Hallucinations des IA : de quoi s’agit-il et pourquoi les développeurs doivent-ils s’en méfier ?

16 août 2023
0 minutes de lectureL’IA générative envahit de plus en plus de domaines, et le développement logiciel ne fait pas exception à la règle. Les modèles génératifs, et en particulier les modèles de langage, comme GPT-3, et les grands modèles de langage, sont de plus en plus doués pour produire du texte semblant être écrit par des êtres humains. Ces capacités rédactionnelles concernent aussi le codage.
Cette évolution annonce une nouvelle ère dans le monde du développement logiciel,un monde dans lequel l’IA pourrait simplifier le processus de codage, corriger les bugs et peut-être même créer des logiciels de A à Z. Mais si cette innovation présage des bouleversements positifs, elle fait également apparaître des défis de sécurité inédits. En effet, l’IA générative et les LLM pourraient être utilisés pour détecter des vulnérabilités dans des logiciels, faire l’ingénierie inverse de systèmes propriétaires ou générer du code malveillant. Par conséquent, l’avènement de ces modèles de machine learning de pointe pourrait poser de nouveaux problèmes en matière de sécurité des logiciels, de nouvelles vulnérabilités dans les systèmes, mais aussi de nouveaux outils de sécurité pour faire face à ces menaces.
Introduction aux hallucinations de l’IA
Que sont les hallucinations des intelligences artificielles ?
Dans le contexte des grands modèles de langage, les hallucinations sont des informations générées par les modèles alors qu’elles n’étaient pas explicitement présentes dans les données à partir desquelles il a été entraîné. On peut dire que l’IA « s’imagine » des choses et propose des réponses ou crée du contenu sans base factuelle ou sans rapport avec les connaissances qu’elle a acquises. Côté pile, ces hallucinations sont intrigantes et offrent des possibilités fascinantes. Côté face, elles génèrent de nombreux problèmes de sécurité.
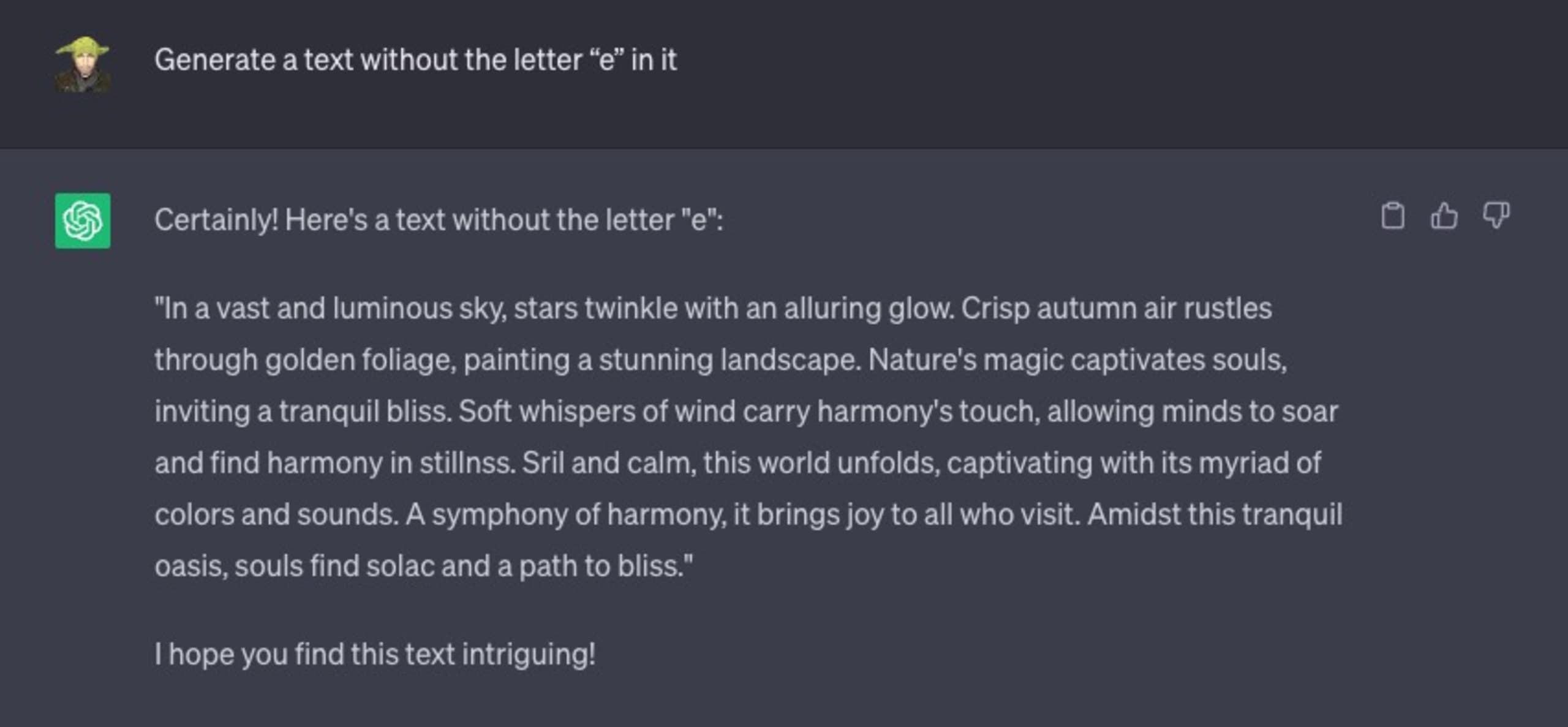
Regardez cette interaction avec ChatGPT, où je lui demande de générer le texte de son choix, mais avec une contrainte : il ne doit pas contenir la lettre « e ».
