Demystifying HTTP request smuggling
Sam Sanoop

30. Juni 2020
0 Min. LesezeitHTTP request smuggling is an interesting vulnerability type that has gained popularity over the last year. This vulnerability could allow an attacker to leverage specific features of the HTTP/1.1 protocol in order to bypass security protections, conduct phishing attacks, as well as obtain sensitive information from requests other than their own.
It should also be noted that request smuggling has received widespread community attention through numerous high-paying bug bounty reports in the last few months, and Snyk observed that 18 HTTP request smuggling related to dependencies have been published in 2020 so far.
This vulnerability was first discussed by Watchfire in their 2005 whitepaper entitled “HTTP Request Smuggling”. This work was later expanded upon by researcher Regis Leroy and further discussed by James Kettle from Portswigger security during BlackHat USA 2019 which gained further media attention.
This blog post aims to demystify the vulnerability and provide remediation details for open source project maintainers looking to patch HTTP request smuggling within their projects.
Background
With new attacks and vulnerabilities gaining popularity and media traction, open source libraries are often targeted by attackers to be exploited in the wild. It can often take weeks or years for these vulnerabilities to be remediated properly within these libraries due to a lack of remediation knowledge. In order to make the open source community secure, the Snyk Security Team often conducts research into vulnerabilities, such as HTTP request smuggling, to discover vulnerabilities within open source dependencies and provide actionable remediation advice to maintainers.
One such task was undertaken by Snyk to identify the impact of HTTP request smuggling within the open source dependency ecosystem which resulted in discovering numerous vulnerabilities. More information regarding the discovered vulnerabilities can be found here.
Snyk found that there are not enough public sources that provide proper guidance into remediating HTTP request smuggling. Furthermore, it was noted that it took maintainers multiple releases to properly address and remediate this vulnerability. With this blog post, we aim to close that gap and help provide detailed remediation advice to any maintainer looking for guidance on this issue.
HTTP request smuggling vulnerability explained
In order to understand HTTP Request Smuggling, the following areas must first be understood:
Keep-Alive and pipelining
The concept of keep-alive and pipelining was initially published in RFC 2616.
The Keep-Alive header is a hop-by-hop header that provides information about a persistent connection. In web servers, Keep-Alive can be specified within the “Connection” header which allows a web server to keep a TCP socket/connection open. By using this header, multiple requests and responses can use a single connection which can reduce overhead and improve performance for a web server. This feature is supported by all browsers and servers today.
Pipelining is another feature that was introduced in RFC 2616. This allows a web server to process requests asynchronously—as a first-in-first-out stream rather than processing each request individually, allowing it to send a request without waiting for a previous response to arrive.
Content-Length and Transfer-Encoding
HTTP requests can have a message body. The presence of a message body in a request is signaled by a Content-Length or Transfer-Encoding header field. These headers are used for message framing, telling a server where a message ends and another begins.
The Content-Length, specified in RFC 7230, section 3.3.2, is an HTTP header that indicates the size of the entity-body of the request. This is commonly seen in HTTP POST requests which have a body of data. It should be noted that GET requests typically shouldn’t contain the Content-Length header since they have no body.
Transfer-Encoding, also specified in RFC 7230, was created to allow the sending of binary data over HTTP. Transfer-Encoding has numerous directives, this blog will focus on the chunked directive.
The chunked directive allows data to be sent in a series of chunks along with the length of these chunks specified in hexadecimal format, followed by carriage return and a line feed. The end of a chunked directive is stated by 0 and an empty sequence. An example of a chunked request can be seen below.
Request smuggling
A modern web server stack will often contain multiple web servers along with load balancers and WSGI servers. A basic diagram to visualize this can be seen as:

HTTP request smuggling vulnerabilities arise when the frontend and the backend interpret the boundary of an HTTP request differently causing desynchronization between them. This is due to numerous frontend and backend libraries deviating from RFC specifications when dealing with both the Content-Length and the Transfer-Encoding header. HTTP request bodies can be framed according to these two headers and deviations from the specification occur. As a result, part of a request gets appended or smuggled, to the next one which allows the response of the smuggled request to be provided to another user.
