Mais preciso que o GPT-4: como o CodeReduce da Snyk aumentou o desempenho de outros LLMs

7 de maio de 2024
0 minutos de leituraDesde o lançamento do Snyk Code em 2021, a Snyk é pioneira em cibersegurança baseada em IA. A precisão e a velocidade incomparáveis do DeepCode AI permitiram identificar problemas de segurança no espaço de SAST pela primeira vez. Nos últimos três anos, presenciamos a evolução da IA e dos LLMs. Na vanguarda desse desenvolvimento, a Snyk introduziu novas funcionalidades baseadas em IA, como o DeepCode AI Fix, um recurso de correção automática de vulnerabilidades, e a capacidade de alcançar dependências de terceiros.
Recentemente, anunciamos melhorias significativas no modelo do DeepCode AI Fix, um recurso beta que corrige automaticamente problemas de segurança identificados pelo Snyk Code. O DeepCode AI Fix combina a tecnologia de IA mais recente e funcionalidades internas especializadas para gerar correções confiáveis. Corrigir problemas é uma tarefa complicada. Para você entender melhor como funciona o nosso trabalho, vamos examinar em detalhes um estudo sobre os principais ingredientes da tecnologia DeepCode AI Fix – CodeReduce e do nosso conjunto de dados administrado de correções de segurança.
Automação de correções de segurança, um problema complexo
Muitas vezes, os desenvolvedores dedicam bastante tempo para encontrar e corrigir problemas de segurança de forma independente. Antes do DeepCode AI, o Snyk Code ajudava os desenvolvedores na etapa inicial de identificação dos problemas. Mesmo assim, a correção dos problemas de segurança podia ser desafiadora e demorada porque os desenvolvedores normalmente não tinham treinamento em segurança (o que ainda é uma verdade). O processo de correção exige que os desenvolvedores revisem manualmente o código, descubram como ele deve funcionar, entendam os problemas de segurança dentro do contexto do código e então pesquisem como corrigi-los antes de sanar o problema.
Para muitas empresas, a correção automatizada de problemas de segurança, ou “correção automática”, tem sido o foco ao longo dos anos com o objetivo de reduzir a maior parte do trabalho relacionado. No entanto, apesar de muitas tentativas, criar uma solução com correções precisas se mostrou uma tarefa difícil. Como resultado, a maioria das ferramentas de correção automática priorizou um pequeno conjunto de problemas, como alterações triviais envolvendo poucas linhas de código ou problemas simples de formatação.
Com o advento dos LLMs, percebemos o potencial de usar a nova geração de IA para criar uma funcionalidade de correção automática mais robusta. No entanto, mesmo os LLMs apresentam limitações na correção de problemas de segurança quando não são configurados adequadamente para produzir os resultados desejados. A maioria dos LLMs foi treinada com uma grande variedade de dados e código, mas não especificamente em correções de segurança. Isso gerou dois problemas sérios para nós:
As correções automáticas de segurança são bastante específicas. Para gerar correções de código relevantes e precisas, os LLMs precisam ser treinados com um conjunto de dados especializado em correções de código de segurança e semântica.
Considerando as alucinações e a capacidade dos LLMs de processar um contexto limitado a cada vez que geram uma saída, a adição de código complementar aos prompts para orientar um LLM “de propósito geral” (em vez de um treinado especificamente em segurança) na geração de saídas mais precisas nem sempre aprimora os resultados.
Como abordar as limitações dos LLMs para criar correções melhores
Chegamos à conclusão de que as vantagens do uso de LLMs superavam o esforço necessário para sanar as limitações identificadas, então assumimos o compromisso de resolvê-las.
Conjunto de dados de correções
Criamos um conjunto abrangente de dados de correções de segurança de código aberto para garantir os melhores resultados possíveis. Em primeiro lugar, realizamos uma ampla rotulagem de confirmações de código aberto e construímos um conjunto de dados depurado de problemas e correções para JavaScript (desde então, fizemos o mesmo com outras linguagens, como Java, Python, C/C++, C#, Go e APEX). Em segundo lugar, em vez de continuar adicionando dados rotulados, usamos os recursos de análise programática do Snyk Code do nosso mecanismo DeepCode AI para produzir de forma eficiente o mesmo efeito quantitativo que a rotulagem de dados. Isso nos permitiu gerar conjuntos de dados limpos.