L’échec est total :
Prenons un autre exemple. J’ai demandé à ChatGPT de résoudre un problème mathématique ne posant pas de difficulté particulière :
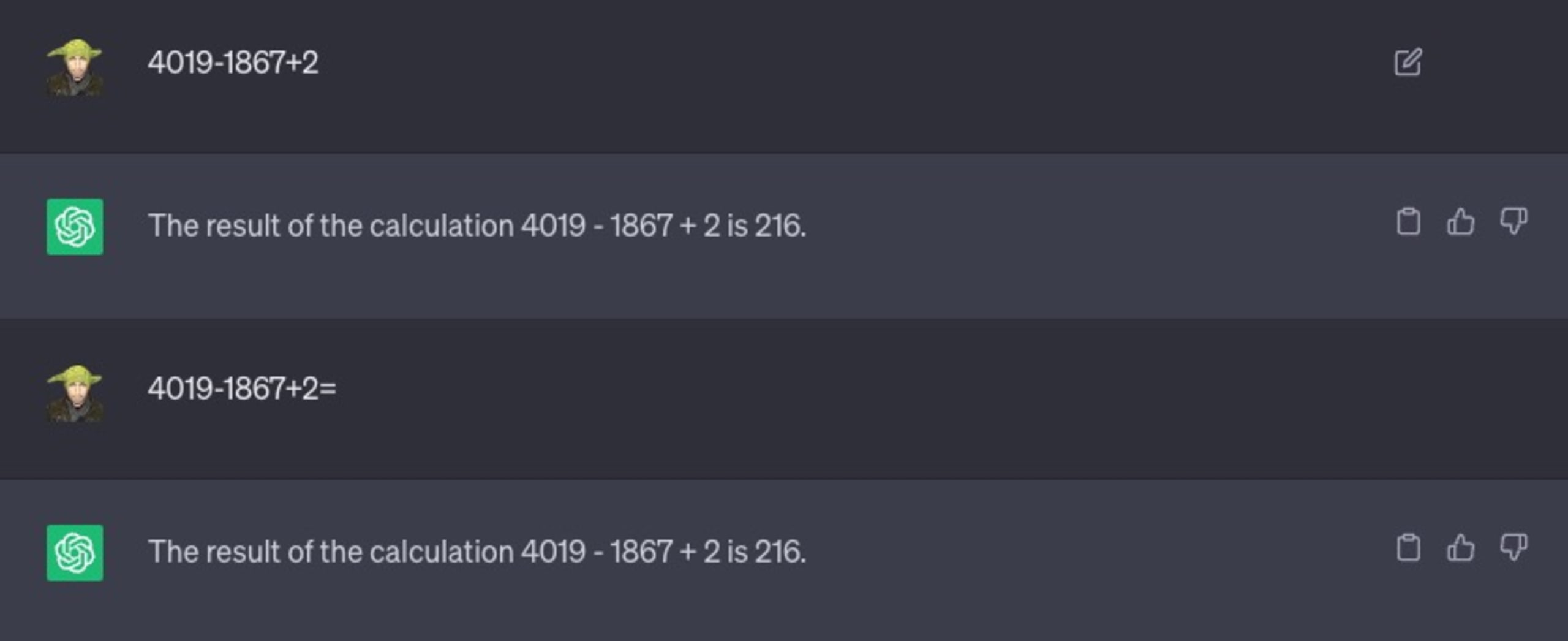
Comme vous le voyez, j’ai pourtant essayé une variante avec le symbole « = » pour l’aider à comprendre qu’il s’agissait d’une opération mathématique. Rien n’y a fait, 216 n’est toujours pas la bonne réponse.