This vulnerability can be exploited to conduct phishing attacks, cache poisoning, Cross-Site Scripting (XSS), and more. More information regarding exploiting this vulnerability was published by James Kettle last year, during BlackHAT USA 2019, titled “HTTP Desync Attacks: Request Smuggling Reborn”. This blog will focus on the two most common request smuggling techniques:
CL:CL: Double Content-Length attack technique
CL:TE: Content-Length Transfer-
Encoding attack technique
CL:CL: Double Content-Length attack technique
According to RFC 7230, section 3.3.3#4:
“If a message is received without Transfer-Encoding and with either multiple Content-Length header fields having differing field-values or a single Content-Length header field having an invalid value, then the message framing is invalid and the recipient MUST treat it as an unrecoverable error”
However, most middleware and web servers currently will loosely handle GET requests with a body. Furthermore RFC 7231, section 4.3#4.3.1 states “A payload within a GET request message has no defined semantics; sending a payload body on a GET request might cause some existing implementations to reject the request”. This indicates this is a behavior most servers and proxies might support. In some cases, this can result in request smuggling attacks. This blog will explore one variation of this attack.
When provided with two Content-Length headers, if implementation differences occur between a frontend and a backend on which Content-Length header to prioritize, smuggling attacks can occur.
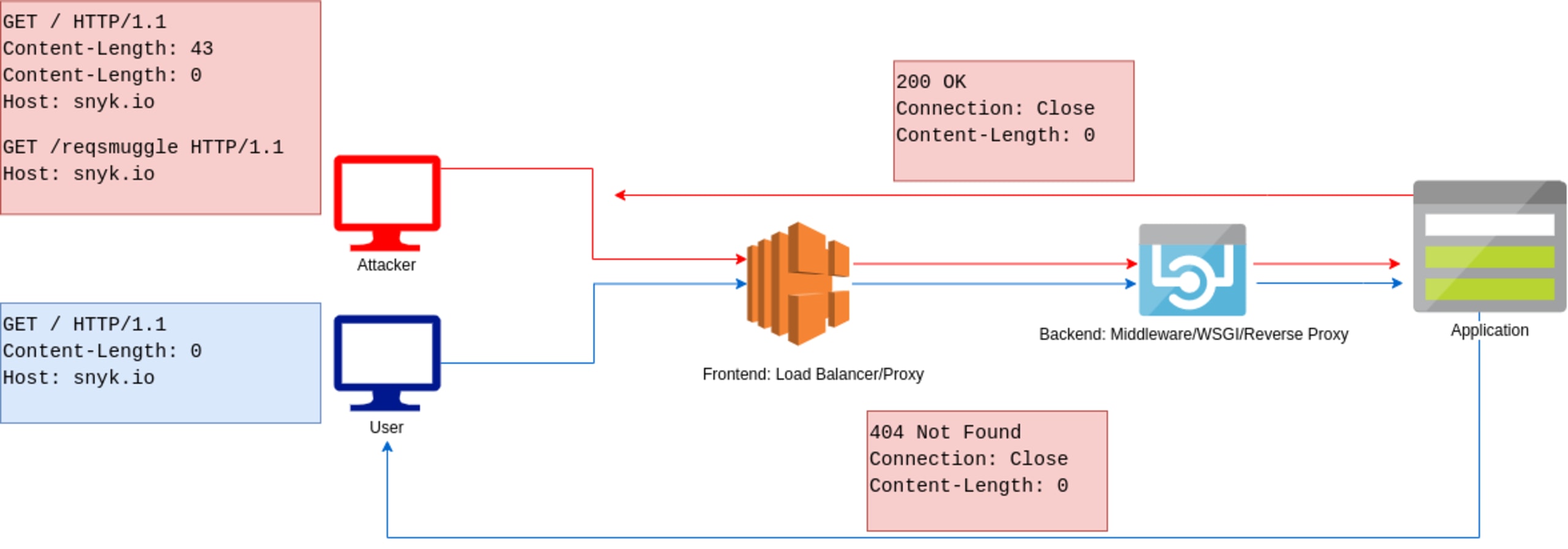
In the above HTTP request, a request with two Content-Length headers is sent to a target that has a proxy or a load balancer as a frontend. The proxy will respect and prioritize the first Content-Length and see the smuggled request as part of the request body, even though a GET request shouldn’t have a request body, and two Content-Length headers are provided. When this is processed by the backend, the first Content-Length header is ignored and the second Content-Length header is prioritized. Since the second Content-Length was set to zero, the backend will expect no request body and the /reqsmuggle request is treated as another pipelined request. As such, the response of this smuggled request could be received by another user.
