Creating an automated cloud infrastructure testing tool with Terraform and PyTest

27 de março de 2020
0 minutos de leituraEditor's note
This blog originally appeared on fugue.co. Fugue joined Snyk in 2022 and is a key component of Snyk IaC.
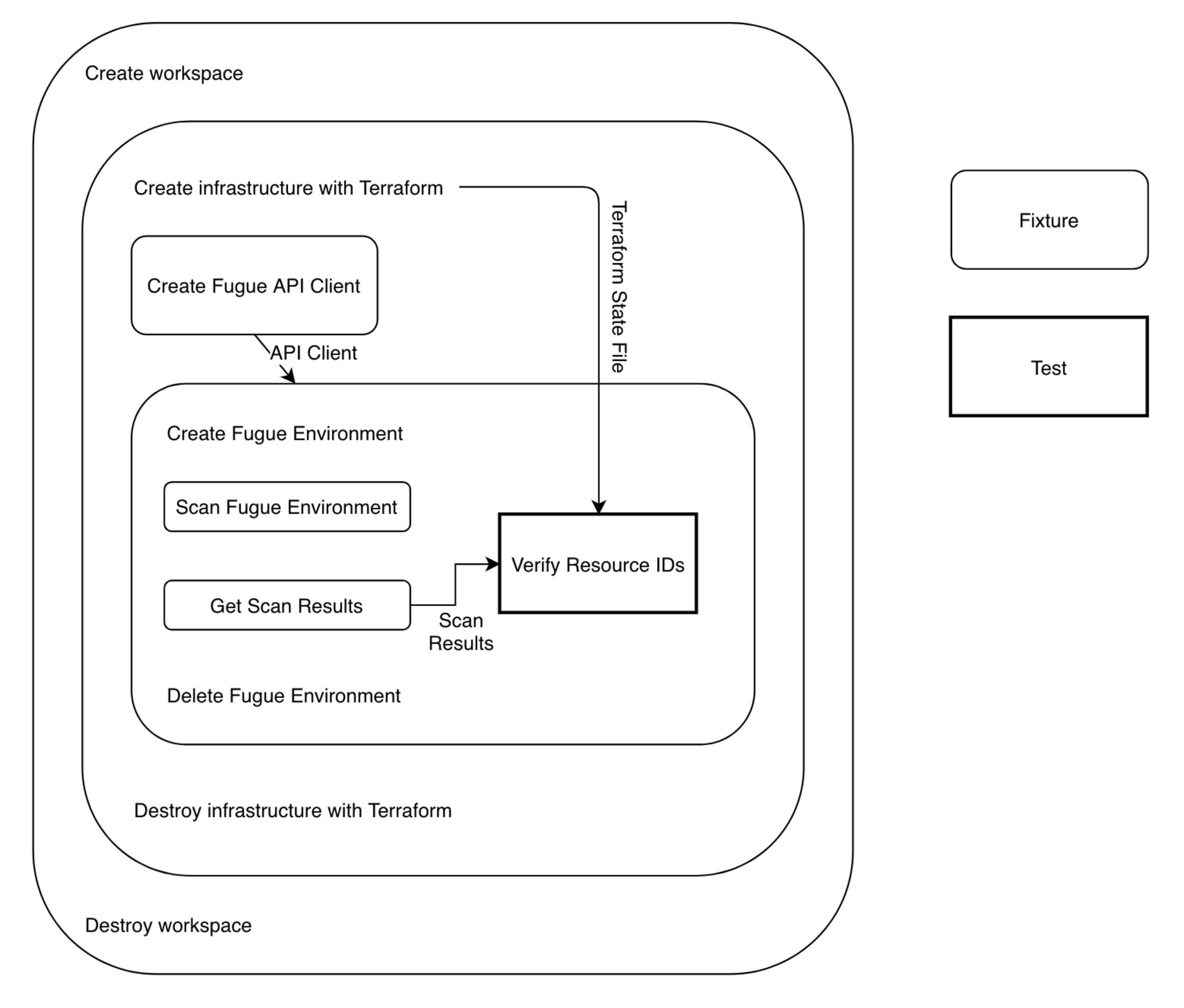
Recently, I was tasked with creating an automated testing tool for Fugue. Fugue monitors cloud resources for compliance and security, and we needed a way to verify that the full results of a Fugue scan were correct. My goal was to create an automated system that runs locally or in CI, deploys configurable infrastructure, scans it using Fugue, and verifies the results. This blog post walks through the design and implementation process for what became autotest, our internal automated testing tool.