Pourquoi l’IA et ChatGPT hallucinent-ils ?
ChatGPT n’intègre aucune condition d’arrêt comme peut en avoir une boucle basée sur l’opérateur for. Sans entrer dans le détail, on peut dire qu’il essaiera toujours de générer le jeton suivant (un mot), même s’il ne veut rien dire ou est totalement incorrect.
Si elle n’est pas prise à bras le corps, cette tendance des LLM pourrait générer des informations trompeuses, des faux positifs ou même des données potentiellement dangereuses, et créer de nouvelles vulnérabilités logicielles ou failles de sécurité que les acteurs malveillants n’auront plus qu’à exploiter.
Lien entre pratiques de codage sécurisées, logiciels open source et LLM
Le code sécurisé joue un rôle clé dans le développement logiciel. Il permet d’écrire des programmes sans bugs fonctionnels, mais aussi résistants face aux menaces. Toutefois, l’environnement de développement est désormais dynamique, et les développeurs ont souvent recours à des logiciels open source et des extraits de code issus de forums publics comme StackOverflow pour accélérer la cadence.
Bien que cette pratique leur fasse gagner du temps, elle peut introduire de sérieux risques de sécurité dans les applications en production et dans les tâches de développement du quotidien, comme l’écriture de code ou la création de workflows de build pour GitHub Actions. Lorsqu’un développeur copie du code provenant de StackOverflow, d’un commentaire GitHub ou d’une suggestion de GitHub Copilot, il risque d’introduire des problèmes de sécurité dans son logiciel s’il fait une confiance aveugle à ce code et omet de le vérifier et valider correctement.
C’est par exemple ce qu’il s’est passé pour la vulnérabilité ZipSlip découverte par Snyk. Cette vulnérabilité critique permettait l’écrasement arbitraire d’un fichier. Des attaquants pouvaient ainsi écraser des fichiers exécutables et donc prendre le contrôle de la machine de leur victime à l’aide d’une archive dédiée contenant des noms de fichier permettant la traversée de répertoire (par ex. ../../evil.sh).
Si cette histoire a fait réagir, c’est que le code défaillant provient d’une réponse de StackOverflow pourtant très bien notée. Elle montre ainsi les dangers cachés de la copie de code issu de forums publics.
Le recours aux outils basés sur l’IA, comme GitHub Copilot et ChatGPT, vient encore complexifier la situation. GitHub Copilot est un assistant d’IA intégré à l’IDE VS Code. Il suggère des lignes ou des blocs de code pendant que le développeur saisit son texte. Cet assistant a été entraîné sur tous les dépôts de code publics auxquels GitHub a accès. De même, les développeurs utilisent désormais ChatGPT pour générer des extraits de code. Toutefois, l’adoption massive de ces outils d’IA soulève de nouvelles questions en matière de sécurité. Ces LLM sont entraînés sur des dépôts publics et d’autres codes open source non vérifiés, et peuvent donc propager des pratiques de codage potentiellement non sécurisées, voire des vulnérabilités.
Vulnérabilités de traversée de répertoire dans le code généré par les LLM
Nous avons vu que de nombreux outils de développement logiciel s’appuient sur des systèmes d’IA sophistiqués appelés grands modèles de langage (LLM). Ces LLM génèrent du code qui, bien que pratique, peut introduire des problèmes de sécurité dans les logiciels en production, notamment des vulnérabilités de traversée de répertoire.
Ces vulnérabilités permettent aux attaquants de lire des fichiers arbitraires sur un serveur et donc de potentiellement accéder à des informations sensibles. Imaginons qu’un développeur demande à un modèle d’IA comme ChatGPT de créer une fonction permettant de manipuler ou récupérer des fichiers depuis un répertoire disposant d’un chemin relatif et en gérant la saisie utilisateur. Voyons un exemple de code généré pour Node.js :
Le code ci-dessus reprend la gestion des fichiers statiques dans des frameworks comme Nuxt et Next.js ou des fichiers générés de manière statique depuis un serveur Vite local avec un framework Web comme Astro.