Tecnologia CodeReduce (patente pendente)
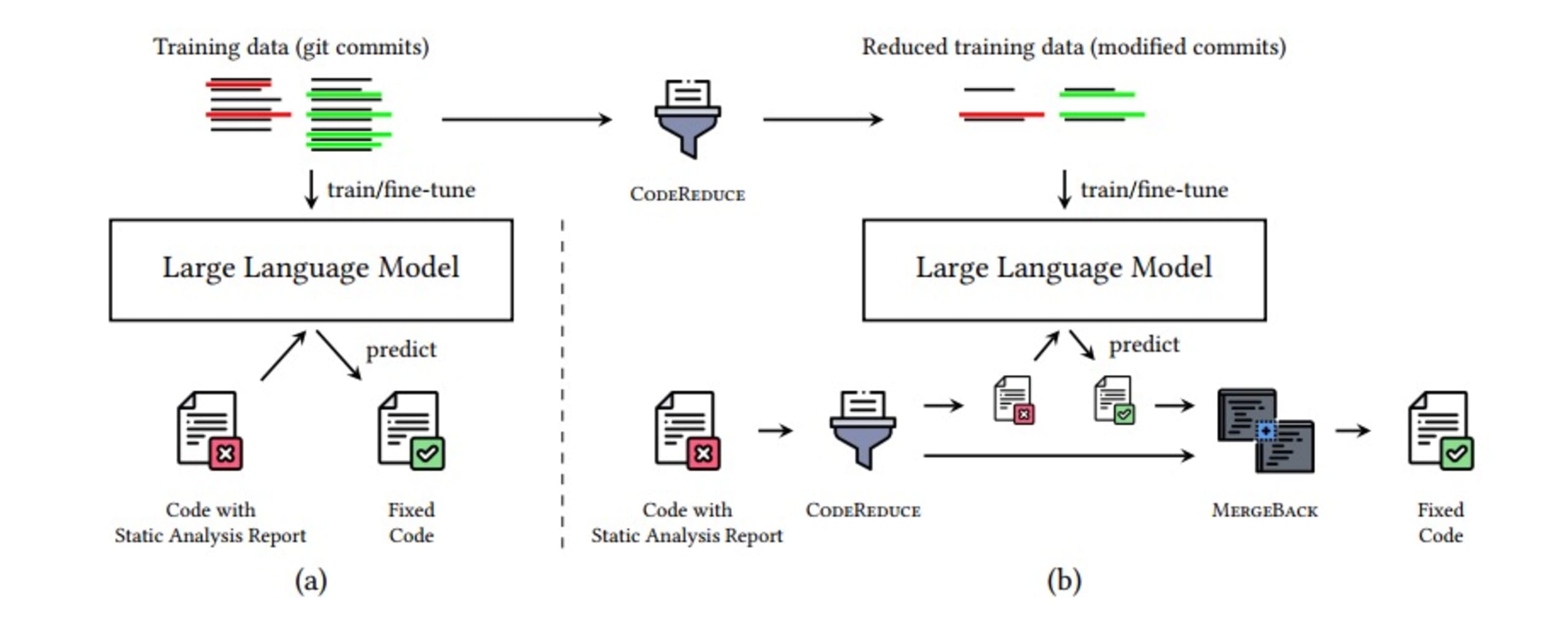
O CodeReduce usa a análise programática para limitar o mecanismo de atenção do LLM às partes do código necessárias para realizar a correção, ou seja, o LLM mantém o foco em um trecho menor do código, que contém o defeito relatado e o contexto necessário. Isso reduz drasticamente o volume de código que o LLM precisa processar. Por sua vez, essa restrição de contexto ajuda a melhorar a qualidade das correções geradas em todos os modelos de IA testados e reduz as alucinações. Além disso, a passagem de menos informações pelo modelo acelera o processamento, viabilizando a geração de correções em tempo real. Em outras palavras, você obtém correções mais precisas e relevantes em menos tempo.
O processo do CodeReduce inclui as seguintes etapas:
Identificar o problema de segurança
Usar o CodeReduce para reduzir o código ao mínimo necessário com contexto
Adicionar o código selecionado pelo CodeReduce ao prompt do LLM e gerar uma correção
Aplicar a correção
Usar os recursos de verificação do Snyk Code para conferir novamente se o DeepCode AI Fix corrigiu a vulnerabilidade e se nenhuma outra foi introduzida no processo
Usar MergeBack para corrigir o código original
A imagem abaixo mostra um resumo do pipeline de correção automática de problemas de segurança. Tudo isso ocorre em questão de segundos, graças às otimizações adicionais que você pode encontrar no estudo sobre o CodeReduce.
Quais são os resultados?
Com esses problemas resolvidos, era necessário testar o funcionamento das correções automáticas de segurança. Para isso, criamos um teste de referência que poderia ser usado em diferentes LLMs.
Fizemos nossas avaliações usando as métricas “Pass@𝑘” e “ExactMatch@𝑘” para modelos que usam o CodeReduce (conforme indicado pelo símbolo ‡ na tabela abaixo) em comparação com a referência do TFix, um modelo baseado em janelas, e vários modelos de grande contexto, como GPT-3.5 e GPT-4.
