Plus précis que GPT-4 : découvrez comment la solution CodeReduce de Snyk dope les performances des autres LLM

7 mai 2024
0 minutes de lectureSnyk est un pionnier de la cybersécurité basée sur l’IA depuis le lancement de Snyk Code en 2021\. Son moteur d’analyse SAST DeepCode AI permettait alors d’identifier les problèmes de sécurité avec une précision et une vitesse inégalées. Au cours des trois dernières années, nous avons suivi avec attention la montée en puissance de l’IA et des LLM, et lancé de nouvelles fonctionnalités basées sur l’IA, comme DeepCode AI Fix, notre fonctionnalité de correction automatique des vulnérabilités ou notre fonctionnalité d’identification des dépendances tierces.
Nous avons d’ailleurs récemment annoncé d’importantes améliorations du modèle de DeepCode AI Fix. Cette fonctionnalité encore en bêta permet de corriger automatiquement les problèmes détectés par Snyk Code. DeepCode AI Fix combine les technologies d’IA les plus récentes et les compétences de nos experts pour générer des correctifs fiables. La résolution des problèmes de sécurité est un processus complexe. Pour vous expliquer notre stratégie, nous allons nous pencher sur un livre blanc qui détaille les secrets de DeepCode AI Fix, à savoir la technologie CodeReduce et notre ensemble de données sur les correctifs optimisé.
L’automatisation des correctifs de sécurité, un problème complexe
Les développeurs passent souvent beaucoup de temps à rechercher et corriger les problèmes de sécurité de leur côté. Avant l’arrivée de DeepCode AI, Snyk Code les aidait à trouver les problèmes, mais leur correction restait chronophage et difficile, car les développeurs sont rarement formés à la sécurité. En effet, ils devaient passer en revue le code manuellement, déterminer ce qu’il était censé faire, comprendre le problème de sécurité dans ce contexte spécifique, puis chercher une solution... et la mettre en œuvre.
Depuis des années, de nombreuses entreprises cherchent à automatiser la correction des problèmes au maximum. Malheureusement, malgré de nombreuses tentatives, il restait difficile de créer une solution capable de générer des correctifs appropriés. Conséquence directe, la plupart des outils de correction automatique se concentraient sur quelques problèmes : ceux ne demandant que de changer quelques lignes de code ou liés à de simples questions de mise en forme.
L’avènement des LLM et d’une nouvelle génération d’IA nous a néanmoins ouvert de nouveaux horizons. Pour autant, même les LLM ne sont pas tout puissants et doivent donc être configurés avec soin pour générer les correctifs de sécurité voulus. La plupart sont entraînés sur d’importants volumes de données et des extraits de code très hétérogènes, mais pas sur des données spécifiquement liées à la correction des problèmes de sécurité. Ce phénomène nous posait deux problèmes :
D’une part, pour un processus aussi spécifique que la correction automatique des problèmes de sécurité, les LLM avaient besoin d’ensembles de données spécialisés contenant des correctifs de code sémantiques et de sécurité pour être pertinents.
D’autre part, en raison des hallucinations des LLM et du contexte limité qu’ils sont capables de prendre en compte, l’ajout de code aux prompts pour guider un LLM généraliste (non entraîné spécifiquement pour la sécurité) vers des résultats plus précis ne suffit pas toujours.
Contournement des limitations des LLM pour des correctifs plus efficaces
Après réflexion, nous avons déterminé que les avantages des LLM étaient supérieurs aux adaptations nécessaires pour corriger leurs défauts, et nous nous sommes donc mis au travail.
Corriger l’ensemble de données
Nous avons créé un ensemble de données complet réunissant des correctifs de sécurité open source pour obtenir les meilleurs résultats possibles. Pour ce faire, nous avons commencé par étiqueter de manière exhaustive des commits open source et créer un ensemble de données propre sur les problèmes en JavaScript et leurs correctifs (depuis, nous avons répété cette opération pour d’autres langages, notamment Java, Python, C/C++, C#, Go et APEX). Ensuite, au lieu d’ajouter manuellement davantage de données étiquetées, nous avons utilisé les fonctionnalités d’analyse de programme de Snyk Code depuis DeepCode AI afin d’obtenir le même effet quantitatif que l’étiquetage des données et construire des ensembles de données propres plus efficacement.