While this example specifically uses Terraform and the Fugue API, the design of the fixtures is applicable to any CLI commands and APIs, so the ideas here can easily be adapted to other use cases.
Design
Before starting on the project in earnest, I spent a couple of days doing research and trying to understand the problem. After looking through some Google searches, I decided to base my tool on the pytest framework. I've previously worked with pytest in a unit testing capacity, but this was a perfect opportunity to explore it in-depth and discover how to use it as the basis of a functional test.
The test procedure can be broken down into three steps:
Use Terraform to deploy modular infrastructure
Create a Fugue environment pointing to this infrastructure and scan it
Retrieve scan results and verify the results
I knew I wanted to use Terraform for step 1 because we had a number of existing infrastructure test Terraform configurations, and because Terraform supports AWS, Azure, and many other cloud service providers. For step 2, I knew I could use the Fugue API to create the environment and initiate a scan. Finally, I could use the Fugue API again in step 3 to get the full results of the scan to verify them.
Once I had the high-level design down, I could start looking at pytest to understand how to use it to implement my design.
PyTest
pytest is a testing framework for Python with test discovery, assertions using Python's built-in assert statement, and fixtures for dependency management.
Fixtures are pytest's secret sauce. They're decorated functions that manage the lifecycle of test dependencies. Setup and teardown code that would traditionally be in setUp() and tearDown() methods is placed in fixtures instead. Fixture scope can be defined so the outputs of fixtures are reused across classes, modules, or sessions.
Let's look at an example. Here I define and use a fixture for accessing an API. While in a unit test I would use a mock API object, in a functional test I have to use the real thing.
The api_client fixture is declared by using the @pytest.fixture decorator, and I can set the scope of the fixture using the scope argument in the decorator. The API client is safe to reuse across all tests, so I defined it with a session scope. Fixtures can be defined in the same module as test functions or classes, or they can be placed in conftest.py, which will make them available to all test modules.
I can use the fixture just by including its name as an argument to a test function. In this example, I used the api_client fixture in two tests. Since I defined the fixture with session scope, pytest will ensure that the fixture is only called once during each test session.
You may have noticed that the api_client fixture takes an input parameter creds. We never call the fugue_api function directly, so how does creds get a value?
If you guessed that creds is itself a fixture, here's a gold star: ⭐️. Fixtures can call other fixtures, so complex dependencies can be built up from a chain of fixtures. Let's look at the definition of creds:
I'm maintaining good security hygiene, so creds uses credstash to store and retrieve secret values. The name of the secret is passed in as a command-line option to pytest. These options are defined in pytest_addoption, and accessed through the request fixture. The creds fixture makes it easy for me to abstract away the implementation of getting credentials and focuses my thinking on what inputs are needed for a given test or fixture. If I later change the way I access credentials, I only need to modify creds.
Now that we understand the basics of pytest fixtures, let's look at how we can use them to implement our design.
Step 1: Using Terraform to Deploy Infrastructure
The first step of our tool creates infrastructure that will be scanned and used as the basis for verification in steps 2 and 3. I know I'll be using Terraform to deploy this infrastructure, but how exactly will that work?
Design
This snippet shows the structure of our existing test configurations. These configurations can be deployed manually by running terraform apply from the aws/ root, or from a service subdirectory, such as aws/api_gateway. I want to preserve this modularity, so we can choose which services to test. I could call Terraform in the existing structure, but that's a bad habit — all filesystem work should be done in unique temporary directories so test runs execute in controlled environments — so I know I'll need a way to manage temporary workspaces. I'll also need a way to call Terraform, record its output, and check for errors. Terraform will be creating real (expensive) infrastructure, so it's essential that I have error handling that will tear down infrastructure if anything goes wrong.
In summary, the requirements for the first step are:
Create and manage temporary workspaces
Copy test configurations to a workspace
Call Terraform and handle errors by tearing down infrastructure that has already been created
It's clear that 1 and 2 can be handled in a fixture, but can something as complex and error-prone as creating infrastructure using Terraform work as a fixture too?