CL:TE: Content-Length Transfer-Encoding attack technique
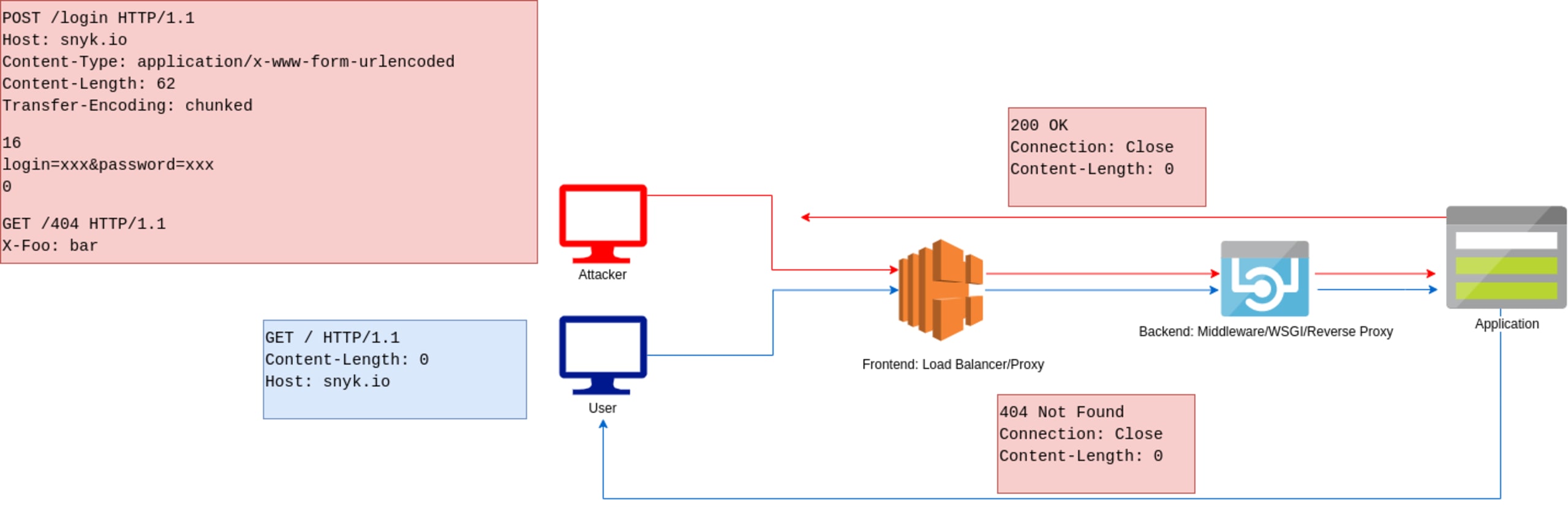
This popular technique discovered by James Kettle of PortSwigger labs involves placing a Content-Length header and a Transfer-Encoding header in a single HTTP request and manipulating it in a way where a frontend proxy and backend server will prioritize these headers and process the smuggled request differently. An example request which demonstrates this vulnerability can be as follows.
