Performance in OPA Rego: Bottom-up and top-down

29 avril 2021
0 minutes de lectureIn this blog post, we’ll talk a bit about how Rego evaluation works, and how it affects performance. Rego is a DSL for authoring policy. It is not restricted to a single kind of policy (e.g., RBAC) but instead is very general-purpose, making it possible to share policies across different services and stacks. We’ve found Rego to be ideal for cloud infrastructure security in Fugue, and infrastructure as code security in our open source project, Regula.
Rego is based on Datalog, a declarative language: intuitively, this means that the programmer specifies the results they want, and not necessarily how these results are computed. This stands in contrast with imperative languages (such as JavaScript and Python), where the programmer always provides the exact algorithm.
The distinction is not always clear: most declarative languages have some form of indicating how something should be computed (as we’ll demonstrate in this blog post), and it’s possible to build declarative DSLs in imperative languages. In either case, Rego strongly leans towards the declarative end of the spectrum.
Since the programmer does not have to specify how a result is computed, the compiler or interpreter has more freedom here. For languages like Rego, there are two important strategies: bottom-up and top-down.
Using a simple example, we’ll explain both of these and talk about the relative advantages and disadvantages.
An example
Imagine we’re writing a policy to ensure that write permissions are set granularly. Our input could look a bit like this:
{
"roles": [
{"name": "temporary_hack", "read": "*", "write": "*"},
{"name": "manage_assets", "read": "*", "write": "/assets/"}
],
"users": [
{"name": "alice", "roles": ["manage_assets"]},
{"name": "bob", "roles": ["temporary_hack", "manage_assets"]}
]
}Some of these roles have what we’ll call dangerous write permissions: write: *. In our policy, we want to print an error for each user that has a dangerous role assigned.
We define two rules:
dangerous_roles:a set that contains all policies withwrite: *deny: a set with all the error messages
Here is the full policy:
package main
dangerous_roles[role_name]
{
role := input.roles[_]
role_name := role.name
role.write == "*"
}
deny[msg]
{
user := input.users[_]
role_name := user.roles[_]
dangerous_roles[role_name]
msg := sprintf(
"Please remove role %s from user %s", [role_name, user.name]
)
}We can verify that we see the expected output by using opa eval:
$ opa eval --format pretty -d policy.rego -i input.json 'data.main.deny'
[
"Please remove role temporary_hack from user bob"
]With this example in mind, let’s have a look at bottom-up and top-down evaluation.
Bottom-up
I find it easiest to understand the distinction between these two evaluation strategies by visualizing the dependency tree of the rules:
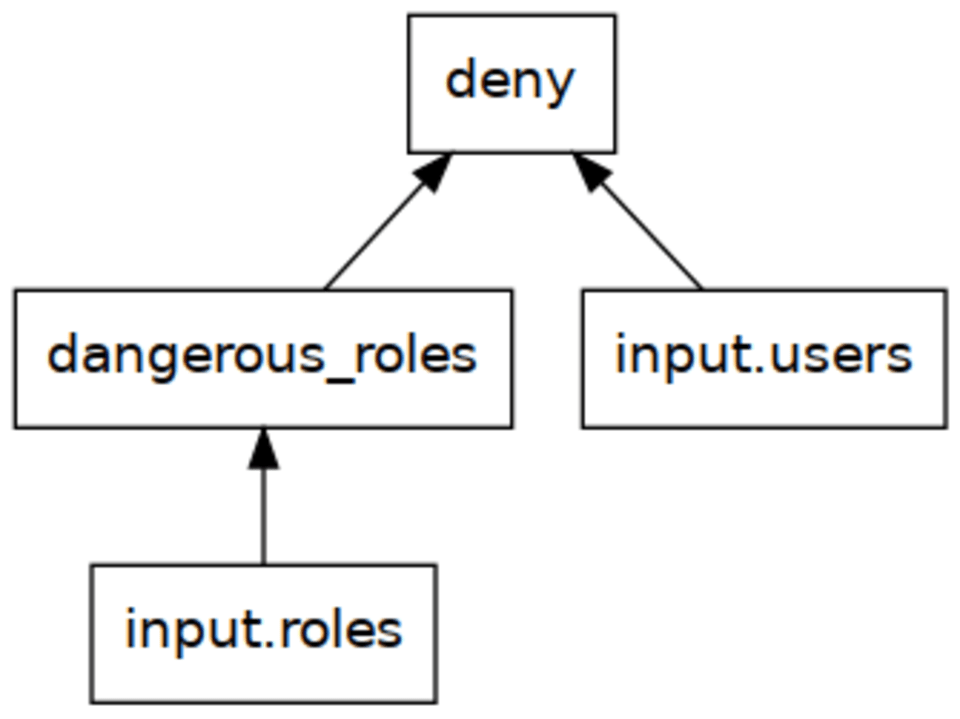
deny depends on dangerous_roles, and both depend on the input document. A bottom-up strategy will start evaluating this tree from the bottom and work its way to the top.
