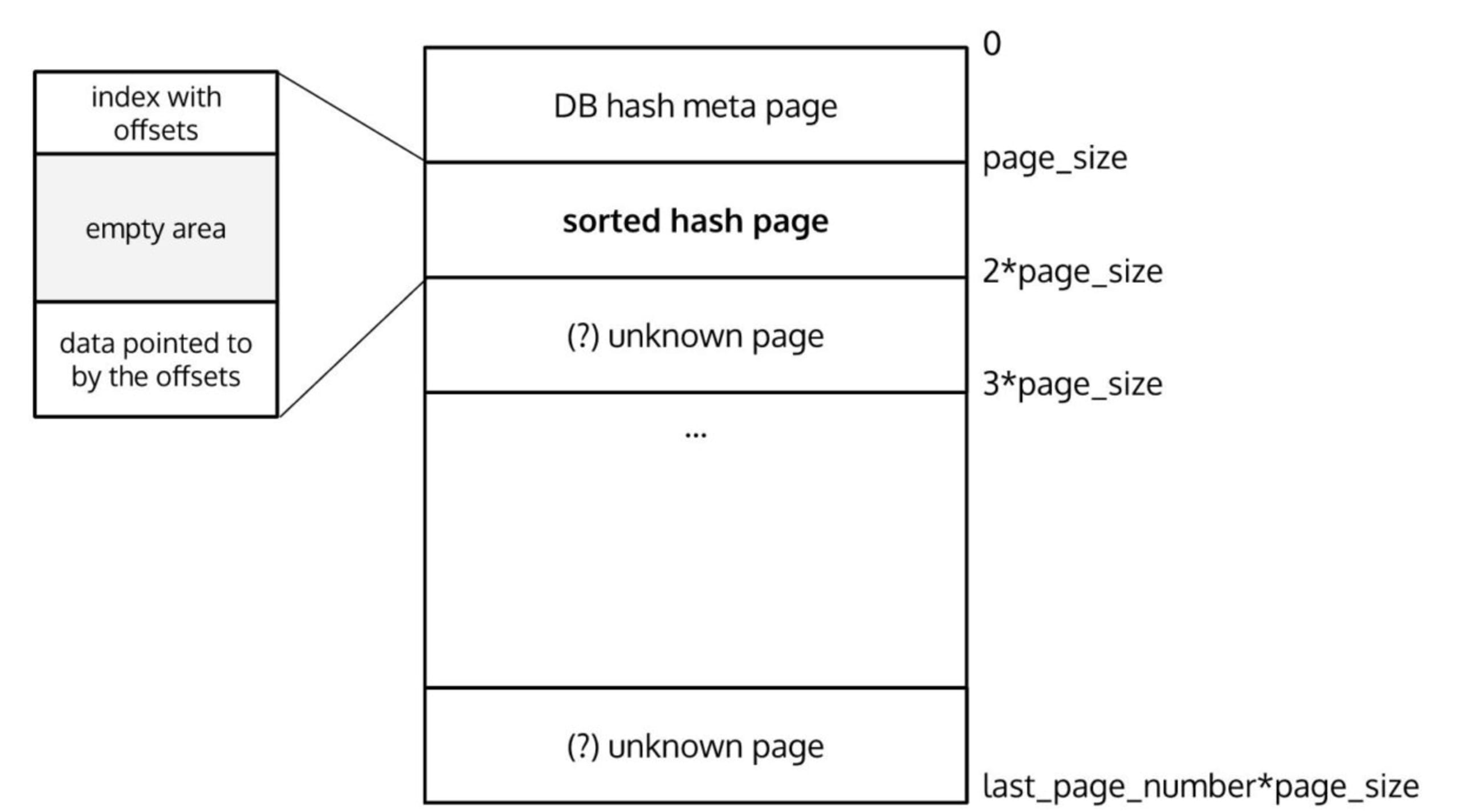
Next let's take an entry from the data index (represented by struct __hoffpage) and peek at the page that it points to. We can load that page (since we know its number as well as the size of each page) and see what the contents look like:
{
"pgno": 3,
"prev_pgno": 0,
"next_pgno": 4,
"entries": 1,
"hf_offset": 4070,
"level": 0,
"type": 7,
/* omitted */}
Notice the next_pgno has a value and it points to the next page that contains the rest of the data. hf_offset has the value of 4070 which means that this whole page is filled with data (it is 4070 bytes long because the page size is 4096 bytes minus the generic page header of 26 bytes). So to get the full data we have to traverse several pages by following next_pgno and collate all the bytes together.