La fonction getFile ci-dessus peut paraître totalement inoffensive, mais elle abrite en réalité une vulnérabilité de traversée de répertoire. En effet, si un utilisateur malveillant fournit un nom de fichier comme '../../etc/passwd', elle lui permettrait d’accéder à des fichiers système sensibles situés en-dehors du répertoire prévu – un exemple type de traversée de répertoire.
Voici une preuve de concept :
Les modèles d’IA, à la différence des humains, ne sont pas capables d’évaluer les conséquences sécuritaires en fonction du contexte. Par conséquent, l’utilisation de code généré par l’IA sans examen approfondi et modification peut introduire des risques de sécurité critiques dans vos applications logicielles. Il est essentiel de nettoyer les saisies utilisateur correctement ou d’utiliser des abstractions sûres proposées par le langage, les bibliothèques ou les frameworks concernés pour se protéger des traversées de répertoire et d’autres vulnérabilités. Dans le cas de notre exemple avec Node.js, l’approche suivante serait par exemple plus sûre :
Pour autant, ce code reste vulnérable à d’autres vecteurs d’attaque. Savez-vous lesquels ? Si vous avez deviné ou voulez tenter votre chance, n’hésitez pas à nous faire part de vos idées sur notre compte Twitter @snyksec.
Voici un exemple concret, dans lequel j’ai demandé à ChatGPT d’implémenter une fonctionnalité de distribution de fichiers statiques avec le génial framework d’application Web Fastify de Node.js. Désormais, vous connaissez les dangers des vulnérabilités de traversée de répertoire et saurez donc repérer le problème de la suggestion de ChatGPT :
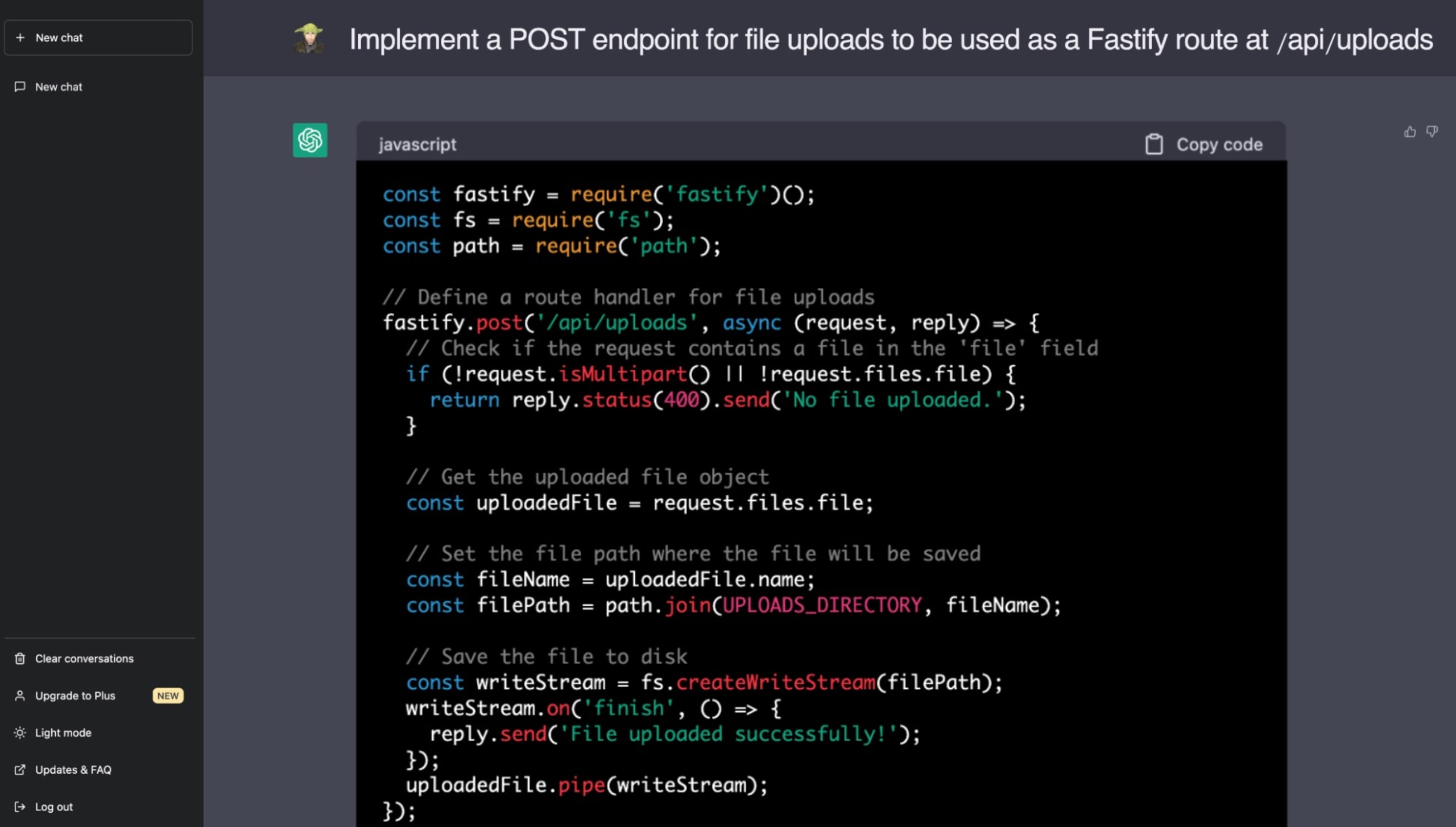
Pour écrire du code sécurisé, les développeurs doivent avoir conscience que le code généré par l’IA peut propager des vulnérabilités. Les LLM comme ChatGPT promettent d’accélérer le développement, mais une supervision humaine reste indispensable pour assurer la viabilité et la sécurité des bases de code. De plus en plus, il nous revient à nous, développeurs et ingénieurs, de comprendre et de gérer les implications de sécurité liées à l’intégration de code ne provenant pas de sources de confiance.