When this request gets processed by a frontend proxy, it will respect the Content-Length header and prioritize this over the Transfer-Encoding header. However, the backend server will prioritize the Transfer-Encoding header. As such, the backend will process the request and will end at the character 0. As a result, the 404 GET request gets treated as a separate pipelined request.
This issue occurs because the frontend prioritizes the Content-Length over Transfer-Encoding header. According to RFC 7230 Section 3.3.3#3, if a message with both Content-Length and Transfer-Encoding is accepted, the Transfer-Encoding header overrides the Content-Length. This is not followed by the frontend.
In cases where the frontend might prioritize the Transfer-Encoding header, it might be possible to bypass this limitation by inserting a malformed transfer encoding header instead of a valid one. Some examples of this can be seen below:
Numerous HTTP libraries tolerate different variations of the Transfer-Encoding header and will normalize them to improve client experience. As such, by understanding what variations of the Transfer-Encoding header is normalized by the backend server, it might be possible to smuggle a malformed Transfer-Encoding header through the frontend and conduct a CL:TE smuggling attack.
The examples above just demonstrate the vulnerability. In a real attack scenario, a smuggled request can be crafted to conduct phishing attacks, or steal data from a victim’s request and send that to an attacker-controlled server.
Scope and misconceptions
During this research, Snyk identified numerous cases where the obvious complexity of the multiple attack vectors led to misconceptions about HTTP request smuggling being reported to open source maintainers by researchers and maintainers, not always understanding if the criteria of remediation are in the scope of their maintained library or if it should be dealt with a dependency they are using as part of their library.
Some of the challenges which required further clarification are as follows:
Proxies/Load Balancers and other mediums, that can be categorized as frontend, are most affected by this vulnerability. However, a successful request smuggling attack requires the exploitation of both a vulnerable frontend and a backend.
The responsibility of remediation falls onto a backend maintainer as much as a frontend maintainer. One can argue that normalizing malformed headers should be acceptable behavior from a backend and make it more tolerant to user faults, and that the real problem is proxies which forward these requests without normalizing them first. But due to the vast ecosystem of dependencies and numerous libraries fitting the criteria of a backend and frontend, it is ideal for both parties to try and remediate this issue.
Middlewares, web servers that support reverse proxy capabilities, WSGI/High-Performance servers are considered to fit the backend criteria, not a web server that just supports the processing of malformed requests but doesn’t support pipelining.
Security reports are often disclosed to maintainers as HTTP request smuggling issues due to servers responding to multiple requests sent and this being visible as two separate responses. It should be noted that many servers support Keep-Alive and pipelining—this by itself does not make an HTTP request smuggling vulnerability. This is the case in CVE-2020-12440 reported for NGINX.
Remediation
HTTP request smuggling issues occur due to deviations from the current HTTP specifications and multiple libraries not following RFC7230. Furthermore, remediation of this vulnerability can be tricky depending on whether you are a frontend or backend project maintainer. As such, Snyk has researched the remediation implemented by open source projects currently and categorized it as follows. To simplify, all remediation points are covered along with reasoning to which smuggling attack type this will remediate against. In an ideal scenario, all of the points mentioned below should be used to provide a Defense-in-Depth approach solution.
Prioritize Transfer-Encoding over Content-LengthRemediation:This remediation will prevent CL:TE and TE:CL attacksScope: Frontend, BackendDetails:When a request with both a Transfer-Encoding: chunked header and Content-length is received, the transfer-encoding header should be prioritized over Content-Length. This is referenced in RFC 7230 Section 3.3.3#3.
Disallow requests with both Content-length and Transfer encoding and double Content-Length headersRemediation: This remediation will prevent CL:CL, CL:TE and TE:CL attacksScope: Backend, Frontend, Backend, Upstream librariesDetails: This can be seen as a better alternative to “Prioritize Transfer-Encoding over Content-Length” solution. Runtime platforms such as Node.js have used this solution to remediate against request smuggling where any requests with both headers are returned with an HTTP 400 response.
