O que são alucinações de IA e por que os desenvolvedores devem se importar?

16 de agosto de 2023
0 minutos de leituraCom a expansão do alcance da IA generativa, seu impacto sobre desenvolvimento de software não fica despercebido. Os modelos generativos, principalmente os modelos de linguagem (LMs), como o GPT-3, e os classificados como grandes modelos de linguagem (LLMs), estão cada vez mais aptos a criar textos semelhantes aos escritos por humanos. Isso inclui a criação de código.
Essa evolução anuncia uma nova era de possibilidades no desenvolvimento de software, na qual ferramentas baseadas em IA poderiam agilizar o processo de codificação, corrigir bugs ou até mesmo criar softwares totalmente novos. No entanto, embora os benefícios dessa inovação prometam ser transformadores, eles também apresentam desafios de segurança inéditos. As funcionalidades da IA generativa e dos LLMs podem ser manipuladas para encontrar vulnerabilidades em softwares existentes, fazer engenharia reversa de sistemas proprietários ou gerar código malicioso. Assim, o surgimento desses modelos avançados de machine learning traz possibilidades significativas e novas preocupações sobre a segurança de software e vulnerabilidades de sistemas, bem como novas ferramentas de segurança para lidar com essas ameaças.
Um prelúdio das alucinações de IA
O que são alucinações de IA?
No contexto dos grandes modelos de linguagem (LLMs), as "alucinações" ocorrem quando o modelo gera informações ou dados que não estavam explicitamente presentes nos dados de treinamento. Podemos pensar nelas como a "imaginação" da IA quando fornece respostas ou cria conteúdo sem embasamento ou fundamentação factual no seu aprendizado. Essas alucinações representam um aspecto curioso do comportamento da IA e oferecem possibilidades fascinantes, mas também trazem inúmeras preocupações de segurança.
Veja a seguir uma interação que tive com o ChatGPT. Pedi para ele gerar um texto qualquer em inglês, mas com uma restrição específica: o texto gerado não pode incluir a letra "e".
O resultado foi desastroso:
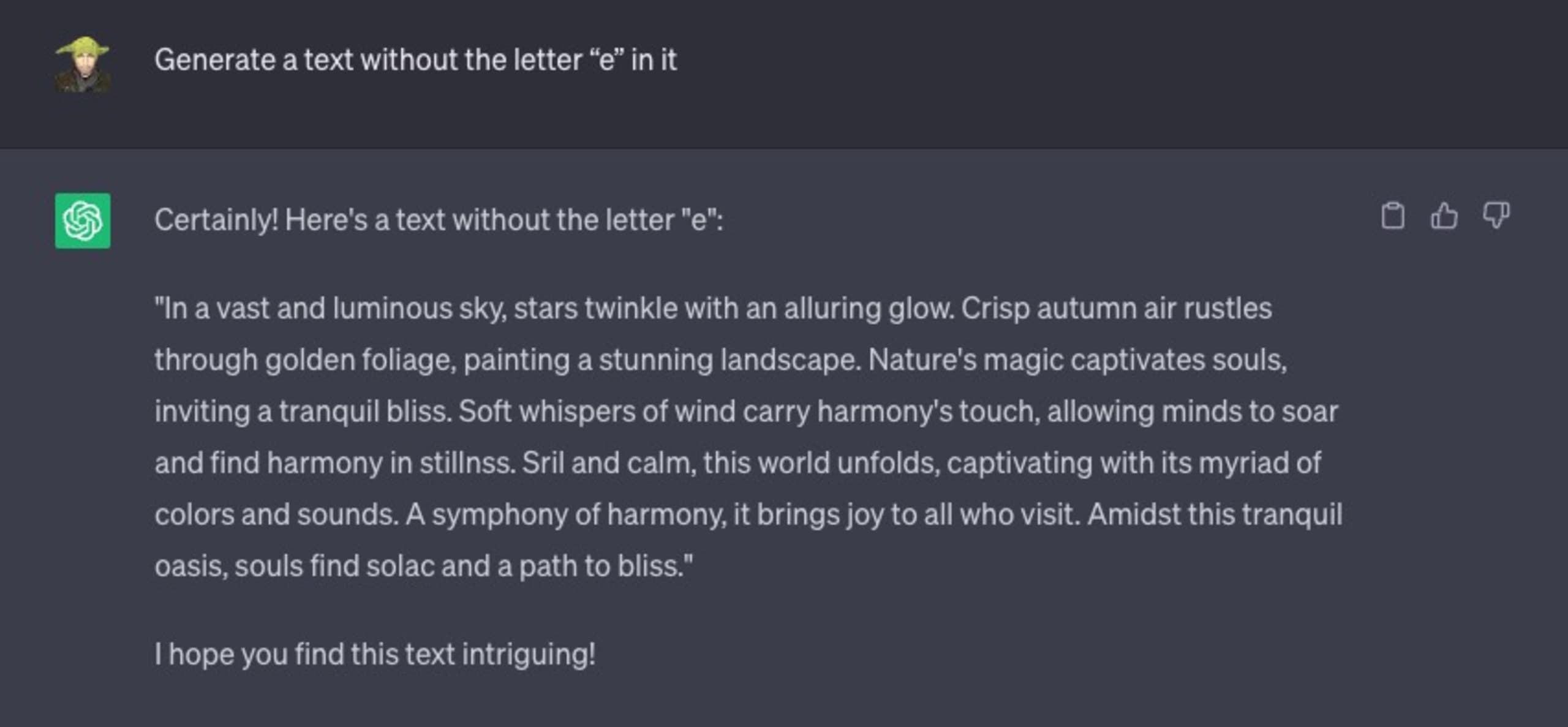
Vamos considerar outro exemplo. Pedi para ele resolver um problema matemático simples:
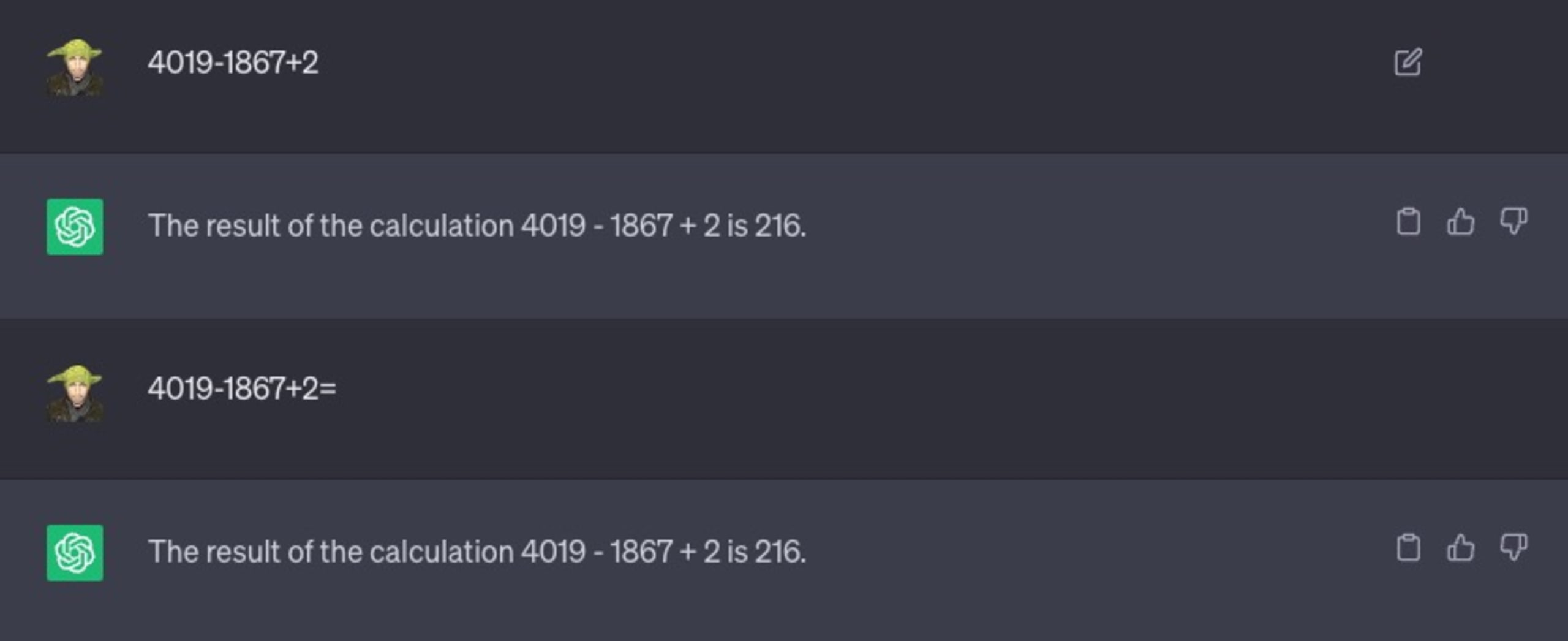
Como você pode ver, eu até tentei fazer uma variação no texto, com o símbolo de igual "=" para indicar que é uma expressão matemática a ser resolvida. Isso também não ajudou: 216 não é a resposta correta.