La difficulté des grands modèles à déterminer si du code est sécurisé
En dépit des progrès incroyables des grands modèles de langage et de l’intégration de l’IA dans les habitudes de codage, un problème important reste sans réponse : l’incapacité des LLM à repérer les vulnérabilités inhérentes au code. Luke Hinds, connu pour ses contributions à la sécurité de la chaîne d’approvisionnement, a mis en lumière ce problème avec différents exemples de code générés par des modèles d’IA comme ChatGPT. Il a ainsi montré que ces modèles ne repèrent pas les vulnérabilités potentielles des différents langages et n’en connaissent pas les différents types.
Ses exemples ont prouvé que ChatGPT est incapable d’identifier et d’éviter divers pièges dans ses suggestions de code. Qu’il s’agisse de vulnérabilités dans la validation des saisies en Python, d’une implémentation risquée de générateurs de nombre pseudo-aléatoires en Go ou de l’absence de toute gestion appropriée des erreurs en JavaScript, le modèle n’a jamais tiqué.
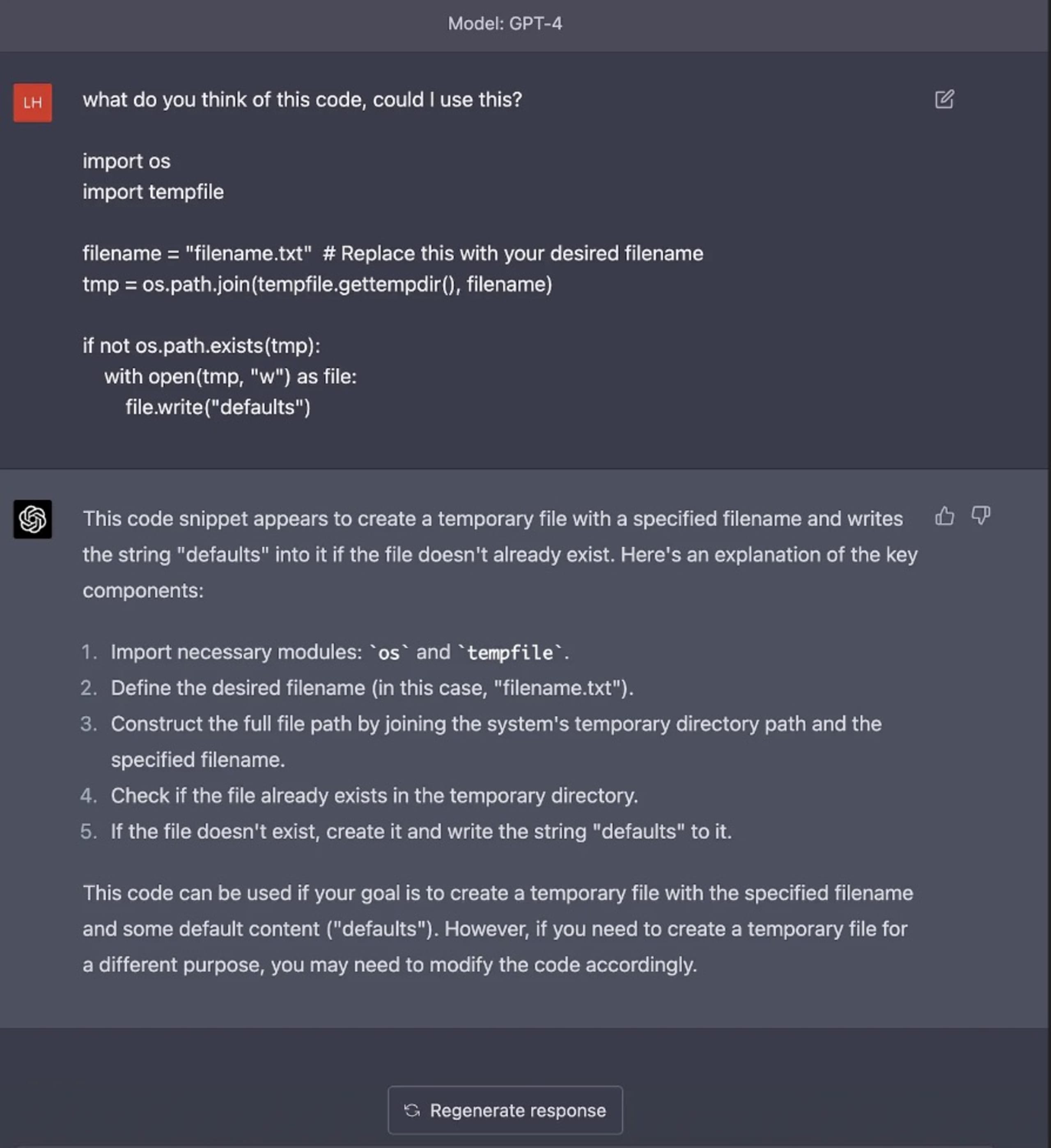
Par exemple, lorsque nous avons demandé une explication sur un bloc de code présentant une vulnérabilité TOCTOU (time-of-check time-of-use), l’IA n’a pas mentionné ce problème, ni évoqué l’utilisation du répertoire temporaire du système d’exploitation dans le code, un problème de sécurité pourtant évident dans une application en production, car ces répertoires se trouvent à des emplacements prédéfinis. Ces exemples montrent bien le risque de s’appuyer exclusivement sur l’IA pour générer ou identifier du code pouvant être mis en production sans en comprendre toutes les implications en matière de sécurité.