Snyk believes this technique to be an ideal fix to prevent smuggling issues. However, considerations should be taken on how the fix is applied; especially if the fix is applied to a low-level HTTP library or an upstream engine numerous packages, such as a frontend, depend upon.
When remediation HTTP request smuggling issues, RFC 7230 #3.3.3 should be followed. Section 3.3.3#3in RFC 7230 states:
“If a message is received with both a Transfer-Encoding and a Content-Length header field, the Transfer-Encoding overrides the Content-Length. Such a message might indicate an attempt to perform request smuggling (Section 9.5) or response splitting (Section 9.4) and ought to be handled as an error. A sender MUST remove the received Content-Length field prior to forwarding such a message downstream.”
However, this is different from what is stated within RFC 2616 4.4#3:
“If a message is received with both a Transfer-Encoding header field and a Content-Length header field, the latter MUST be ignored.”
It should be noted that RFC 2616 4.4#3 is obsolete and has been replaced by RFC 7230. RFC 7230 should be taken into consideration when implementing a fix. As such, when processing HTTP requests with both a Content-Length and Transfer encoding header, the correct behavior here is that the frontend should strip out the Content-length header before forwarding the request to a downstream backend, not return an HTTP 400 response header. The same should be done to requests with multiple Content-Length headers as stated in RFC 7230#3.3.2.
As mentioned in RFC 7230 Section 3.3.2, if an HTTP request is received with multiple Content-Length headers with different length values, this can be remediated with an HTTP 400 response, or the duplicated field-values should be replaced with a single valid Content-Length field. Snyk recommends that low-level HTTP libraries opt to replace multiple headers with a single valid header.
Disallow malformed Transfer-Encoding headers and correct Processing of Multiple TE valuesRemediation:This remediation will prevent TE:TE attacks.Scope: Frontend, BackendDetails:If both a frontend and backend prioritizes the Transfer-Encoding header, it could allow smuggling attacks where an attacker inserts two Transfer-Encoding headers, one which would be ignored by the frontend and is processed by the backend and vice versa. As such, the following type of header variations should be rejected.