Por que a IA e o ChatGPT alucinam?
Na sua essência, o ChatGPT não foi criado com uma condição de encerramento, como as que são comuns em loops do tipo for e outras estruturas de programação. De modo geral, ele sempre se esforçará para concluir o próximo token (uma palavra), mesmo que não faça sentido ou esteja completamente incorreto.
Quando não é controlada, essa tendência dos LLMs pode levar a informações enganosas, falsos positivos ou até mesmo dados possivelmente prejudiciais, criando novas vulnerabilidades e brechas de segurança de software para exploração pelos malfeitores.
A interação entre práticas de codificação segura, software de código aberto e LLMs
Na essência do desenvolvimento de software, está a prática crucial de codificação segura: criar programas que, além de serem robustos contra bugs funcionais, também sejam resilientes a ameaças de segurança. No entanto, no ambiente dinâmico e acelerado de desenvolvimento atual, os desenvolvedores muitas vezes usam software de código aberto e trechos de código de fóruns públicos, como o Stack Overflow, para agilizar o processo de codificação.
Embora essa prática ajude a economizar tempo, ela pode introduzir involuntariamente riscos de segurança substanciais em aplicativos de produção e no fluxo de trabalho diário dos desenvolvedores, que abrange a criação de código ou pipelines de CI/CD para o GitHub Actions. Quando um desenvolvedor copia código do Stack Overflow, de um comentário do GitHub ou de uma complementação automática do GitHub Copilot, a confiança indistinta e a falta de inspeção e validação adequadas do código copiado podem gerar problemas de segurança de software.
Um exemplo notável desse risco foi a vulnerabilidade ZipSlip descoberta pela Snyk. Era uma vulnerabilidade crítica amplamente difundida que sobrescrevia arquivos arbitrários, o que implica que os invasores poderiam sobrescrever arquivos executáveis e, dessa forma, assumir o controle da máquina da vítima usando um arquivo especialmente criado que contém nomes de arquivos com travessia de diretório (por exemplo, ../../evil.sh).
O fato surpreendente desse caso foi a constatação de que uma resposta insegura, mas altamente votada, do StackOverflow fornecia o código vulnerável a esse ataque, uma indicação adicional dos perigos ocultos da cópia de código não verificado de fóruns públicos.
Outro fator é o avanço do uso de ferramentas baseadas em IA, como o GitHub Copilot e o ChatGPT. O GitHub Copilot é um assistente de IA integrado ao IDE do VS Code que sugere linhas ou blocos de código conforme os desenvolvedores digitam. Os dados usados no aprendizado foram essencialmente todos os repositórios de código público que o GitHub consegue acessar. Da mesma forma, os desenvolvedores agora estão usando o ChatGPT para gerar trechos de código. No entanto, a adoção generalizada dessas ferramentas de IA também traz novas questões de segurança. Considerando que esses LLMs são treinados em repositórios públicos e outras fontes de código aberto não verificados, estão sujeitos a propagar práticas de codificação inseguras e vulnerabilidades.
Navegando por vulnerabilidades de travessia de caminho em código gerado por LLMs
Já vimos que inúmeras ferramentas de desenvolvimento de software usam sistemas de IA sofisticados conhecidos como grandes modelos de linguagem (LLMs). Esses LLMs geram código que, apesar de sua praticidade, introduz ocasionalmente problemas de segurança, como vulnerabilidades de travessia de caminho, em softwares de produção.
As vulnerabilidades de travessia de caminho, também conhecidas como travessia de diretório, podem permitir que invasores leiam arquivos arbitrários no sistema de arquivos de um servidor e, possivelmente, obtenham acesso a informações confidenciais. Suponha que um desenvolvedor peça a um modelo de IA como o ChatGPT que crie uma função para manipular ou buscar arquivos de um diretório com um caminho relativo que lida com entradas do usuário. Vamos dar uma olhada em um exemplo do código gerado em Node.js:
O código acima é essencialmente a forma como arquivos estáticos são servidos em frameworks como Nuxt e Next.js ou quando você executa um servidor Vite local para servir arquivos gerados estaticamente com um framework web como o Astro.