The final view of the database looks like this:
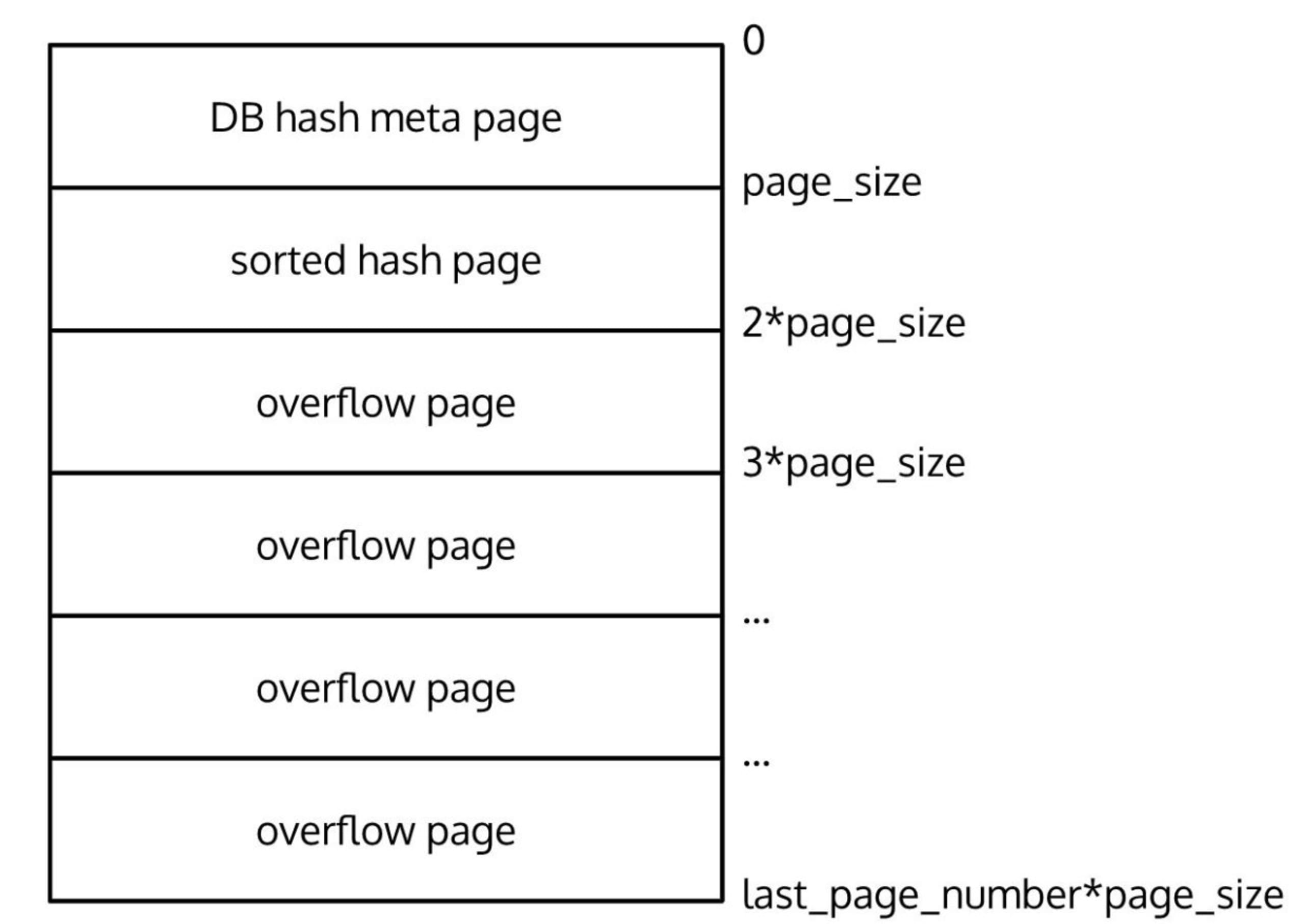
This is everything we need to know to be able to read the data! Once we traverse all connected overflow pages we collect a list of binary blobs, which are the actual RPM packages. The next step is reading the packages to extract information such as the package name, version, architecture, and so on.