Technologie CodeReduce (en attente de brevet)
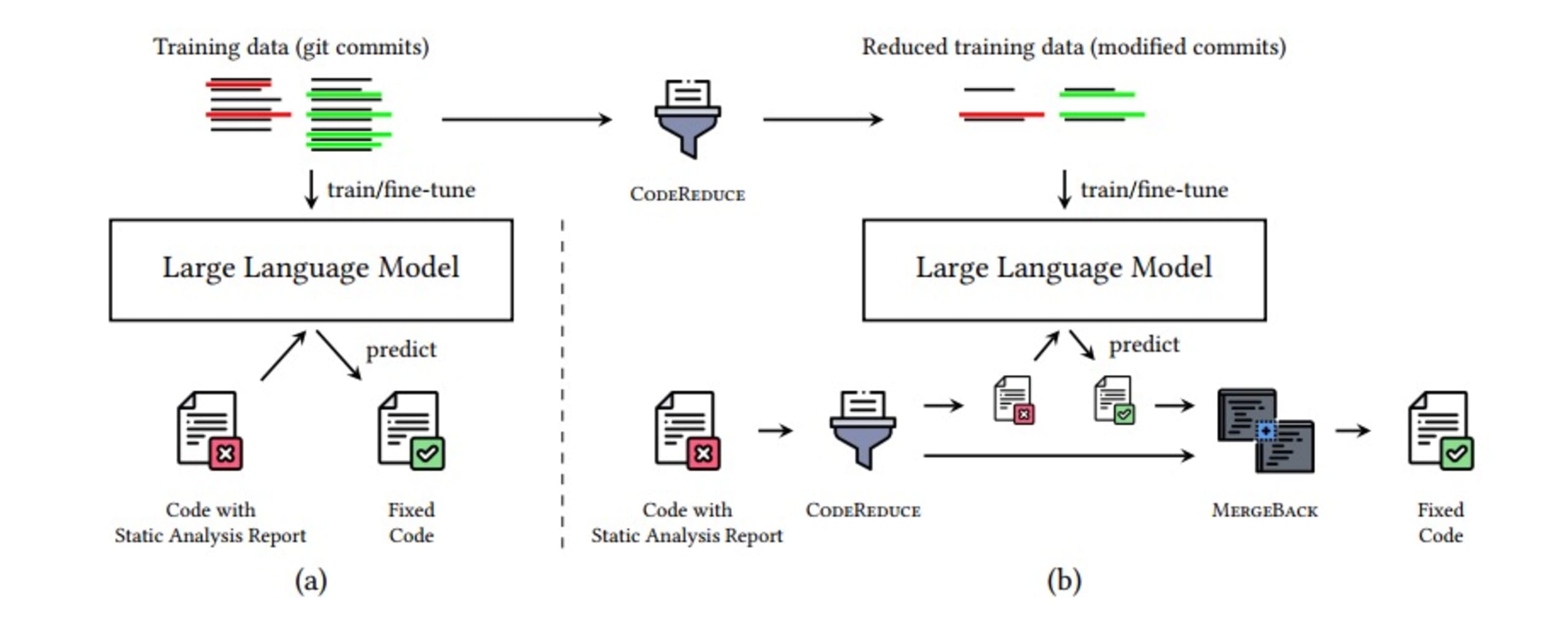
CodeReduce utilise l’analyse de programme pour cadrer l’attention du LLM sur les seules portions de code qui contiennent le problème signalé et le contexte nécessaire pour créer un correctif. Ce processus réduit considérablement le nombre de lignes de code que le LLM a besoin de traiter, ce qui améliore la qualité des correctifs générés pour tous les modèles d’IA testés et limite les hallucinations. Par ailleurs, ce processus permet aussi d’accélérer le traitement. Il devient ainsi possible de générer des correctifs en temps réel : non seulement vous aurez accès à des correctifs plus précis et pertinents, mais vous les obtiendrez aussi plus rapidement.
CodeReduce suit le processus suivant :
Identification du problème de sécurité
Sélection du seul code nécessaire, accompagné du contexte
Ajout du code réduit par CodeReduce au prompt envoyé au LLM et génération d’un correctif
Application du correctif
Utilisation des fonctions d’analyse de Snyk Code pour vérifier que DeepCode AI Fix a bien corrigé la vulnérabilité et que le correctif n’en a pas introduit de nouvelles
Fusion du correctif dans le code d’origine
L’image ci-dessous illustre l’ensemble de ce processus et présente ce à quoi ressemble le pipeline de correction automatique des problèmes. Gardez en tête que tout cela ne prend que quelques secondes grâce à d’autres optimisations détaillées dans l’article de recherche portant sur CodeReduce.
Quels résultats ?
Une fois ces problèmes résolus, nous avions besoin de savoir si nos correctifs de sécurité étaient efficaces. Nous avons donc créé un outil de comparaison compatible avec différents LLM.
Nous avons réalisé nos évaluations avec les indicateurs « Pass@𝑘 ’» et « ExactMatch@𝑘 » pour les modèles qui utilisent CodeReduce (signalés par le symbole ‡ dans le tableau ci-dessous) en les comparant aux valeurs de base de TFix, un modèle basé sur une fenêtre et divers modèles à contexte élargi comme GPT-3.5 et GPT-4.