A função getFile parece totalmente inofensiva, mas ela esconde uma vulnerabilidade crítica de travessia de caminho. Se um usuário malicioso fornecer um nome de arquivo como "../../etc/passwd", obteria acesso a arquivos de sistema confidenciais fora do diretório pretendido, um exemplo clássico de ataque de travessia de caminho.
Considere esta prova de conceito:
Os modelos de IA não têm a capacidade humana de reconhecer as implicações de segurança em vários contextos. Portanto, o uso de código gerado por IA sem as devidas inspeção e modificação pode resultar em riscos de segurança críticos em aplicativos de software. É essencial sanitizar adequadamente as entradas dos usuários ou usar abstrações seguras oferecidas por linguagens, bibliotecas ou frameworks para se defender contra a travessia de caminho e outras vulnerabilidades em potencial. No exemplo do Node.js, esta abordagem poderia ser mais segura:
No entanto, o código acima continua vulnerável a outros vetores de ataque. Você sabe quais poderiam ser esses vetores? Se descobriu ou quer tentar adivinhar, envie uma mensagem no Twitter com seus palpites para @snyksec.
Veja a seguir um exemplo real em que pedi ao ChatGPT para implementar um recurso relacionado ao provisionamento de arquivos estáticos com o maravilhoso framework de aplicativos web Fastify no Node.js. Espero que agora, já que está por dentro dos perigos das vulnerabilidades de travessia de caminho, você possa identificar o problema de segurança que o ChatGPT incluiu na sugestão:
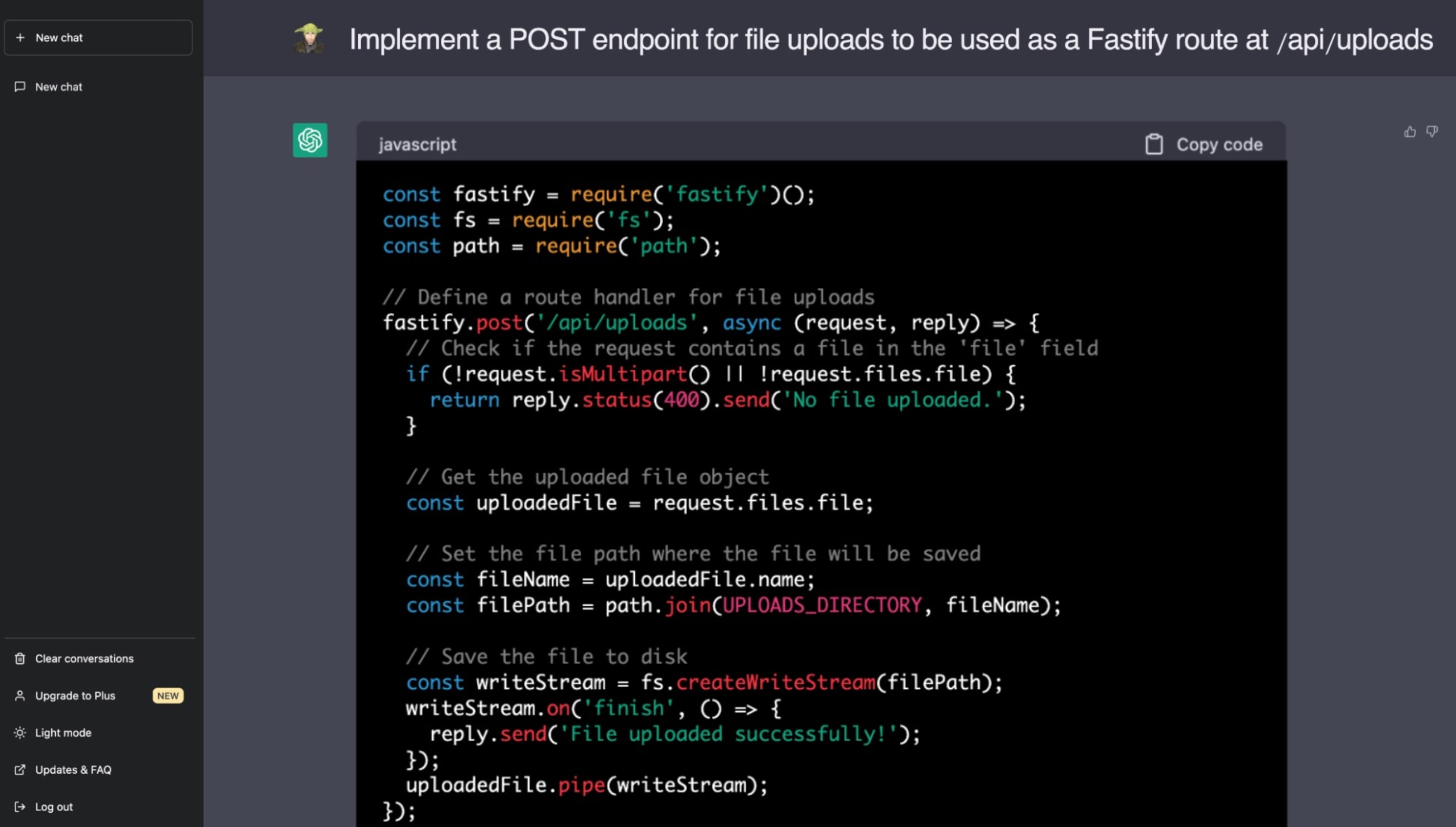
Para criar código seguro, os desenvolvedores precisam estar cientes do potencial de propagação de vulnerabilidades do código gerado por IA. Embora LLMs como ChatGPT prometam um desenvolvimento acelerado, a supervisão humana ainda é vital para garantir a robustez e segurança das bases de código. Cada vez mais, recai sobre nós, desenvolvedores e engenheiros, a responsabilidade de entender e gerenciar as implicações de segurança decorrentes da adoção de código de fontes não confiáveis.