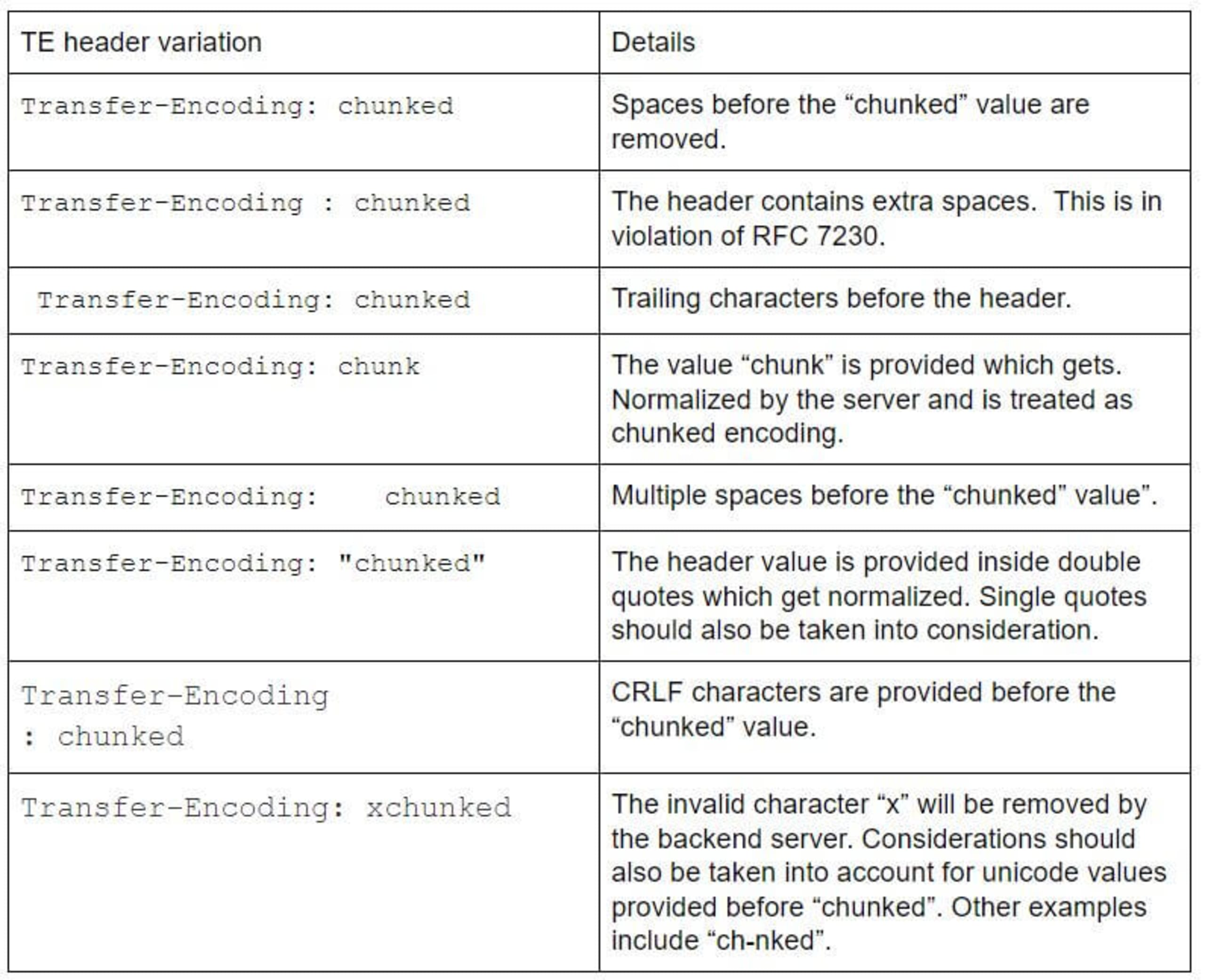
However, it should be noted that it’s still possible for attackers to find a malformed header variation of “chunked” encoding that is not documented above. As such, this alone should not be taken into account for remediation. A better approach would be to disallow requests with both Content-Length and Transfer-Encoding, along with disallowing malformed headers.
Lastly, It should also be noted that if the “chunked” value is specified with other Transfer-Encoding values such as “gzip” or “deflate”, it shouldn’t be overlooked and Transfer-Encoding should be prioritized over Content-Length. An example of this vulnerability occurring can be seen in CVE-2019-16786. If an HTTP request is sent with the following Transfer-Encoding values, the “chunked” value should be correctly identified and prioritized:
Transfer-Encoding: gzip, chunked
Within a Transfer-Encoding header, several values can be listed separated by a comma. However, there might be cases where a frontend might only identify the “gzip” value and as such will prioritize the Content-Length header, and the backend might process this as a chunked request resulting in a CL:TE attack. Snyk recommends, whenever multiple values are specified that they are checked correctly and, if “chunked” is specified, then Transfer-Encoding be prioritized. Furthermore, if multiple transfer encoding headers are specified, the “chunked” value should only be present as the last value after other transfer encoding values are specified. This is stated in RFC 7230 Section 3.3.1.
Wrapping up
To conclude, HTTP request smuggling can be a confusing vulnerability to understand and patch against. This blog hopes to help maintainers write efficient patches and secure their open source projects.
It is also worth noting that this blog post only covers two techniques of HTTP request smuggling and does not provide detailed information regarding different exploitation scenarios. The following article from Security researcher ZeddYu has covered HTTP request smuggling extensively and has provided in-depth details regarding each attack smuggling vector: Zeddy Yu: Help you understand HTTP Smuggling in one article.
Beginnen Sie mit Capture the Flag
Lernen Sie, wie Sie Capture the Flag-Herausforderungen lösen, indem Sie sich unseren virtuellen 101-Workshop auf Abruf ansehen.