If you said YES, here's another gold star: ⭐️. Let's take a closer look at how we define our workspace and Terraform fixtures.
The Workspace Fixture
There's a lot going on in the six lines of code of workspace. First, notice that workspace is defined as a yield_fixture. This means that the function returns control to its caller via yield rather than return. Execution of the fixture is suspended in the meantime, so context managers remain open. When control returns to the fixture, any code after the yield statement is executed. In this case, the Workspace context manager exits. pytest handles getting the returned value from a yield_fixture, so we can treat them just like normal fixtures. workspace is a class-scoped fixture, so a new workspace is created for each test class. This way I can divide AWS and Azure tests by class and ensure that a new workspace is created for each provider.
Next, we can see that workspace depends on three fixtures: tmpdir_factory, provider, and services. tmpdir_factory is a built-in fixture that returns a unique temporary directory. The base directory can be set manually using the --basetemp=DIRECTORY option, which is handy for debugging. provider and services are fixtures I defined that return the provider the current test is testing against, and the list of services from the input.
One of my favorite aspects of fixtures is that they encourage clean abstractions. Inputs to a test or fixture are defined through an interface, the function definition, while implementations are hidden in the fixture definition. The modularity of fixtures makes it quick and easy for me to create a separate fixture for every workspace input, so I won't be tempted to build the values in workspace.
Finally, note that the Workspace is a context manager class. This automatically closes out the workspace when the fixture itself is finalized. As I mentioned before, the yield statement doesn't finalize the context manager until control is returned to the fixture when it is being finalized. I used this powerful pattern throughout the design of autotest. Copying the Terraform configurations I want to use to the workspace is handled in initialize_workspace, which is left as an exercise for the reader.
The Terraform Fixture
The Terraform fixture is actually three fixtures: terraform, infra, and terraform_resources. The result of the fixture chain is a dictionary of Terraform resources read from the Terraform state file. terraform initializes Terraform in a workspace, infra runs terraform plan and terraform apply to build the infrastructure, and terraform_resources pulls out the resource map.
Initialization and resource map extraction are straightforward, but I will note that terraform_resources needs to be a yield_fixture because infra is a yield_fixture. If terraform_resources returned a value, it would close the context left open by infra and trigger the teardown code.
Instead of using a context manager class, infra uses a function-based context manager, build_infra, defined next:
build_infra uses the python-terraform package to call Terraform and collect its output. We check the error code on all operations and raise custom exceptions if any errors occurred. t.plan and t.apply call terraform plan and terraform apply respectively to plan and create infrastructure. terraform apply can fail having partially completed infrastructure creation — terraform does not automatically tear down infrastructure that has already been created — so we catch TerraformApplyError and call t.destroy manually before re-raising the original exception.
build_infra is a generator: it calls yield instead of return, which lets me use the @contextmanager decorator to turn it into a context manager. The try...finally block around yield ensures that the teardown code will run even when exceptions are raised in the calling context.
Finally, notice the similarity between the code in the except block and the finally block. The two blocks are doing the same thing: ensuring that infrastructure is torn down no matter what happens during execution. Since code in a finally block is executed both when an exception occurs and also when one does not, we can consolidate the try blocks.
Furthermore, we know that t.plan doesn't create resources, so we can move it outside of the try block. In general, it's a good habit to keep try blocks as tightly-scoped as possible. The final build_infra context manager looks like this:
Step 2: Creating a Fugue Environment and Scanning It
The next step in our high-level design is to use the Fugue API to create and scan an environment in the account in which the infrastructure was created in Step 1.
Design
The Fugue API is a REST API defined using Swagger. This makes it easy to generate a client that will allow me to access the API using native functions and types, rather than through HTTP calls. Once I have a working client, I can use it to create an environment and scan it. I can break it down into three steps:
Generate and configure a client for the Fugue API
Use the client to create an environment
Use the client to initiate a scan and wait for it to complete
The Swagger API Client
I used swagger-codegen to generate a client based on the Fugue API definition:
This generated a full Python package for the API client, which I didn't need, so I copied the client code directly into autotest. Then I initialized the client as below:
Here creds is just an input parameter, not a fixture, because initialize_client is not a fixture or a test. Recall that initialize_client is called from a fixture that depends on the creds fixture:
Defining the environments API fixture is straightforward since API clients don't need to be finalized. The Swagger generated client has a base API client that manages connecting to the API, and separate classes for each top-level division of the API. Then API actions are available as methods on each class.