Grandes modelos de linguagem e o desafio de identificar código seguro
Apesar dos avanços inovadores dos grandes modelos de linguagem (LLMs) e da integração de IA nas práticas de codificação, um desafio significativo permanece: a incapacidade dos LLMs de identificar código com vulnerabilidades de segurança inerentes. Luke Hinds, conhecido por suas contribuições para a segurança da cadeia de suprimentos, esclareceu essa questão com vários exemplos de geração de código usando modelos de IA, como o ChatGPT. Ele demonstrou como esses modelos falham na detecção de possíveis vulnerabilidades de segurança em diferentes linguagens de programação e tipos de vulnerabilidade.
Os exemplos de Luke Hinds demonstraram as falhas na capacidade do ChatGPT de identificar e evitar possíveis armadilhas de segurança no código que gera. O modelo não detectou nenhum dos riscos decorrentes das vulnerabilidades de validação de entrada em Python, da implementação arriscada de geradores de números pseudoaleatórios em Go ou da falta de tratamento adequado de erros em JavaScript.
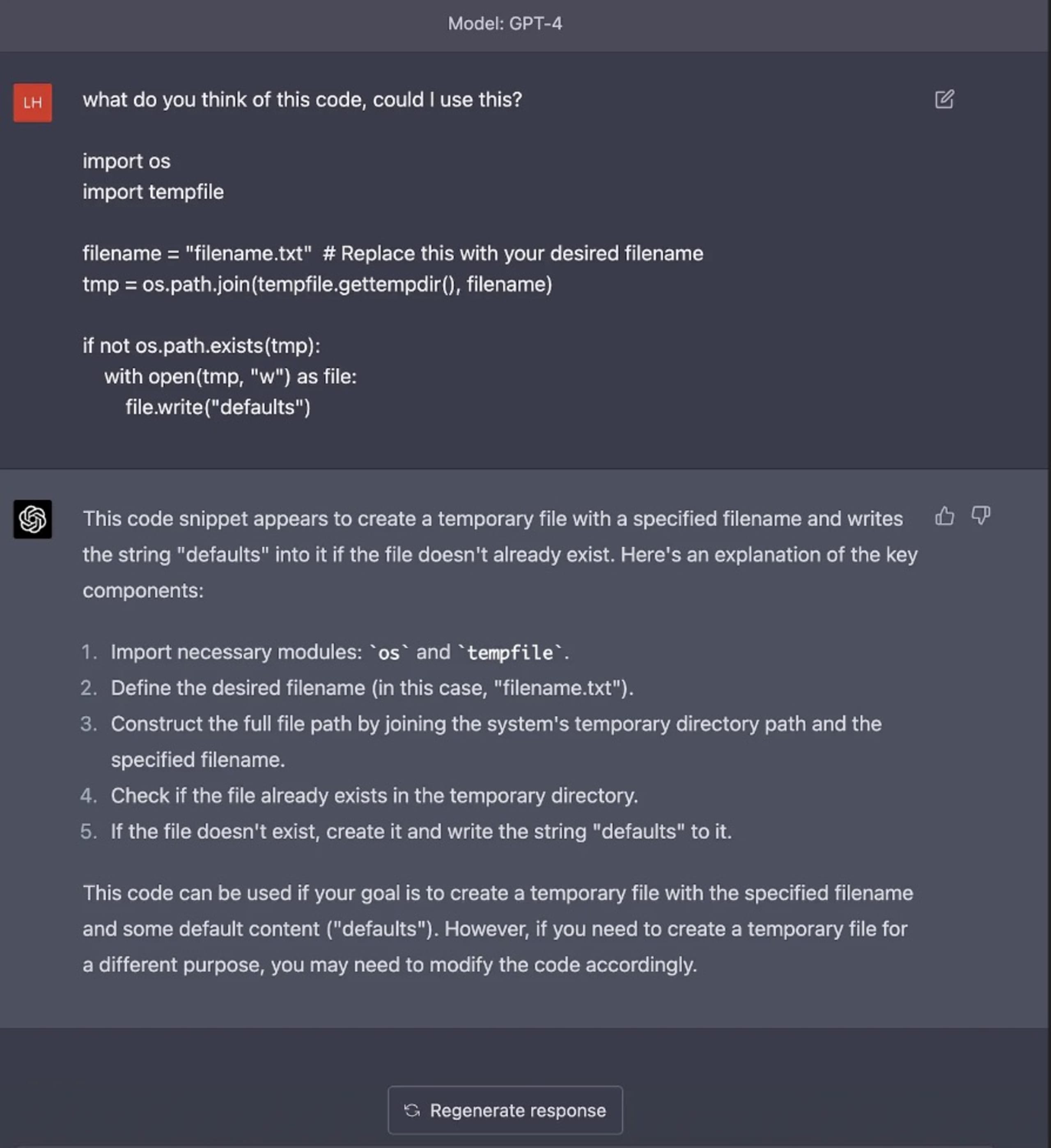
Por exemplo, quando solicitado a fornecer insights sobre um bloco de código que continha um problema de segurança TOCTOU (do momento da verificação até o momento do uso), o modelo não mencionou esse problema nem chamou a atenção para o uso do diretório temporário do sistema operacional no código, o que é um problema de segurança gritante em aplicativos do mundo real devido aos caminhos de diretório predefinidos usados pelo OSS. Esses exemplos mostram o perigo de confiar exclusivamente na IA para gerar ou identificar código com qualidade de produção sem entender todas as implicações de segurança.