The input document does not need further evaluation. Above that is the dangerous_roles set: we start by computing this set. In our example, this will be the set {"temporary_hack"}.
Once we know dangerous_roles, all dependencies for the deny rule are known, so we continue evaluating that second set which turns into {"Please remove role temporary_hack from user bob"}.
A bottom-up strategy is simple to implement but has a major downside: it often computes too much! Suppose that rather than listing all deny messages we simply wanted to check if temporary_hack is a dangerous role. Using a bottom-up strategy, dangerous_roles["temporary_hack"] would compute the whole (potentially big) set rather than halting once it figures that temporary_hack is indeed in the set.
A top-down strategy addresses this problem.
Top-down
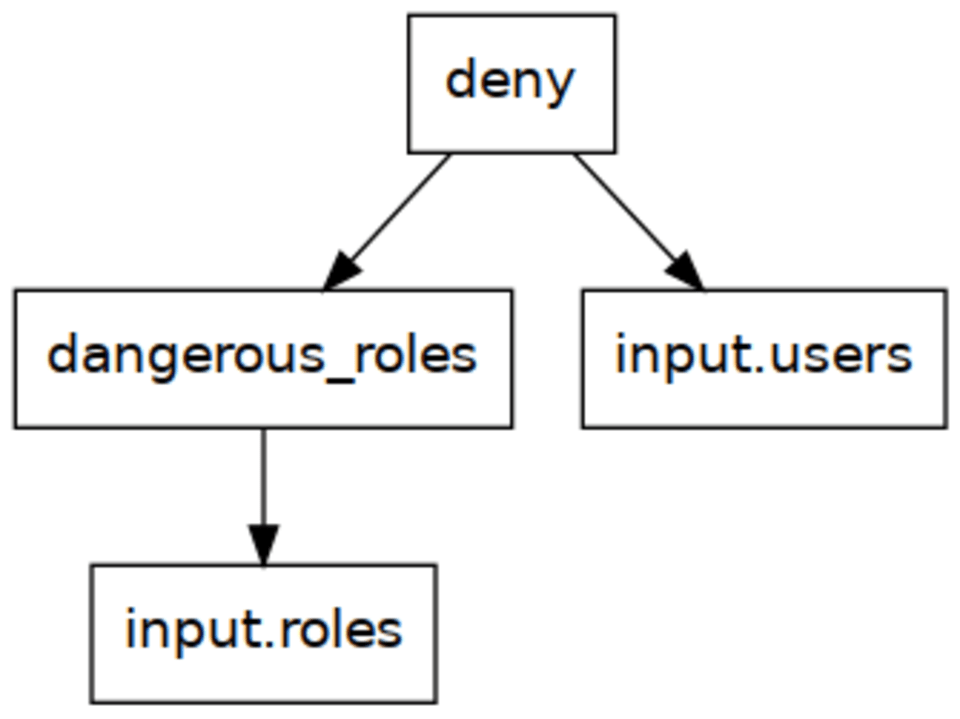
top-down strategy works the other way around, by evaluating the rules as needed starting from the top. This is pretty much the same as calling functions in most languages.