A note on abstractions: I abstract away the details of the Swagger client via the api module. This is in accordance with the principle of abstracting on both sides of an interface and gives me the flexibility to work around any changes that could occur in the client interface. We'll explore this in more detail when I discuss creating an environment using the API.
Creating an Environment and Scanning It
My first pass at an environment fixture looked something like this:
This is a straightforward application of the create_environment method of the environments API. I get credentials and input parameters from the aws_creds, survey_resource_types, and services fixtures. The fixture is scoped to classes because I organize tests for different cloud providers by class. Finally, I yield the environment so I can automatically delete the environment when the test is over.
The design of this fixture is simple and does what I need. If I wanted to, I could leave it as-is and move on. However, there are downsides to the simplicity of this approach. The input to create_environment is cumbersome because it has many fields, some of which are provider-dependent. Using the environments API directly in the fixture limits the flexibility I have to prepare the input parameters for create_environment without creating a huge, hard-to-read function. The difficulty of trying to balance readability and reusability led me to abandon reusability and hard-code the provider and duplicate the environment fixture for Azure environments, which was not a good solution. What I really need is another layer between the fixture code and the environments API, that will encapsulate the inconvenient input preparation, and manage the relationship between the fixture and the API. Luckily, I have exactly that with the api module.
I partitioned off the input preparation and API invocation into a function in the api module:
While large, this function handles both AWS and Azure, and it allows the environment fixture to be reduced to the basics:
I can take the same approach to initiating scans in an environment:
Including the terraform_resources fixture despite not using the output guarantees that the resources have been created before I initiate a scan. Then in the api module:
Now I have fixtures for creating resources using Terraform and creating a Fugue environment and scanning it, which means I'm almost ready to write some tests.
Step 3: Retrieving and Verifying Scan Results
Before I write tests, I need to be able to get scan results back from the Fugue API. Scan results are available in the API via the custom rules test input endpoint. Creating this fixture is a straightforward application of the concepts I used above:
get_scan_resources is just a pass-through:
For simple functions like this, it's tempting to skip the abstraction layer and put the API call directly in the fixture. In fact, that's what I did in the first version of this function. However, this creates a leaky abstraction — an abstraction layer that exposes some of the underlying functionality that it's meant to hide. Leaky abstractions end up increasing rather than decreasing the cognitive load of using an abstraction.
Now that I have a scan_resources fixture, I have all of the inputs I need for my test. After all of the preparation and abstractions I discussed in the previous sections, the test itself is just a few lines of code:
check is a pytest plugin fixture that provides non-failing assertions. verify_resource_id is a simple verification function that compares two resources and returns true if they have the same resource id:
I have access to the full resource details if I want to write more involved tests, but standing up infrastructure and verifying that it's scanned correctly is good enough for now. Running the test produces this output:
Conclusion
This blog post described the creation of autotest, an automated infrastructure testing tool, using pytest. I discussed the power of pytest's modular fixtures, which make building clean and powerful abstractions a breeze. I also covered how to use the Fugue API to create environments and scans, and how to encapsulate those actions in fixtures. Then, I discussed using the Fugue API's custom rule test input endpoint to download a full description of the resources in a scan. Finally, I put it all together in a test.
One more thing…
Fugue is cloud security and compliance. Built for engineers, by engineers. With Fugue, you can:
Get complete visibility into your cloud infrastructure environment and security posture with dynamic visualizations and compliance reporting.
Validate compliance at every stage of your software development life cycle for CIS Foundations Benchmark, HIPAA, PCI, SOC 2, NIST 800-53, ISO 27001, GDPR, and your custom policies.
Protect against cloud misconfiguration with baseline enforcement to make security critical cloud infrastructure self-healing.
Segurança de IaC projetada para os desenvolvedores
A Snyk protege sua infraestrutura como código desde o SDLC até o runtime na nuvem com um mecanismo unificado de política como código, para que cada equipe possa desenvolver, implantar e operar com segurança.