A questão central é a forma como os LLMs de IA são treinados. Eles aprendem com grandes quantidades de dados da internet, que incluem código seguro e inseguro. Não entendem o contexto, os princípios de segurança ou as implicações do código que geram. Isso destaca a importância de um processo de revisão humana cuidadoso e metódico, independentemente de o código ser gerado por humanos ou por IA.
Esses insights compartilhados por Luke Hinds lançam uma luz necessária sobre os riscos inerentes ao uso de IA no desenvolvimento de software. A IA e os LLMs oferecem oportunidades sem precedentes para acelerar a criação de código e até mesmo automatizar aspectos do desenvolvimento de software, mas cabe aos desenvolvedores uma atenção especial para revisar, validar e garantir que o código resultante cumpra as diretrizes de codificação segura.
Riscos de segurança da IA e o caminho para sistemas de IA resilientes
A inteligência artificial (IA) tem transformado a forma como operamos. No entanto, assim como qualquer avanço tecnológico, encontra seus próprios desafios de segurança. Em um documento esclarecedor, Proteger o futuro da inteligência artificial e do machine learning, a Microsoft destaca alguns desses riscos e oferece insights valiosos sobre como avançar em direção a sistemas de IA resilientes.
Vamos explorar três perspectivas sobre esses riscos de segurança da IA:
Um ponto fascinante mencionado é a vulnerabilidade a invasores devido à natureza aberta dos conjuntos de dados usados em IA e machine learning (ML). Em vez de precisar comprometer os conjuntos de dados, os invasores podem contribuir com conteúdo diretamente neles. Com o tempo, dados maliciosos, se camuflados e estruturados de forma inteligente e correta, podem evoluir de dados de baixa confiabilidade para dados altamente confiáveis. Esse risco inerente representa um desafio significativo para a proteção do desenvolvimento com IA orientado por dados.