We start by evaluating deny, since that is the requested value. This rule loops over the users, assigns something to role_name, and then calls dangerous_roles[role_name]. Using the function analogy, you can think of this as dangerous_roles(role_name).
dangerous_roles calls no further “functions” but instead loops over the policies in the input document.
We can see this will give us the desired behavior for evaluating dangerous_roles["temporary_hack"]: rather than constructing a set, this now loops through the policies in the input and returns when the dangerous role is found that matches that name.
OPA uses a top-down strategy for evaluating Rego.
Accidentally Quadratic
But this top-down approach is not without its downsides! In pseudo-code, the bottom-up evaluation will internally do two loops:
# Evaluating dangerous_roles...
for role in input.roles:
...
# Evaluating deny...
for user in input.users:
for role_name in user.roles: # We can assume this is small?
...This is different from the top-down evaluation. If we think of dangerous_roles as a function call again, we get:
def dangerous_role(role_name):
for role in input.roles:
...
# Evaluating deny...
for user in input.users:
for role_name in user.roles: # We can still assume `user.roles` is small
dangerous_role(role_name) # But this is another nested loop!
...This looks suspiciously like something with quadratic running time!
And indeed, if we generate an input with 1000 users and 1000 policies, opa takes 3.47 seconds to evaluate that. If we bump that number to 10000, we are at just over 4 minutes!
This may sound like a contrived example – but it’s analogous to a real-life issue we’ve encountered at Fugue! We analyze large numbers of resources for compliance, so these evaluations can add up.
Top-down and bottom-up
Is that it? Are we stuck with slow queries? Fortunately not!
There is an easy workaround: if we know that we want to evaluate a rule “all at once”, we can do so by using a set comprehension. This way, dangerous_roles becomes a complete rule with a single value.
Syntactically, it looks like this:
dangerous_roles :=
{
role_name | role := input.roles[_]
role_name := role.name
role.write == "*"
}With this one simple trick (query analysts hate it), we’re at below 0.4 seconds for 10000 users!
Conclusion
A declarative language makes it easy to focus on what you want to compute rather than how you want to do it. However, we can’t completely forget about the actual execution model, especially when it may blow up the runtime and cause timeouts!
Fortunately, the fix is easy and quick. And when you’re writing Rego rules, it’s good to ask yourself whether a rule should be represented as a function or a compute-once set, and use a comprehension or an incremental rule accordingly.
In this blog post we talked about sets exclusively, but the same applies to objects.
An obvious question we haven’t answered yet is whether or not this can be fixed without us having to change the code – in true declarative fashion.
Caching the results of calls into dangerous_roles[role] sounds like an interesting direction, and it’s what I explored first. However, if we want to avoid recomputation, doing this requires caching the items in the set as well as the items not in the set. This is a problem since the latter may not fit in memory; and in either case some LRU eviction is needed which complicates the code.
It’s always not possible for a compiler to just tell if an arbitrary rule is better computed bottom-up or top-down. However, we can’t let that stop us from trying. I prototyped an optimization pass in fregot, our experimental Rego engine that identifies rules as candidates for bottom-up evaluation by looking at assignment patterns and testing if the argument may be used for short-circuiting evaluation. It identified all the cases that we had timing out so it’s a promising direction!
Sécurité IaC conçue pour les développeurs
Snyk assure la sécurité de votre infrastructure en tant que code du cycle du développement logiciel à son exécution dans le cloud avec un moteur de politique en tant que code unifié pour permettre à chaque équipe de développer, déployer et faire fonctionner les solutions en toute sécurité dans le cloud.