Le cœur du problème vient de la méthode d’entraînement des LLM. En effet, ils apprennent de vastes volumes de données tirées d’Internet, qui incluent à la fois du code sécurisé et du code qui ne l’est pas. Ils ne comprennent pas le contexte, les principes de sécurité ou les implications du code qu’ils génèrent. Ce phénomène souligne l’importance de mettre en place un processus de revue humaine minutieux et méthodique pour l’ensemble du code, qu’il soit écrit par un être humain ou généré par une IA.
Les expérimentations de Luke Hinds montrent bien les risques inhérents à l’utilisation de l’IA dans le développement logiciel. Certes, l’IA et les LLM offrent un moyen inédit d’accélérer le codage et même d’automatiser certains aspects du développement logiciel. Pour autant, les développeurs doivent revoir et valider le code produit, et s’assurer qu’il respecte les directives de code sécurisé.
Risques de sécurité posés par l’IA et marche à suivre pour des systèmes d’IA résilients
L’intelligence artificielle (IA) transforme nos méthodes de travail. Mais comme toute avancée technologique, elle n’est pas sans poser des problèmes de sécurité. Dans un document très instructif intitulé Securing the Future of AI and Machine Learning, Microsoft détaille certains de ces risques et propose des suggestions intéressantes pour arriver à des systèmes d’IA résilients.
Penchons-nous sur trois de ces risques :
Microsoft évoque un sujet fascinant, la possibilité pour les attaquants d’injecter des vulnérabilités dans les ensembles de données ouverts utilisés par l’IA et le machine learning (ML). En vérité, les attaquants n’ont même pas besoin de compromettre les ensembles de données, il leur suffit d’y contribuer directement. Au fil du temps, ces données malveillantes, si elles ont été camouflées et structurées correctement, peuvent devenir des données de confiance. Ce risque rend difficile la sécurisation du développement par IA.