La variable « k » dans l’indicateur « Pass@k » indique combien des 5 correctifs générés à chaque instance résolvent le problème de sécurité concerné sans en introduire de nouveaux. Elle est comprise entre 1 et 5.
Nous avons également défini 5 catégories de problèmes de sécurité à tester :
AST : vulnérabilités nécessitant un arbre de la syntaxe abstraite, mais pas de flux de données dédié
Local : valeurs incorrectes transmises à des méthodes ne les acceptant pas
FileWide : problèmes de signature ou d’implémentation
SecurityLocal : utilisation de l’API, suivi des appels aux méthodes
SecurityFlow : analyse des variables pouvant être modifiées par un utilisateur externe (nécessite un flux de données complexe)
Enfin, nous avons choisi plusieurs LLM : StarCoder, Mixtral, T5, GPT-3.5 et GPT-4 Les résultats sont les suivants :
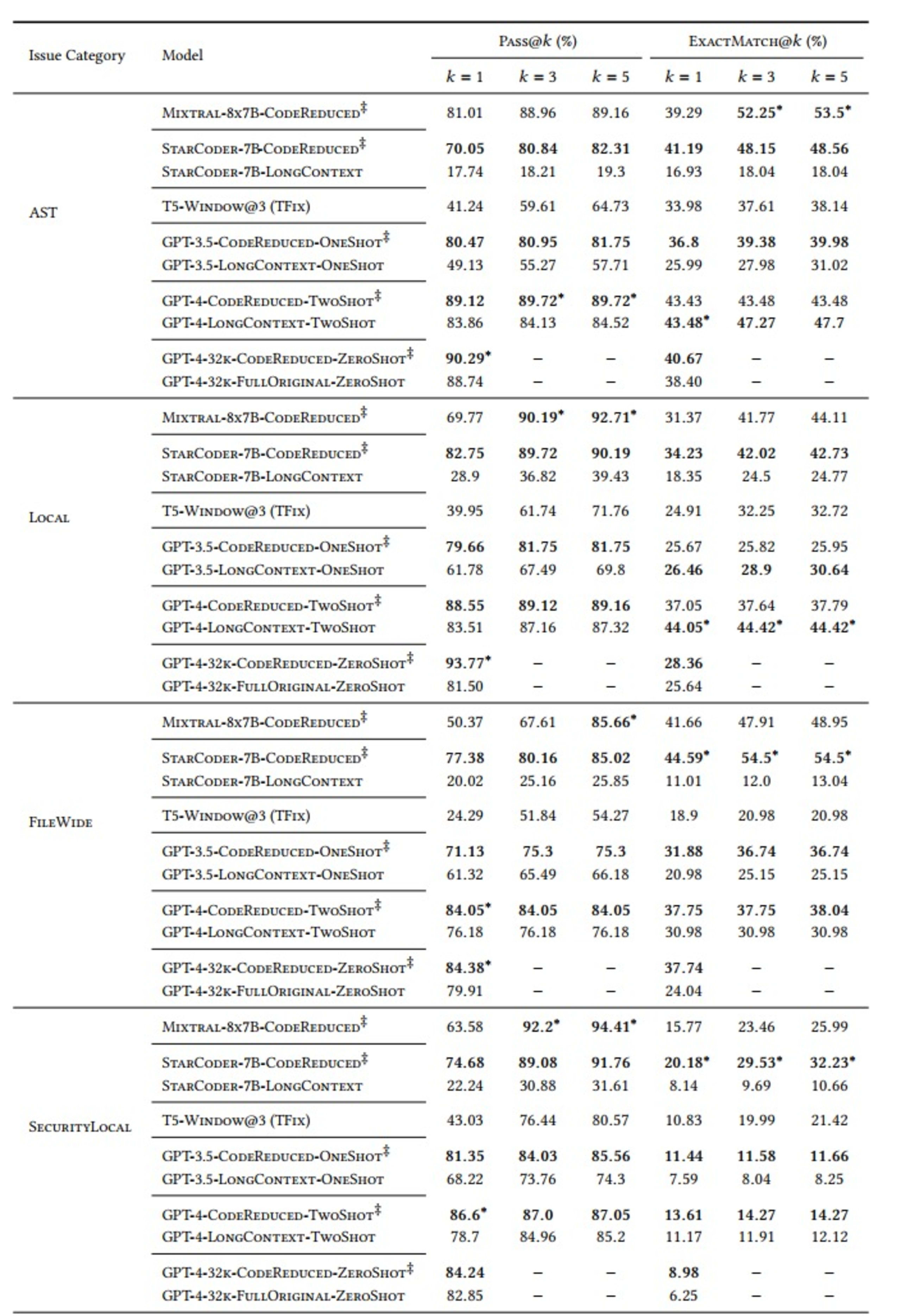
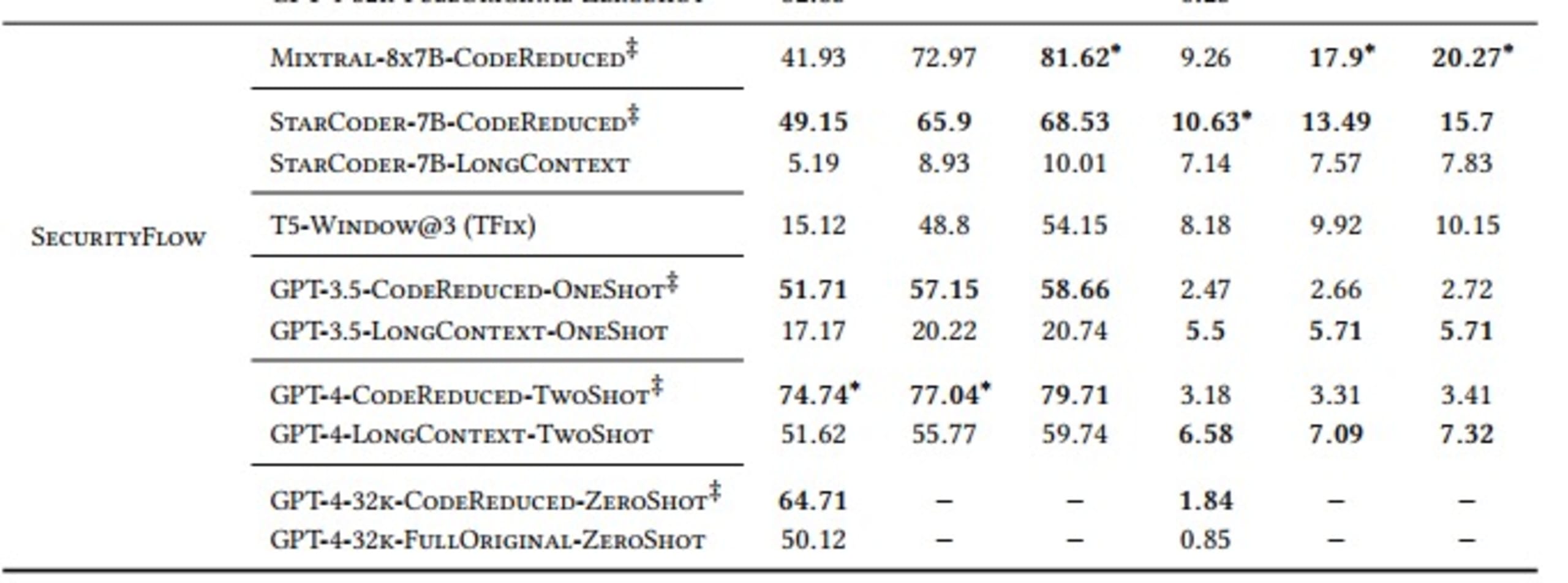
Comme le montre le tableau, les modèles qui en temps normal apprennent les dépendances lointaines complexes nécessaires pour générer un correctif efficace ont présenté de meilleures performances avec le contexte de code extrait par CodeReduce. L’amélioration considérable de l’indicateur Pass@5 pour les problèmes AST illustre bien ce phénomène. Le modèle StarCoder est passé d’un taux de réussite de 19,3 % (sans CodeReduce) à 82,31 % (avec CodeReduce).
Conclusions
Globalement, DeepCode AI Fix a fait mieux que la référence, TFix, et aide de nombreux modèles d’IA très utilisés à gagner en performance dans différentes configurations. Ces résultats s’expliquent par l’utilisation d’une analyse de programme réalisée par la technologie CodeReduce propriétaire de Snyk pour gérer les dépendances lointaines et les flux de données. DeepCode AI Fix simplifie ainsi considérablement l’apprentissage des problèmes de sécurité considérés en limitant l’attention des LLM et permet de générer des correctifs plus précis et pertinents.
Vous pouvez tester la puissance de DeepCode AI Fix dans votre IDE en vous inscrivant à Snyk Code et en activant l’option Snyk Code Fix Suggestions dans les paramètres Snyk Preview. Pour en savoir plus, consultez notre documentation. N’hésitez pas à guider les futures évolutions de DeepCode AI Fix en nous faisant vos retours sur les correctifs proposés directement depuis Snyk Code.
Cap sur la capture du drapeau
Découvrez comment résoudre les défis de capture du drapeau en regardant notre atelier virtuel à la demande.