A variável "k" em "Pass@k" mede quantas das cinco correções geradas a cada vez (variando de pelo menos uma correção a todas as cinco) resolvem o problema de segurança relevante e não introduzem novos problemas de segurança.
Também definimos cinco categorias de problemas de segurança para os testes:
AST: vulnerabilidades que exigem uma árvore de sintaxe abstrata, mas não um fluxo de dados dedicado
Local: valores incorretos fluindo para métodos que não os aceitariam
FileWide: problemas de assinatura ou implementação
SecurityLocal: uso de API, rastreamento de chamadas de método
SecurityFlow: análise complexa de contaminações que exige um fluxo de dados complexo
Além disso, escolhemos vários LLMs para comparação: StarCoder, Mixtral, T5, GPT-3.5 e GPT-4. Estes foram os resultados:
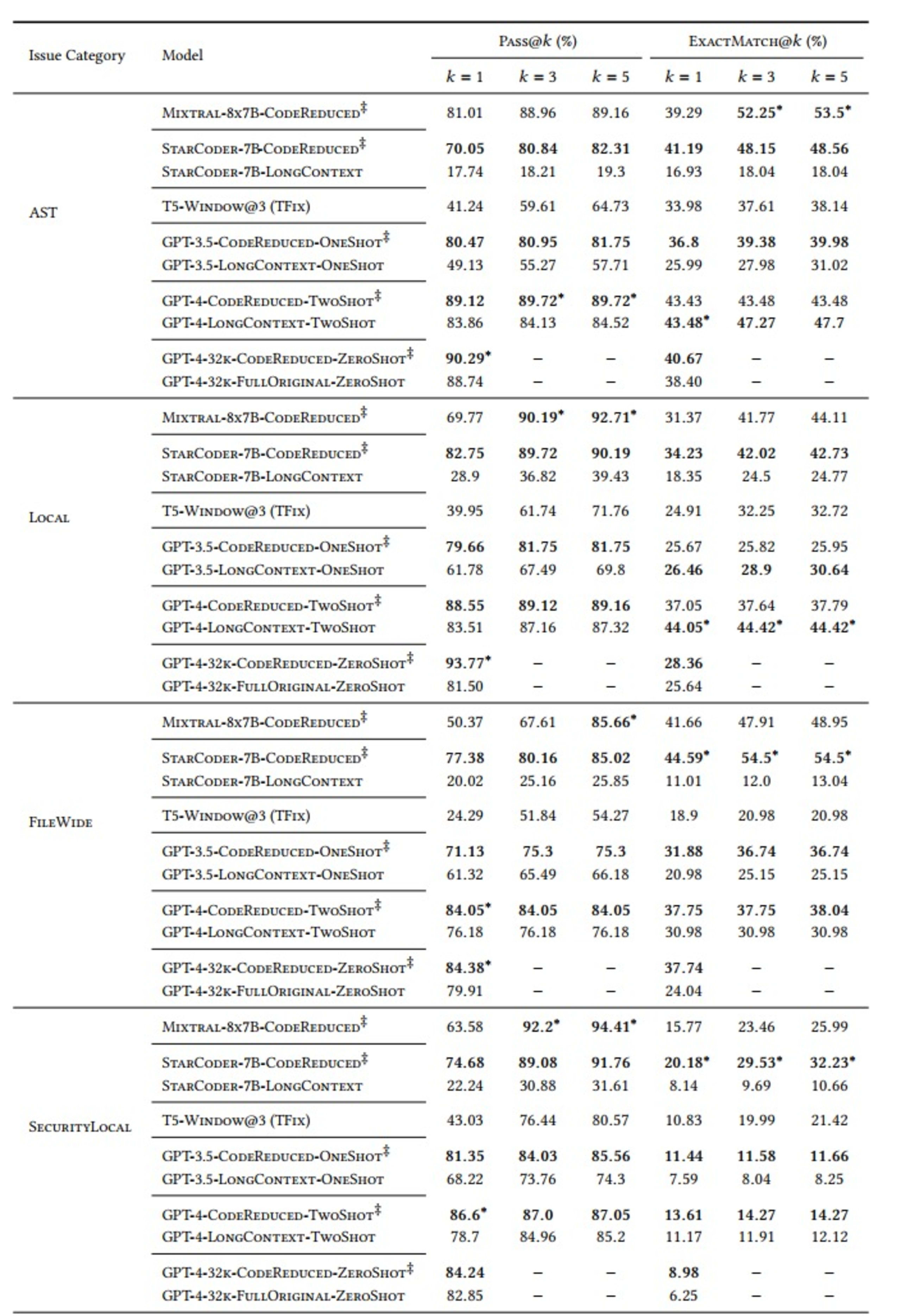
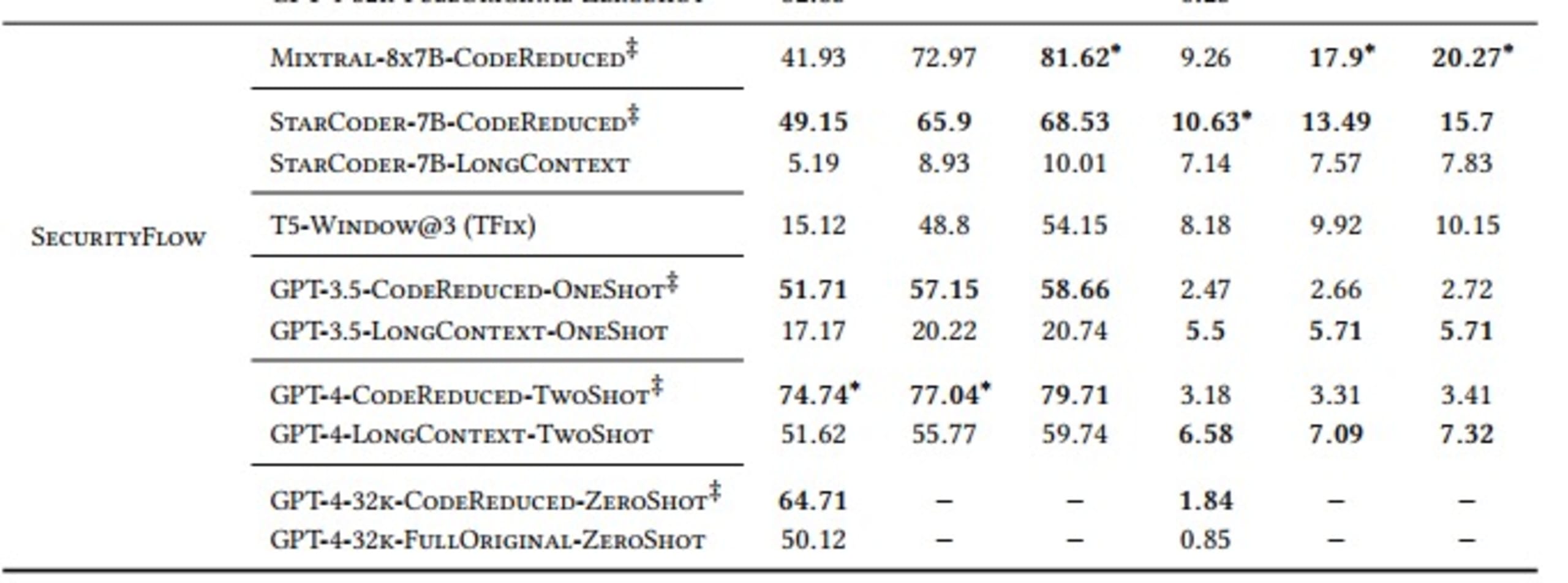
Como demonstrado na tabela, os modelos que normalmente aprenderiam as dependências complexas e de longo alcance necessárias para criar uma correção correta apresentaram um desempenho significativamente melhor quando usaram o contexto de código extraído pelo CodeReduce em comparação com as correções criadas sem a ajuda do CodeReduce. Um bom exemplo é a grande melhoria no resultado Pass@5 para corrigir problemas de AST usando o modelo StarCoder. A taxa de sucesso passou de 19,3% (sem o CodeReduce) para 82,31% (com o CodeReduce).
Principais conclusões
No geral, o DeepCode AI Fix superou o desempenho de referência anterior estabelecido pelo TFix e ajudou vários modelos de IA populares com diferentes configurações a apresentar resultados melhores. O motivo para isso é que o DeepCode AI Fix usa análise programáticas com a tecnologia proprietária CodeReduce da Snyk para lidar com dependências e fluxos de dados de grande alcance. O DeepCode AI Fix restringe o foco de atenção dos LLMs para simplificar consideravelmente o aprendizado sobre os problemas de segurança em questão e viabilizar a criação de correções mais precisas e relevantes.
Você já pode experimentar a funcionalidade avançada do DeepCode AI Fix no IDE. Basta se registrar no Snyk Code e ativar as “Snyk Code Fix Suggestions” (Sugestões de correção do Snyk Code) nas configurações do “Snyk Preview” (Prévia da Snyk). Confira mais informações na nossa documentação. Você pode ajudar a moldar o futuro do DeepCode AI Fix enviando feedback dos usuários sobre nossas correções no Snyk Code.
Primeiros passos com Capture the Flag
Saiba como resolver desafios de Capture the Flag assistindo ao nosso workshop virtual de conceitos básicos sob demanda.