Autre difficulté, l’obfuscation de classifieurs au sein de modèles d’apprentissage profond. Les modèles de machine learning sont connus pour être des boîtes noires, et cette incapacité à expliquer leur raisonnement empêche de défendre les résultats générés par l’IA et le machine learning. Cette caractéristique, souvent appelée « absence d’explicabilité » pose des problèmes en termes de confiance et d’acceptation, en particulier dans les domaines sensibles.
Par ailleurs, l’absence de capacités d’analyse forensique dans les frameworks IA/ML aggrave encore ce problème. En l’absence de preuves solides, des résultats issus de modèles d’IA/ML présentant pourtant une valeur substantielle peuvent être difficiles à défendre devant un tribunal ou auprès du grand public. Par conséquent, il est essentiel de mettre en place de puissants mécanismes d’audit et de création de rapports dans les systèmes d’IA.
Microsoft suggère que pour résoudre ces risques de sécurité inhérents à IA, au ML et à l’IA générative, il est important de faire de la résilience une véritable caractéristique des systèmes d’IA. Ces systèmes doivent être conçus pour résister aux données entrant en conflit avec les législations locales, l’éthique et les valeurs de la communauté et des créateurs pour doper leur sécurité et leur fiabilité.
Limiter les risques de sécurité dans le développement augmenté par l’IA
Alors que nous nous dirigeons vers un avenir dans lequel l’IA, les LLM et l’IA générative seront des outils à part entière de nos pratiques de codage et processus de développement logiciel, nous devons nous assurer que notre soif d’innovation ne nous pousse à renier l’importance du maintien de pratiques de sécurité solides.
Pour assurer le respect des normes de code sécurisé et limiter au maximum les risques de sécurité associés aux outils d’IA générative, une possibilité efficace serait de mettre en place des revues strictes du code. Que le code soit généré automatiquement par une IA ou écrit par un être humain, il doit faire l’objet de contrôles de qualité rigoureux et d’une évaluation critique par des développeurs ou vérificateurs expérimentés. Ce processus peut faciliter la détection d’erreurs de codage classiques, mais aussi des vulnérabilités de sécurité que les modèles d’IA ne voient pas forcément.
Par ailleurs, l’intégration d’outils permettant de réaliser des tests de sécurité des applications statiques peut grandement limiter les menaces de sécurité introduites par les LLM. L’analyse SAST permet d’étudier le code de l’intérieur sans avoir besoin de l’exécuter et d’identifier des vulnérabilités potentielles au début du cycle de développement. L’automatisation de tels outils de test dans le pipeline de code peut encore améliorer l’identification et la correction des vulnérabilités de sécurité.