Parsing RPM package metadata
This is where we switch from the BerkeleyDB context to the actual RPM package and metadata format. To understand what an RPM package looks like, we consult the RPM file format documentation.
An rpm file consists of four sections: a lead, a signature header, a payload header, and a payload (the actual data). Both header sections have the same format. The format of each of these is specified in the following sections. Each of the sections appears one after another in the file, with no additional information before, between, or after them.
Through some trial and error, we find that what the BerkeleyDB stores in the binary blobs is actually these two items: a partial payload headerand a full payload. The lead and signature header are completely omitted. If we look at the RPM docs, the structure of the payload header looks like this:
+---+---+---+---+---+---+---+---+---+---+---+---+
|HM1|HM2|HM3|VER| RESERVED | INDEXCOUNT | (more ->)
+---+---+---+---+---+---+---+---+---+---+---+---+
+---+---+---+---+===============+============+
| STORESIZE | Index Entries | Data Store |
+---+---+---+---+===============+============+It turns out all the HMx (header magic) entries, the version, and the reserved bytes are missing as well! Instead, we get a partial header that includes the indexcount (the number of header index entries), the storesize (the size of the data store in bytes), the index entries and the data store.
Worth noting here is that the data is actually stored in big-endian format so every entry needs to be explicitly read/interpreted as such.
So far the binary blobs we have collected from BerkeleyDB look like this in pseudocode:
// pseudocode:
blob {
indexcount: int32be;
storesize: int32be;
index_entries: int8[];
data: int8[];
}
We can quite easily read the first 2 items but in order to read the index_entries we need to understand their layout. The RPM file format documentation tells us this:
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
| TAG | TYPE | OFFSET | COUNT |
+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+---+
// pseudocode:
index_entry {
tag: int32be;
type: uint32be;
offset: int32be;
count: uint32be;
}
Each index_entry turns out to be 16 bytes long. With this knowledge and with the value of indexcount we can collect all the RPM header entries.
We can now read all of the index entries in JavaScript and produce a list similar to the following:
[
{ tag: 1000, type: 6, offset: 2, count: 1 },
{ tag: 1004, type: 9, offset: 27, count: 1 },
{ tag: 1006, type: 4, offset: 168, count: 1 },
/* omitted */]Looking at the RPM documentation we can see a table of what every tag value represents. Tags specify package information such as name (1000), version (1001), architecture (1022), and so on. The type can also be seen in the RPM documentation and we note entries like string (6), int32 (4), or even the null type (0).
Now using the offset we can jump to the start of the data for each of these entries while being careful to also include the indexcount in the offset calculation—we want to land where the data is positioned. And based on the value of type we can treat the subsequent array of bytes that we encounter in a particular way: for example, for string types we can read the sequence of bytes until we reach a 0 byte, which corresponds to the end of the string (as typical for C-style software). Alternatively, if we have an int32 type we know that we should read only 4 bytes.
With all this information we can loop through all the entries in the index and we can eventually extract enough package data to construct a dependency. Here is an example of one entry:
{
name: 'libgcc',
version: '7.3.1',
release: '6.amzn2.0.4',
size: 179192,
arch: 'x86_64'
}Repeating the same process for all BerkeleyDB blobs helps us extract all package information and to produce the list of dependencies.
Summary
We dived deep into the inner workings of the RPM package manager to understand the binary layout of the data and how the information about installed packages is represented internally. This is the exact same process that Snyk uses to read and understand the list of dependencies in your container images. Snyk is free to use, and you can sign up for an account. You can also check out our open source library RPM parser on GitHub that does this heavy work!
Capture the Flag を始める
バーチャル 101 ワークショップオンデマンドで、Capture the Flag の課題の解決方法をご覧ください。