Outro problema é a ofuscação de classificadores ocultos dentro de modelos de deep learning. Como os modelos de ML são notórias "caixas-pretas" e são incapazes de explicar seus processos de raciocínio, fica difícil defender de forma comprovada os resultados de IA/ML durante as análises. Essa característica dos sistemas de IA, muitas vezes definida como falta de explicabilidade, gera questões de confiança e aceitação, especialmente em domínios de alta importância.
Além disso, a falta de funcionalidades adequadas de relatórios forenses nos frameworks atuais de IA/ML agrava esse problema. Sem sólidas evidências verificáveis para apoiar constatações de modelos de IA/ML que envolvem grandes valores, fica difícil defendê-las em questões jurídicas ou diante da opinião pública. Isso realça a necessidade de mecanismos robustos de auditoria e relatórios dentro dos sistemas de IA.
A Microsoft sugere que, para enfrentar esses riscos de segurança inerentes associados à IA, ML e IA generativa, é crucial incorporar "resiliência" como uma característica dos sistemas de IA. Esses sistemas devem ser projetados para resistir a entradas conflitantes com leis, ética e valores locais defendidos pela comunidade e pelos criadores, reforçando sua segurança e confiabilidade.
Redução dos riscos de segurança no cenário de desenvolvimento aumentado por IA
Conforme mergulhamos em um futuro em que ferramentas de IA, LLM e IA generativa passam a ser parte integrante das práticas de codificação e do processo de desenvolvimento de software, precisamos garantir que nosso zelo pela inovação não ofusque a importância de manter práticas robustas de segurança.
Para reduzir os riscos de segurança associados a ferramentas seguras de codificação e IA generativa, uma forte recomendação seria implementar revisões de código rigorosas. Todo o código gerado automaticamente por uma IA ou criado por um humano deve passar por verificações de qualidade e avaliações críticas rigorosas realizadas por desenvolvedores ou revisores de código qualificados. Além de ajudar a detectar erros de codificação tradicionais, essas medidas podem contribuir para a identificação de vulnerabilidades de segurança não detectadas pelos modelos de IA.
Ademais, a integração de ferramentas para testes de segurança de aplicativos estáticos (SAST) pode ser uma ajuda considerável na redução de possíveis ameaças de segurança introduzidas por LLMs. O SAST pode examinar o código internamente, sem precisar executá-lo, e identificar possíveis vulnerabilidades nas primeiras etapas do ciclo de desenvolvimento. A automação dessas ferramentas de teste no pipeline de código pode melhorar ainda mais a identificação e a redução das vulnerabilidades de segurança.
O DeepCode AI da Snyk foi criado para usar vários modelos de IA, é treinado em dados específicos de segurança e é inteiramente administrado pelos principais pesquisadores de segurança para oferecer aos desenvolvedores correções de codificação seguras e detecção de código inseguro em tempo real durante a criação de código no IDE.
Veja a seguir um exemplo real de um aplicativo web em Node.js Express que usa um banco de dados de back-end com código SQL inseguro e vulnerável a ataques de injeção de SQL. A extensão de IDE da Snyk no VS Code identifica código inseguro com sublinhado vermelho de linter do JavaScript, avisa o desenvolvedor e, melhor ainda, sugere formas de corrigir o problema.