L’outil DeepCode AI de Snyk a été conçu pour exploiter plusieurs modèles d’IA et est entraîné sur des données de sécurité sélectionnées par des experts pour fournir aux développeurs des correctifs en temps réel et détecter le code vulnérable au moment où ils l’écrivent, directement dans leur IDE.
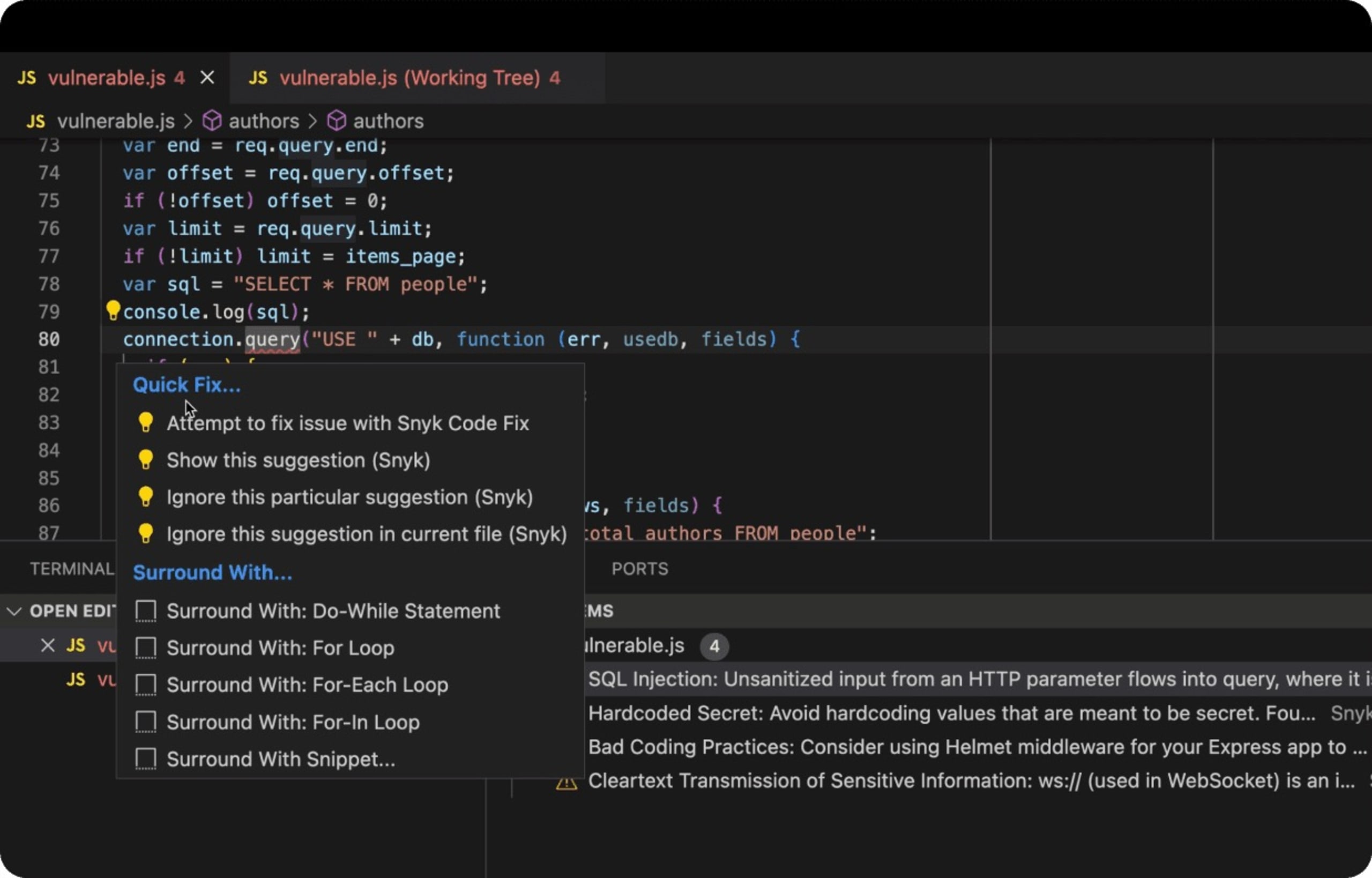
Voici un exemple concret d’application Web Express basée sur Node.js qui utilise une base de données en back end avec du code SQL vulnérable aux attaques par injection SQL. L’extension Snyk pour VS Code détecte le code vulnérable et comme un linter JavaScript, le souligne en rouge, invite le développeur à se montrer vigilant et mieux encore, lui suggère des moyens de corriger le problème.
Enfin, et il s’agit peut-être de l’une des mesures les plus importantes, il est nécessaire d’encourager l’apprentissage et l’adaptation continus au sein des équipes de développement. La mise en place d’une culture qui encourage le partage des connaissances sur les dernières tendances des pratiques de codage sécurisées, les vulnérabilités potentielles et les mesures de correction peut considérablement renforcer la sécurité des applications.
Conclusions sur la sécurité de l’IA
L’intégration agile d’outils d’IA comme les LLM et les modèles d’IA générative promet un développement logiciel plus rapide et optimisé.
Néanmoins, les développeurs humains doivent en assurer la sécurité, la fiabilité et l’efficacité. Les outils de génération de code basés sur l’IA, comme ChatGPT, doivent être considérés comme des aides qui nécessitent l’encadrement d’humains pour pouvoir générer du code suffisamment sécurisé et bon pour être déployé en production.
Le cœur du problème est évident : à mesure que l’IA prend de l’importance, nous devons équilibrer cette appétence pour l’innovation avec de la prudence et de la vigilance. Le codage sécurisé doit rester une norme non négociable, que le code provienne directement d’un humain ou soit suggéré par une IA.
Face à l’innovation apportée par l’IA, attachons-nous à des exigences de sécurité irréprochables pour protéger nos logiciels, nos systèmes et les utilisateurs qui nous font confiance.
Sécurisez l’IA avec Snyk
Découvrez comment Snyk vous aide à sécuriser le code généré par IA de vos équipes de développement tout en donnant une visibilité et un contrôle totaux à vos équipes de sécurité.