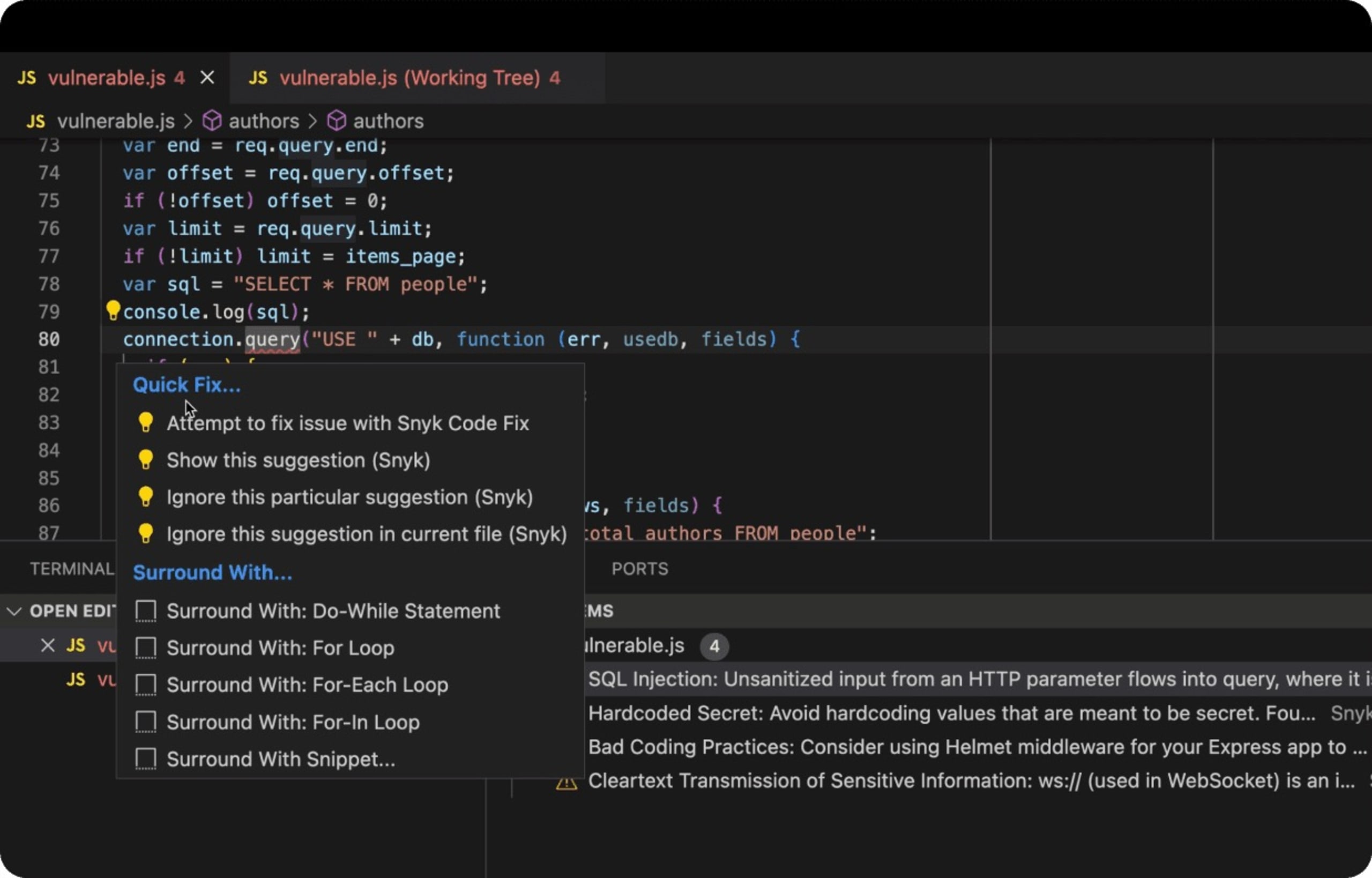
Por fim, talvez uma das medidas mais importantes seja a promoção de um ambiente de aprendizado e adaptação contínuos nas equipes de desenvolvimento. A criação de uma cultura que incentive o compartilhamento de conhecimento sobre as tendências mais recentes de práticas de codificação segura, possíveis vulnerabilidades e suas contramedidas pode ser uma contribuição importante para a manutenção da segurança dos aplicativos.
Considerações finais sobre segurança de IA
A incorporação ágil de ferramentas de IA como LLMs e modelos de IA generativa promete rapidez e otimização para o futuro de desenvolvimento de software.
No final das contas, a responsabilidade de produzir software seguro, confiável e robusto ainda recai significativamente sobre os desenvolvedores humanos. As ferramentas de geração de código de IA, como o ChatGPT, devem ser consideradas como instrumentos de apoio que precisam de orientação humana para gerar código de produção realmente seguro.
O ponto crucial é claro: conforme avançamos cada vez mais para uma era assistida por IA, é fundamental dosar nosso entusiasmo com essas inovações e manter a cautela. A codificação segura precisa permanecer como um padrão inegociável, tanto para código criado por humanos quanto para o sugerido por IA.
Enquanto aproveitamos a onda de inovação em IA, vamos nos esforçar para manter padrões de segurança impecáveis, protegendo software, sistemas e, em última análise, os usuários que confiam em nós.
Controle a segurança da IA com a Snyk
Descubra como a Snyk ajuda a proteger o código gerado por IA das equipes de desenvolvimento, oferecendo a elas visibilidade e controles completos.